はじめに
こんにちは。Ryuです。
DeepSeekが世間を騒がせているのと時を同じくして以下の記事が話題になっていました。
こちらはHugging Faceのテックブログで、Transformerを用いない埋め込み計算によってTransformerの400倍早いモデルを学習する方法が紹介されています。
また、同モデルは下流タスクでTransformerを用いるモデルに対して、それに勝る性能や1, 2%の性能低下にとどまっているという実験結果が得られたそうです。
今回はそんな学習手法を紹介するとともに、@hotchpotch氏が公開している日本語版のモデルを使って推論してみる簡単な実験を行おうと思います。
現在の埋め込み
現在よく使われている埋め込みは以下のような手順で計算されています。
Tokenizerを利用して入力テキストをトークンと呼ばれる単位に分割し、Encoderと呼ばれるモデルによって埋め込みを計算します。
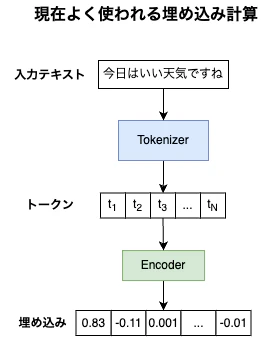
Encoderには一般にTransformerを中心としたAttention Layer付きモデルが用いられます。
Attentionは文章全体を考慮して各トークンの埋め込みを計算するため、文脈を考慮したタスクに有効です。
Transformerで用いられるAttentionについては以下の記事が分かりやすいので、あまりピンとこない方はぜひご覧ください。
文脈を考慮して埋め込みが計算できるためBERTやGPTなど言語モデルの中でAttentionは活用されています。
そんな素晴らしいAttentionですが、計算コストが高いという欠点があります。(コストを下げる手法も存在するが、今回は割愛)
文脈を考慮する都合上、学習時だけでなく推論時でも文章全体に対する複雑で重たい計算が行われ、文章毎にトークンの埋め込みが変化します。
そのため、システムによってはメモリやレイテンシを考慮してAttention付きの言語モデルは採用されないケースも多いです。
静的埋め込み
前節で紹介したAttention付き言語モデルは文脈を考慮することから、推論時でも文章全体に対して複雑でコストの高い計算が必要ということでした。
Hugging Faceのテックブログでは、このように推論時でも動的に埋め込みが変化する埋め込みを動的埋め込み(Dynamic Embeding)と表現していました。
今回のメインはこの動的埋め込みに対を成す静的埋め込み(Static Embeding)です。
静的埋め込みはword2vecやGLoVeに代表される、事前に計算したモデルによって計算される埋め込みのことを指します。
トークン毎にあらかじめ埋め込みを計算し、その平均値などを文章全体の埋め込みとして扱います。
動的埋め込みモデルと静的埋め込みモデルの出力の例を示します。
動的埋め込み
