はじめに
(LTのネタになりそうで)業務では使わなさそうな面白いAWSサービスはないかと調べていたところ、カーレースシミュレーションを通じて強化学習を経験・学習できるAWS DeepRacerというサービスを見かけ、試しに触ってみたので、その内容についてアウトプットしていきたいと思います。
AWS DeepRacer とは
公式からは以下のような説明がされています。
あらゆるレベルレベルのデベロッパーが、クラウドベースの 3D レーシングシミュレーター、強化学習により駆動する 1/18 スケールの完全自走型レーシングカーを通じて機械学習を実践的に学べます。
一言でいうと、「強化学習を楽しく、実践的に学べるプラットフォーム」といったところでしょうか。
本サービスは、2025年12月で終了予定です。
試してみたい方はお早めに触ってみることをお勧めします。
余談ですが、AWS Summit2023や2024では実際に大会が行われていたそうなので、ご存知の方も多いかもしれません。
強化学習とは
強化学習は、人間や動物が「試行錯誤しながら学ぶ」という自然な学習プロセスに着想を得た機械学習の一種です。簡単に言えば、「行動して、結果を見て、より良い結果を得るために行動を調整する」という学習方法です。
基本要素
強化学習の基本要素は以下の5つです。
-
エージェント:学習し行動する主体
- AWS DeepRacerの場合:レーシングカー
-
環境:エージェントが相互作用する世界
- AWS DeepRacerの場合:レーストラック
-
状態:エージェントが現在置かれている環境の条件や状況を表現するもの
- AWS DeepRacerの場合:カメラから見えるトラックの様子や車の位置など
-
行動:エージェントが取る選択