「今日はいい天気ですね」と「明日はいい天気ですね」というテキストを入力した際に「天気」のトークン埋め込みは文脈が違うことから異なるものが出力されます。
静的埋め込み
一方で、静的埋め込みモデルでは事前に計算したトークン埋め込みを用いるため、文脈が異なっても同じ「天気」というトークンの埋め込みは同じものが出力されます。
もちろん文章全体の埋め込みは各トークン埋め込みの平均値をとるので、文章全体としては異なる埋め込みになります。
静的埋め込みはトークン埋め込みの計算時に文脈を考慮していないため、近年の分類や検索タスクなどでは動的埋め込みが用いられています。
そのような歴史の中でHugging FaceがAttentionを用いない静的埋め込みによって下流タスクで高い性能を出すモデルを提案してきたので、学習方法を見ていきましょう。
提案手法
提案手法はシンプルで、トークンIDを受け取る全結合層(Dense Layer)に対して以下の2種類の方法で損失を計算し、重みを学習しています。
- 対照学習(Contrastive Learning)
- マトリョーシカ表現学習(Matryoshka Representation Learning)
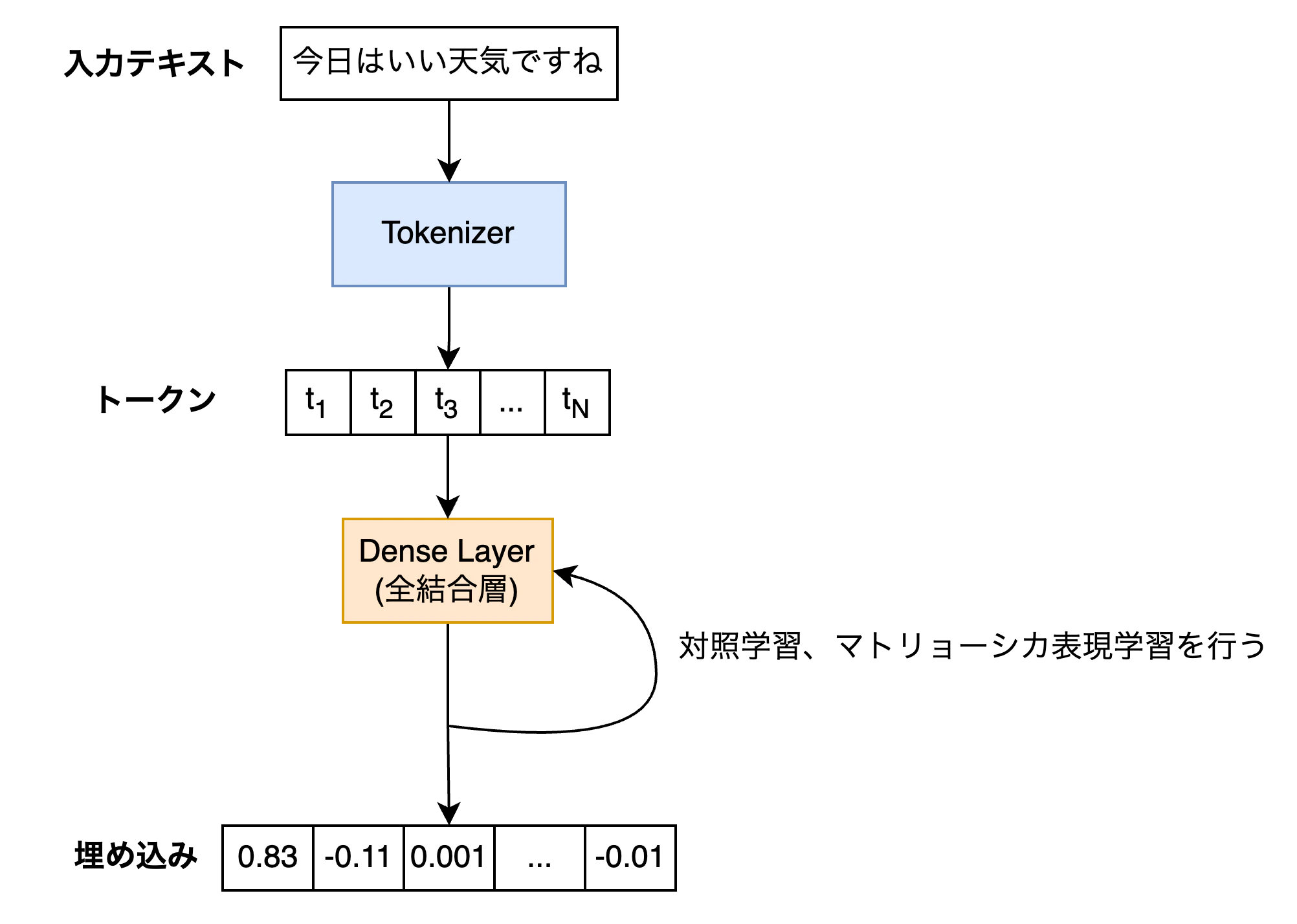
各損失の計算方法について簡単に説明していきます。
対照学習(Contrastive Learning)
対照学習は似た性質を持つもの同士の埋め込みを近づけ、異なる性質をもつもの同士の埋め込みを遠ざけるように学習する表現学習の一種です。
対照学習は埋め込みの類似度等を用いる下流タスクを想定して事前学習時に行われる印象がありますね。
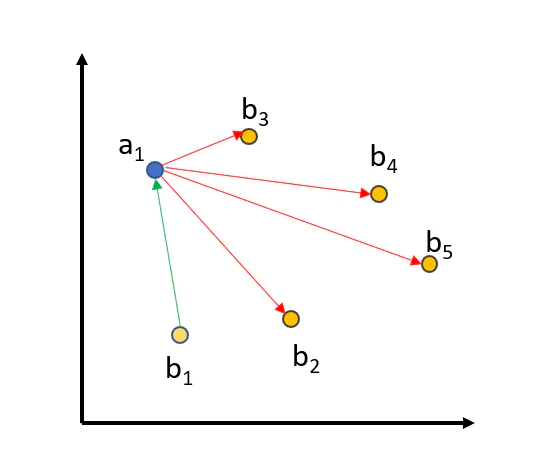
今回は対照学習の中でも Multiple Negatives Ranking Loss(MNRL) という手法が用いられています。
MNRLはバッチ内で異なるラベルを持つデータを全て負例とするため、バッチサイズが大きいほどタスクが困難になり、モデルはより頑健になります。
( ターゲット$a_1$ に対して正例として$b_1$、負例として$b_2 ~ b_5$が存在することを表した図)
マトリョーシカ表現学習(Matryoshka Representation Learning)
マトリョーシカ表現学習はOpen-AIが提供するEmbedding APIでも利用されている手法で、一つのモデルで複数次元の埋め込みを計算する事ができます。
通常、1024次元の埋め込みを出力するように学習したモデルは1024次元以外の埋め込みを適切に計算することは難しいです。
計算自体は可能ですが、1024次元の埋め込みに最適化して学習しているので、これをいたずらに512次元などに減らすとトークンの意味を上手く表せなくなってしまう恐れがあります。
そこで、マトリョーシカ表現学習では埋め込みの最大値に対して、その一部のみを使った学習もしておくことで次元数を小さくした場合でもトークン埋め込みが下流タスクで機能するように工夫します。
例えば1024次元を最大値として埋め込みモデルを作成するとしたら、512, 256, 128次元などでも学習を行うことで、推論時に128, 256, 512, 1024次元まで自由に次元数を変更する事ができます。
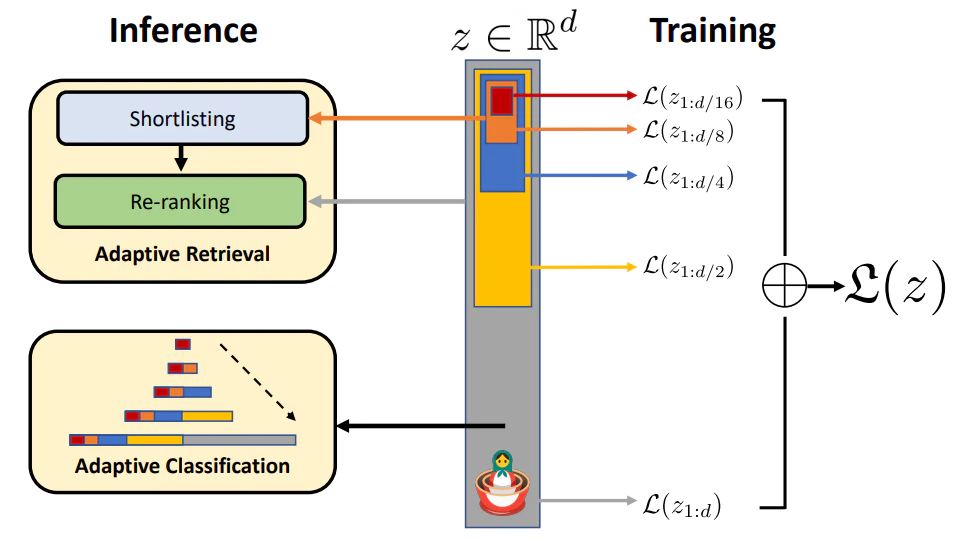
マトリョーシカ表現学習の詳細についは以下の資料が大変わかりやすいので、気になる方は目を通してみてください。
hotchpotch/static-embedding-japaneseを使ってみる
提案手法の説明ができたところで、提案手法を利用して日本語データセットで学習されたhotchpotch/static-embedding-japaneseモデルを使って簡単に実験をしてみましょう。
ベンチマーク結果はすでにモデルを作成した方のブログ記事にあるので、ここでは処理時間の確認といくつか簡単な実験をしてみます。
処理時間の計測
hotchpotch/static-embedding-japaneseモデルの公開ページには以下のようなサンプルコードがあるため、これを使って各言語モデルと処理時間の比較をしてみます。
from sentence_transformers import SentenceTransformer
model_name = "hotchpotch/static-embedding-japanese" # ←ここを置き換える
model = SentenceTransformer(model_name, device="cpu")
query = "美味しいラーメン屋に行きたい"
docs = [
"素敵なカフェが近所にあるよ。落ち着いた雰囲気でゆっくりできるし、窓際の席からは公園の景色も見えるんだ。",
"新鮮な魚介を提供する店です。地元の漁師から直接仕入れているので鮮度は抜群ですし、料理人の腕も確かです。",
"あそこは行きにくいけど、隠れた豚骨の名店だよ。スープが最高だし、麺の硬さも好み。",
"おすすめの中華そばの店を教えてあげる。とりわけチャーシューが手作りで柔らかくてジューシーなんだ。",
]
embeddings = model.encode([query] + docs)
print(embeddings.shape)
similarities = model.similarity(embeddings[0], embeddings[1:])
for i, similarity in enumerate(similarities[0].tolist()):
print(f"{similarity:.04f}: {docs[i]}")