- AWS DeepRacerの場合:速度や角度(向き)の調整
-
報酬:行動の結果として得られるフィードバック
- AWS DeepRacerの場合:報酬関数による評価(トラックを外れない など)
プロセス
強化学習は以下のサイクルで進められます。
- エージェントが環境の現在の状態を観察
- 何らかの行動を選択
- 環境が変化し、新しい状態になる
- エージェントは行動の結果として報酬を受け取る
- この情報を使って将来より良い行動を選べるよう学習
- 1〜5を繰り返す
他の機械学習と違い
主な機械学習との違いは以下の表のようになっています。
| 種類 | 学習方法 | 入力データ | フィードバック | 目的 |
|---|---|---|---|---|
| 教師あり学習 | 正解(ラベル)付きのデータセットを使って学習 | ラベル付きデータ | 予測と正解の差(誤差) | 入力から出力へのマッピングを学習 |
| 教師なし学習 | データの中からパターンを見つけ出す学習 | ラベルなしデータ | なし(自己組織化) | データの構造やパターンの発見 |
| 強化学習 | 環境との相互作用から試行錯誤で学習 | 環境の状態 | 行動に対する報酬 | 報酬を最大化する方策の獲得 |
実際に触ってみる
実際にマネコンから触ってみます。以下「よくある質問」からの引用の通り、DeepRacerは米国東部 (バージニア北部) リージョンのみで利用できます。
Q: AWS DeepRacer は、どの地理的リージョンで利用可能ですか?
AWS のお客様は、米国東部 (バージニア北部) リージョンから AWS DeepRacer シミュレーターにアクセスできます。
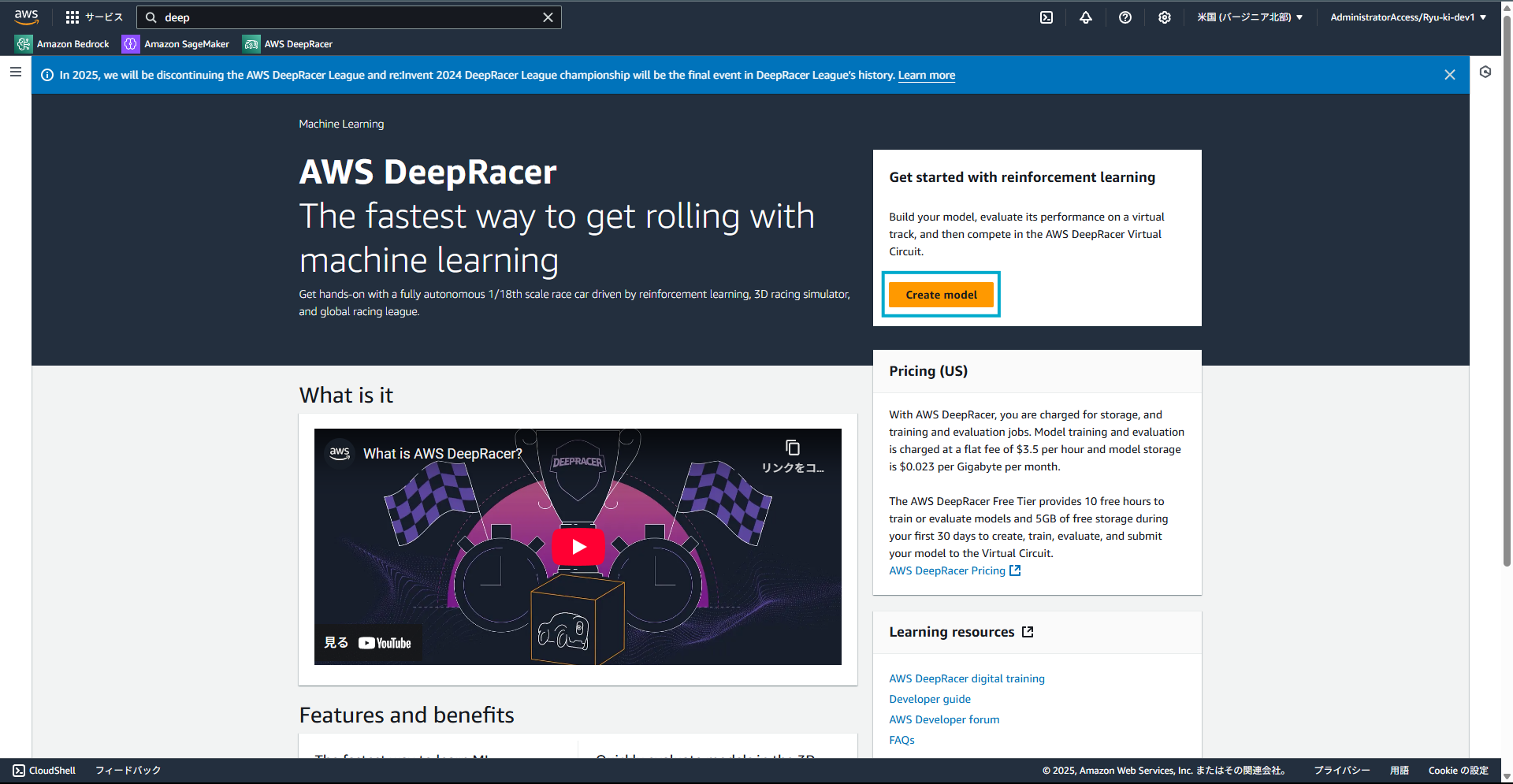