サンプルコードの文章だけだとそこまで処理時間に変化はなかったため、1200文ほどChatGPTに似たような文章を生成させ、処理時間を競わせます。
BERTモデルとしてtohoku-nlp/bert-base-japanese-whole-word-maskingとSentence-BERTモデルとしてsonoisa/sentence-bert-base-ja-mean-tokens-v2と比較をします。
それぞれの埋め込みは768次元で、hotchpotch/static-embedding-japaneseは32, 64, 128, 256, 512, 1024次元のみでマトリョーシカ学習をしているため公平な比較ではありませんが、今回は1024次元で比較します。
以下が実行結果で、CPUで実行しています。
| モデル | 処理時間(秒) |
|---|---|
| hotchpotch/static-embedding-japanese | 30ms |
| tohoku-nlp/bert-base-japanese-whole-word-masking | 120ms |
| sonoisa/sentence-bert-base-ja-mean-tokens-v2 | 180ms |
正確な比較ではないですがかなり早いのがわかりますね。
推論させてみる
それではサンプルコードにあったターゲット文「美味しいラーメン屋に行きたい」に対して各文章の類似度を計算してみます。
サンプルコードそのまま
- static-embedding-japanese
感覚的に近い類似度が出力できているのではないでしょうか。
カフェに関する1文目の類似度がかなり低くなっているのが良いですね。
ターゲット文:美味しいラーメン屋に行きたい
0.1040: 素敵なカフェが近所にあるよ。落ち着いた雰囲気でゆっくりできるし、窓際の席からは公園の景色も見えるんだ。
0.2521: 新鮮な魚介を提供する店です。地元の漁師から直接仕入れているので鮮度は抜群ですし、料理人の腕も確かです。
0.4835: あそこは行きにくいけど、隠れた豚骨の名店だよ。スープが最高だし、麺の硬さも好み。
0.3199: おすすめの中華そばの店を教えてあげる。とりわけチャーシューが手作りで柔らかくてジューシーなんだ。
- 日本語Sentence-BERT
こちらも感覚的に近い類似度になっていますね。
1文目の類似度がSentence-BERTのほうが高くなっていますが、相対的に最後の文章との差が大きいので十分類似度を測れているのではないでしょうか。
ターゲット文:美味しいラーメン屋に行きたい
0.3225: 素敵なカフェが近所にあるよ。落ち着いた雰囲気でゆっくりできるし、窓際の席からは公園の景色も見えるんだ。
0.3622: 新鮮な魚介を提供する店です。地元の漁師から直接仕入れているので鮮度は抜群ですし、料理人の腕も確かです。
0.4957: あそこは行きにくいけど、隠れた豚骨の名店だよ。スープが最高だし、麺の硬さも好み。