こちらがサービス初期画面です。Create modelを選択しモデルを作成していきます。
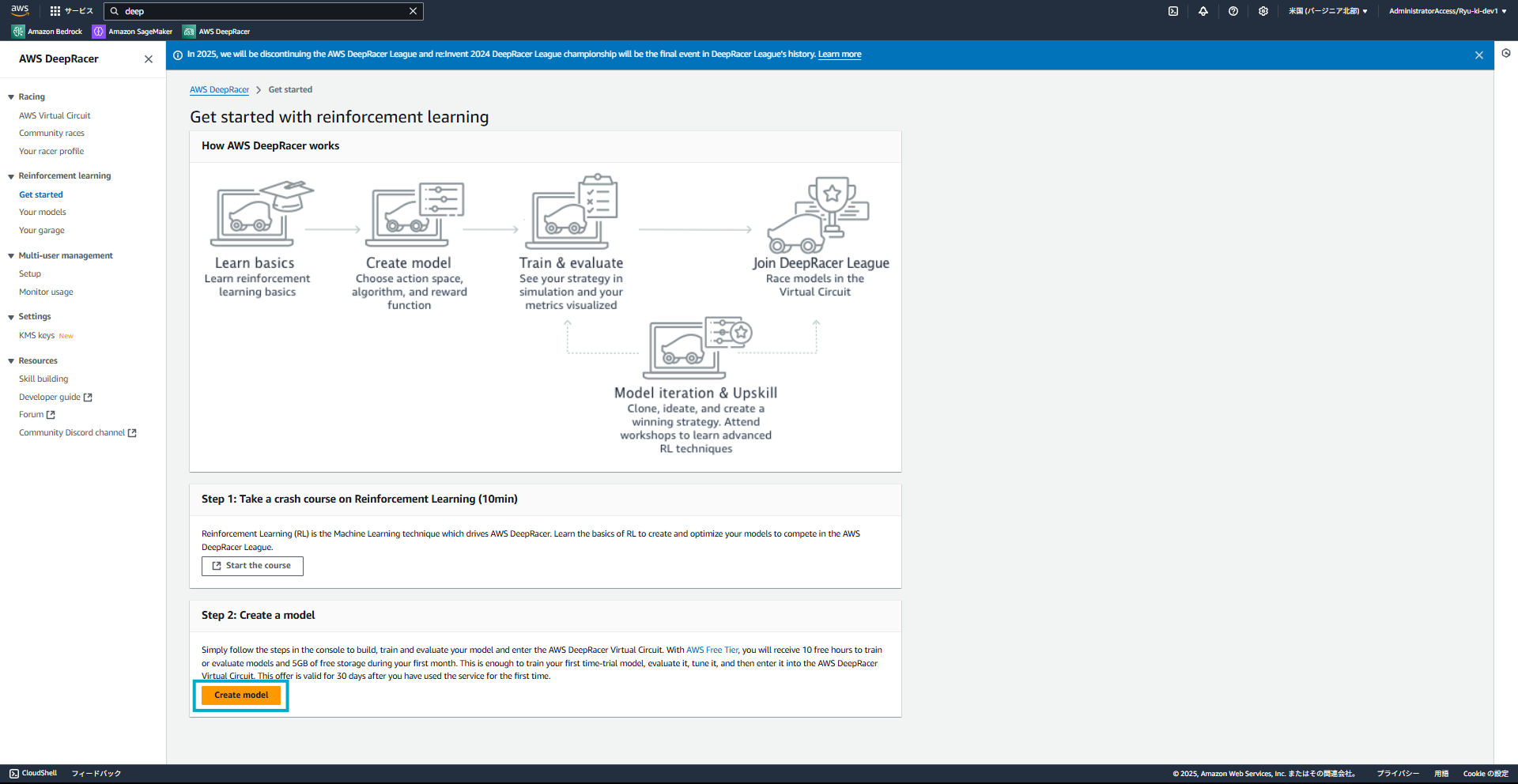
また、モデル作成前に強化学習に関する講座を受けることもできます。
本記事ではスキップします。
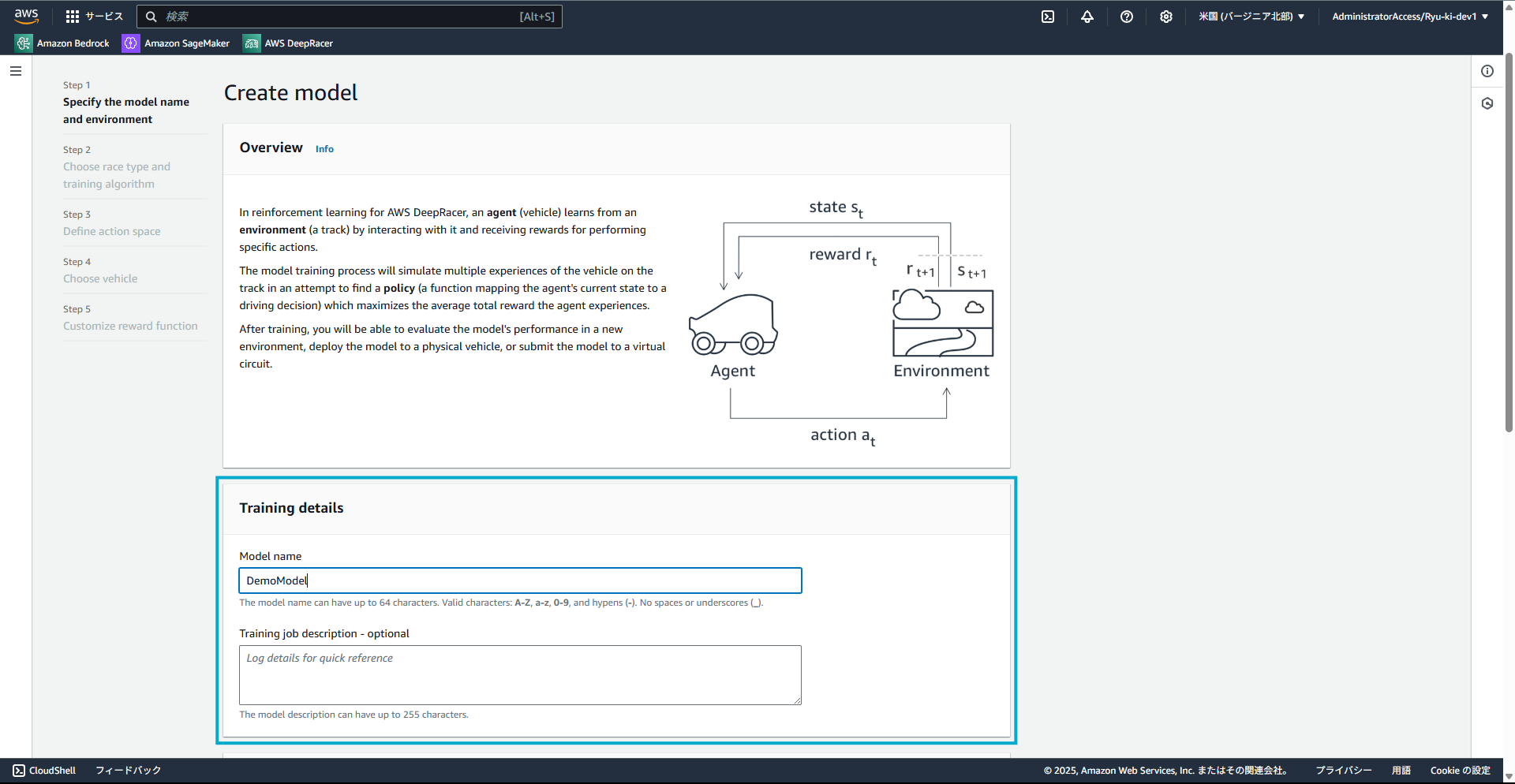
1. モデルの作成
モデル名や、その説明を入力し、モデルを作成していきます。
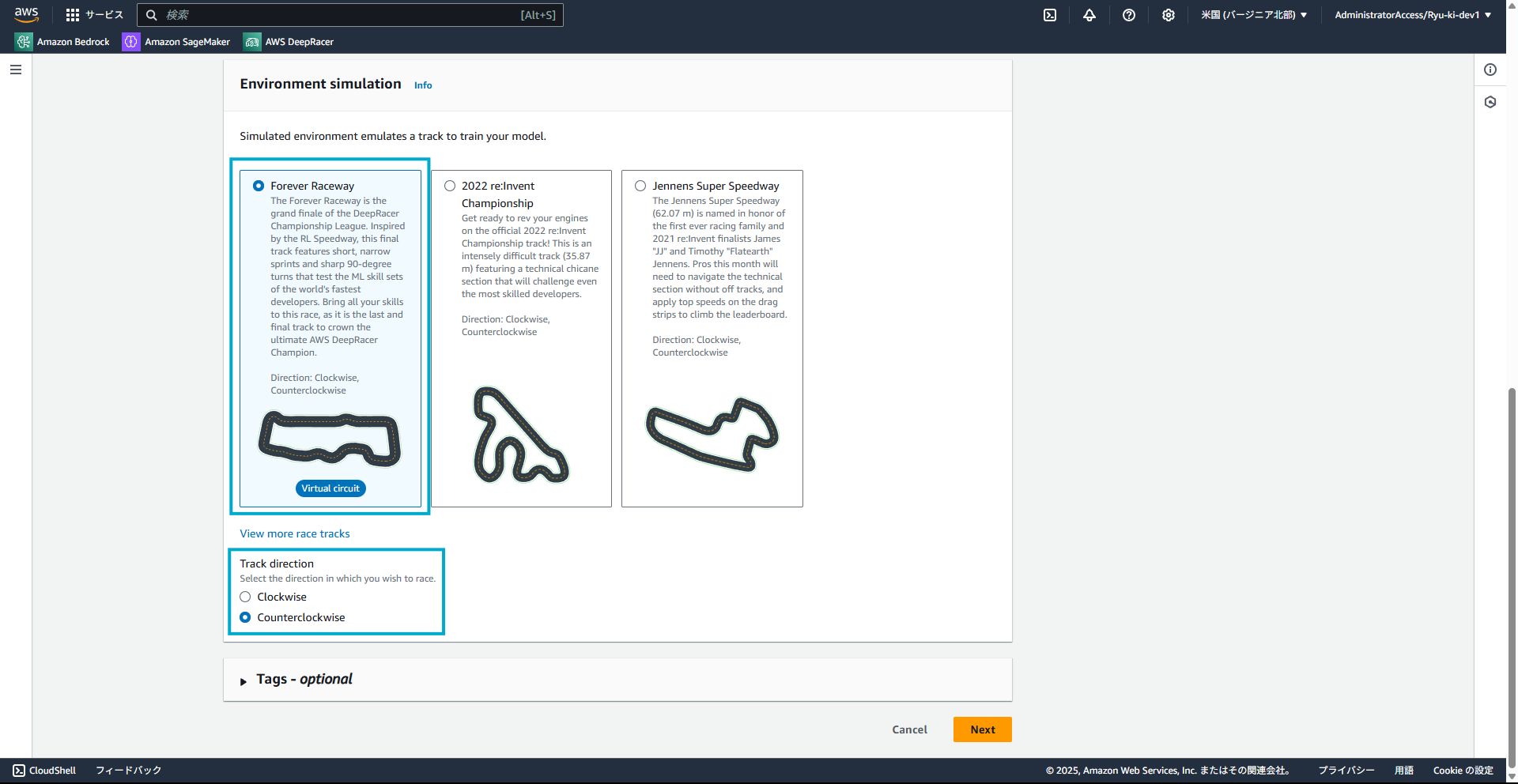
1-1. シミュレーション環境の設定
まず、走らせるコースの設定をします。今回はデフォルト設定にしておきます。
(ちなみに、View more race tracksをクリックすると30種類くらいコースがありました)
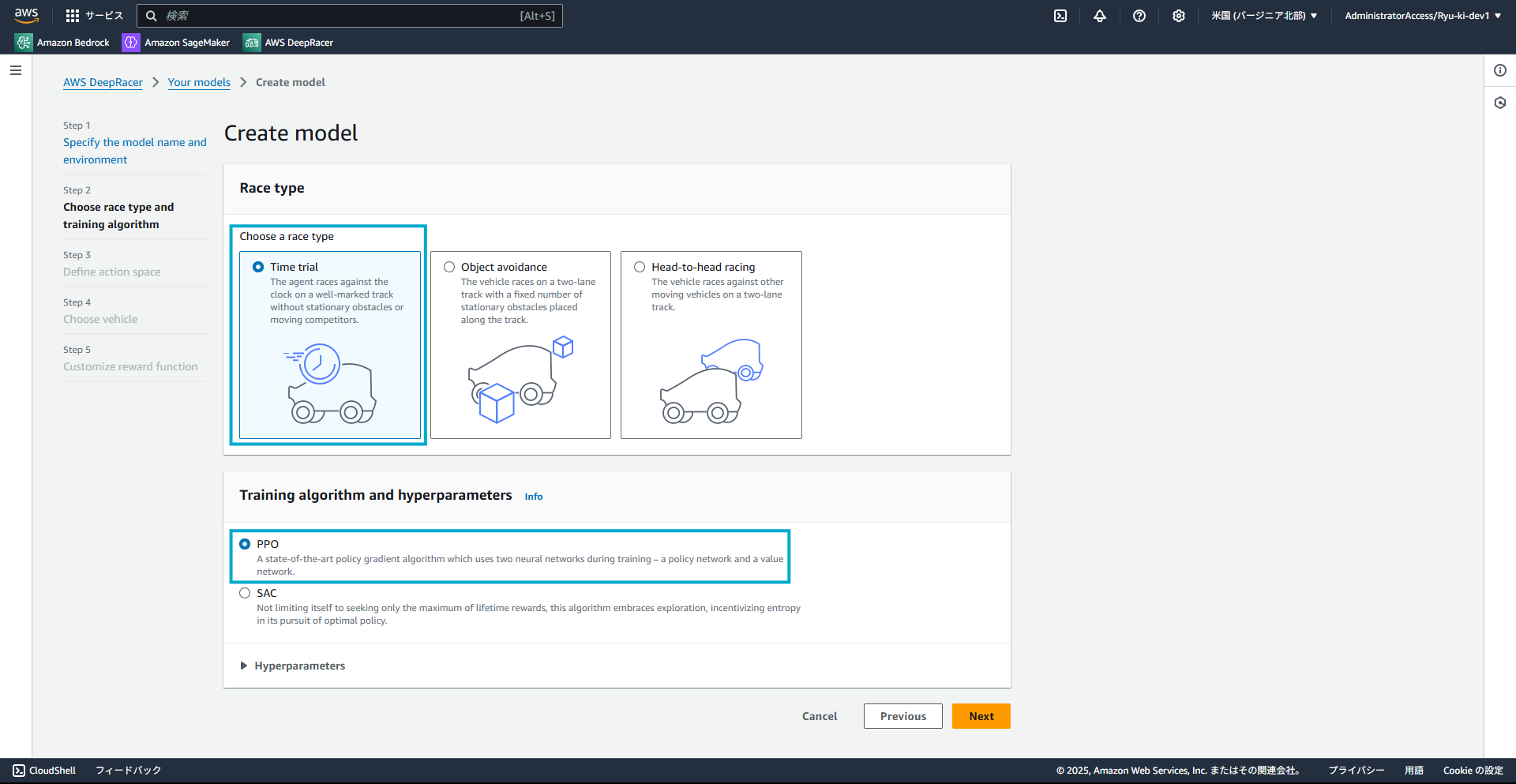
1-2. レースタイプとトレーニングアルゴリズムの設定
今回は、レースタイプはタイムトライアルを選択します。
トレーニングアルゴリズムの設定の前に簡単に説明します。
-
PRO(Proximal Policy Optimization)
- 2017年にOpenAIによって開発された強化学習のアルゴリズム
-
SAC(Soft Actor-Critic)
- 2018年にバークレー大学の研究者によって提案された強化学習のアルゴリズム
表にすると以下のように整理することができます。
| 特性 | PPO | SAC |
|---|---|---|
| 開発年 | 2017年(OpenAI) | 2018年(UC Berkeley) |
| 学習方式 | オンポリシー型 (現在の方針で得たデータのみで学習) |
オフポリシー型 (過去の経験も再利用して学習) |
| データ効率 | 中程度 | 高い(経験再利用あり) |
| 実装の複雑さ | 比較的簡単 | やや複雑 |
| 行動空間 | 離散・連続の両方に対応 | 主に連続行動空間に強い |
| ハイパーパラメータ | 比較的少ない | 調整が必要 |
| 計算効率 | 並列化に適している | やや計算コストが高い |
今回、トレーニングアルゴリズムはデフォルトであるPROを選択します。
1-3. アクションスペースの設定
設定の前に簡単にアクションスペースについて説明します。
Continuous action space(連続的アクションスペース)では、エージェントは無限に近い選択肢から細かく行動を選べます。行動は通常、ある範囲内の実数値で表現されます。