0.5702: おすすめの中華そばの店を教えてあげる。とりわけチャーシューが手作りで柔らかくてジューシーなんだ。
Static Embeddingが苦手そうな文章を使ってみる
Static Embeddingは事前計算したトークン埋め込みの平均値をその文章の埋め込みとしているため、同じ単語を使っている文同士が全く同じ埋め込みになります。
実際に例を見てみましょう。
- Static-Embedding-Japanese
以下の例では2文目が「綺麗なラーメン、美味しい盛りつけ」という文になっているため、感覚的には美味しいラーメン屋について言及している1文目の文章の類似度が高くなって欲しいですが、2文とも同じ類似度になっています。
このように文脈を考慮した推論ができないStatic Embeddingではトークンの順序が変わって文の意味が変わったとしても、正しく文章の意図を読み取ることができないのです。
ターゲット文:美味しいラーメン屋に行きたい
0.6849: 美味しいラーメン、綺麗な盛りつけ
0.6849: 綺麗なラーメン、美味しい盛りつけ
単語の順序を変えるだけでは必ずしもこのような結果が得られない点に注意してください。
今回はトークナイザーが各トークンに同じトークンIDを割り当てるような文章をわざと作成しているため、このような結果が得られています。文章の構造自体では割り振られるトークンIDが変化し、得られる埋め込みも変化します。
- 日本語Sentence-BERT
一方で推論時もAttentionによって動的にトークン埋め込みが変化するSentence-BERTでは、「美味しいラーメン」と言及している1文目の類似度が高くなっています。
感覚的にも正しそうですね。
これは「美味しい」が「ラーメン」にかかっているという係り受け関係をモデルが学習しており、文脈を考慮した推論ができているためであると考えられます。
ターゲット文:美味しいラーメン屋に行きたい
0.7346: 美味しいラーメン、綺麗な店内
0.7186: 綺麗なラーメン、美味しい店内
おわりに
現在の埋め込みモデルでは主流になっているAttentionほどの計算コストを払わずに高い性能を出せるのは魅力的ですね。
Transformer系のモデルはレイテンシの問題から、検索システムや広告など速度が求められるシステムでは導入が難しいため、このように軽量ながら性能が高いモデルの発展は開発を行うエンジニアからするとかなり嬉しいです。
一方でStatic Embeddingは同じ単語では同じ埋め込みしか得られず、それらの平均を文章全体の埋込みとしているため単語の共起しか見ていません。
しかし、事前計算した埋め込みを用いつつ文脈を考慮した文章全体の埋め込みが計算できる方法などが出てくればまた状況は変わってくるのかなと思うので、Static Embedingの今後が楽しみですね。