Discrete action space(離散的アクションスペース)では、エージェントが取れる行動は有限個の選択肢から選ばれます。こちらを選択した場合は、取れる行動をあらかじめ設定する必要があります。
アクションスペースについてはいったんよしなにやってもらいたいと思うので、今回は、Continuous action spaceを選択します。
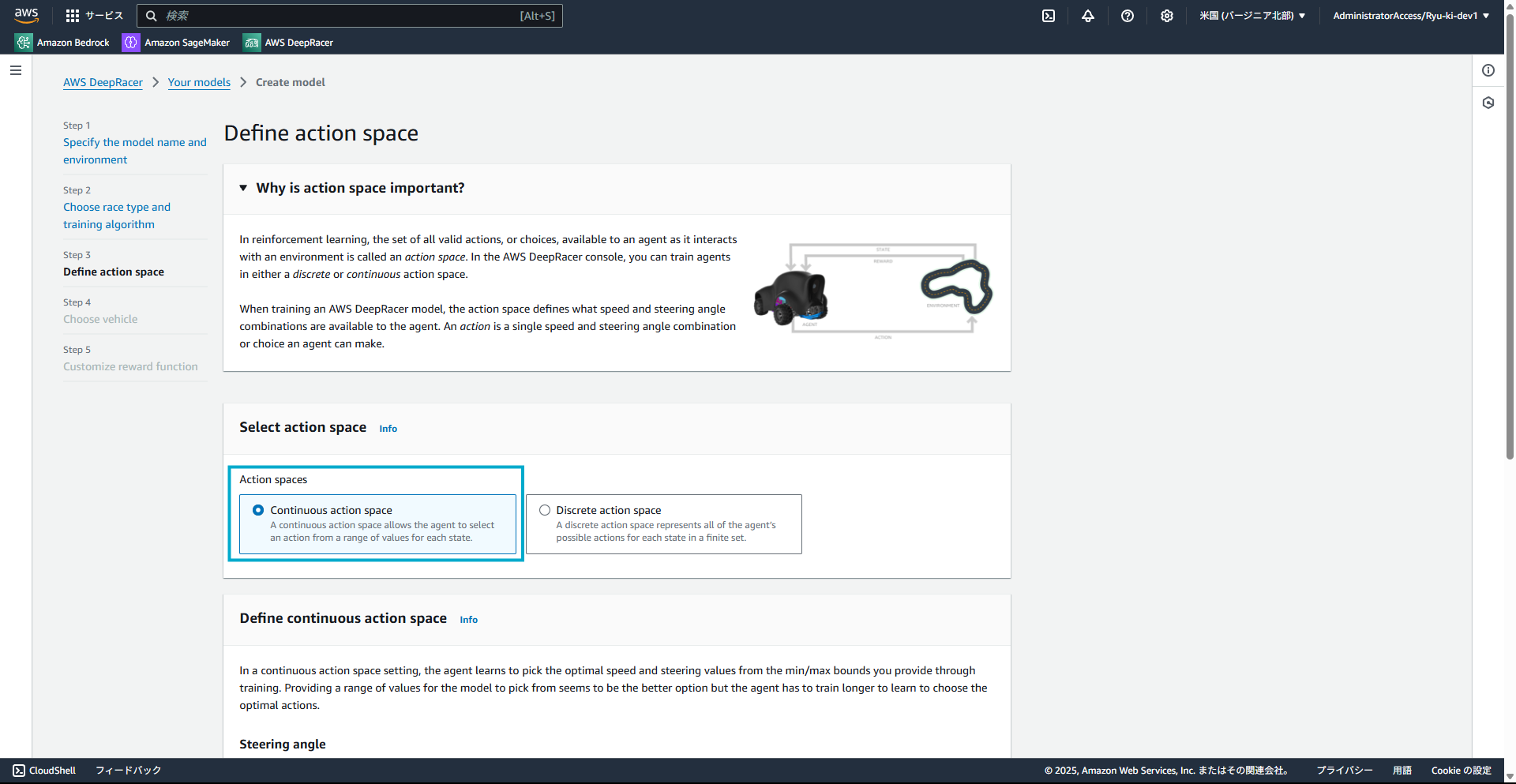
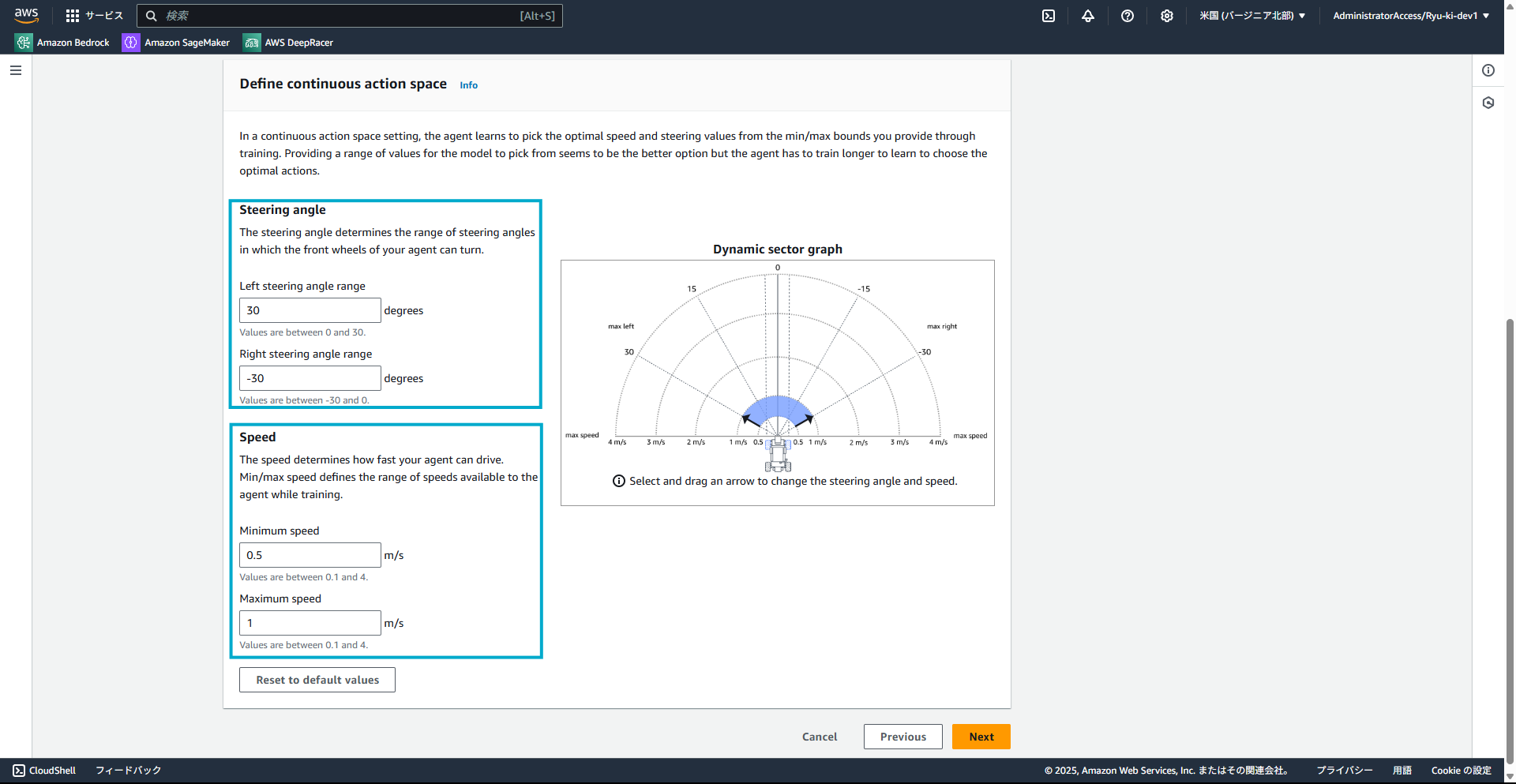
Continuous action spaceの詳細設定はデフォルトにしています。
実際は、Steering angle(前輪の角度)やSpeed(最高速度・最低速度)を細かく設定することができます。
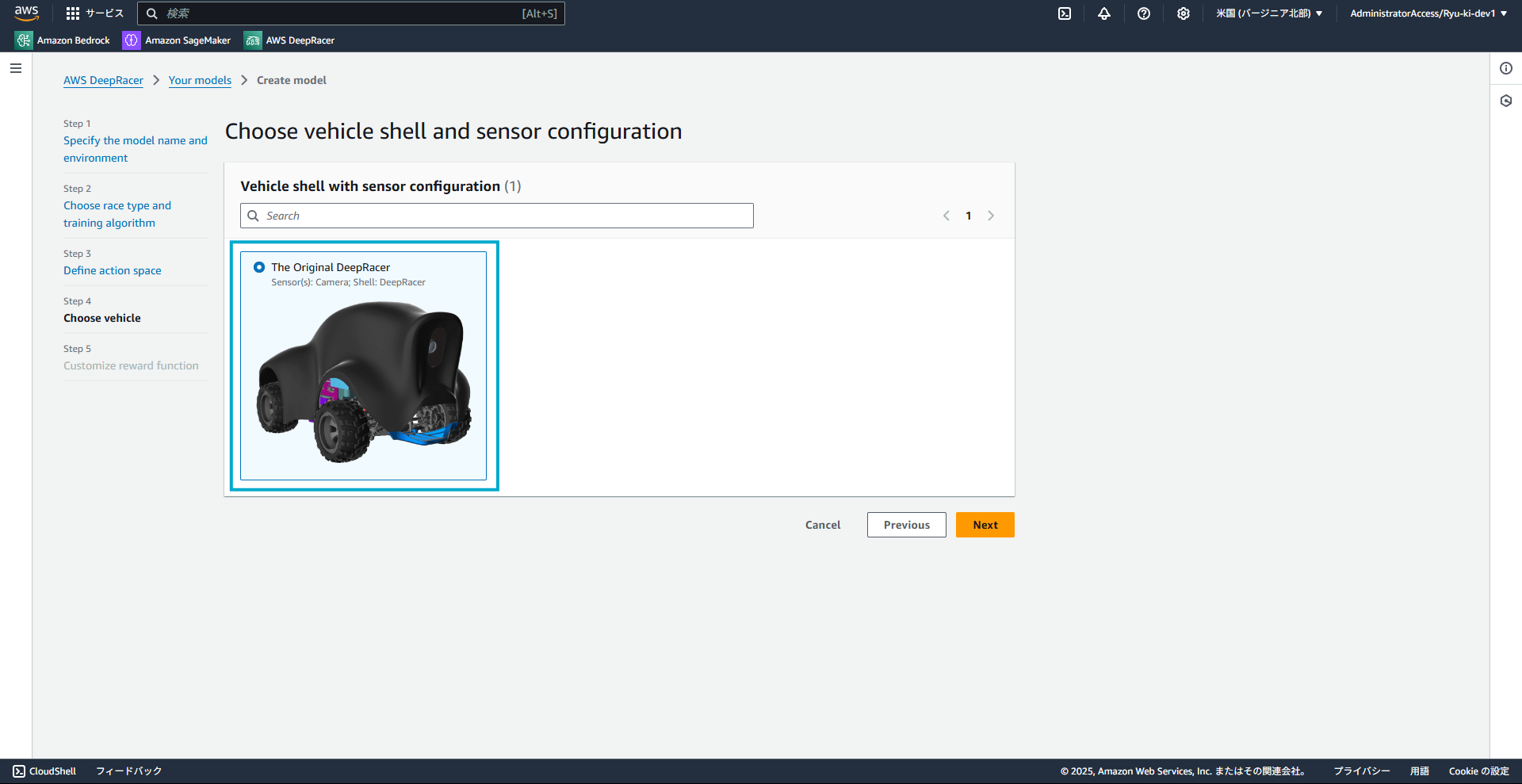
1-4. マシンの設定
現在は1種類しかないようです。
1-5. 報酬関数の設定
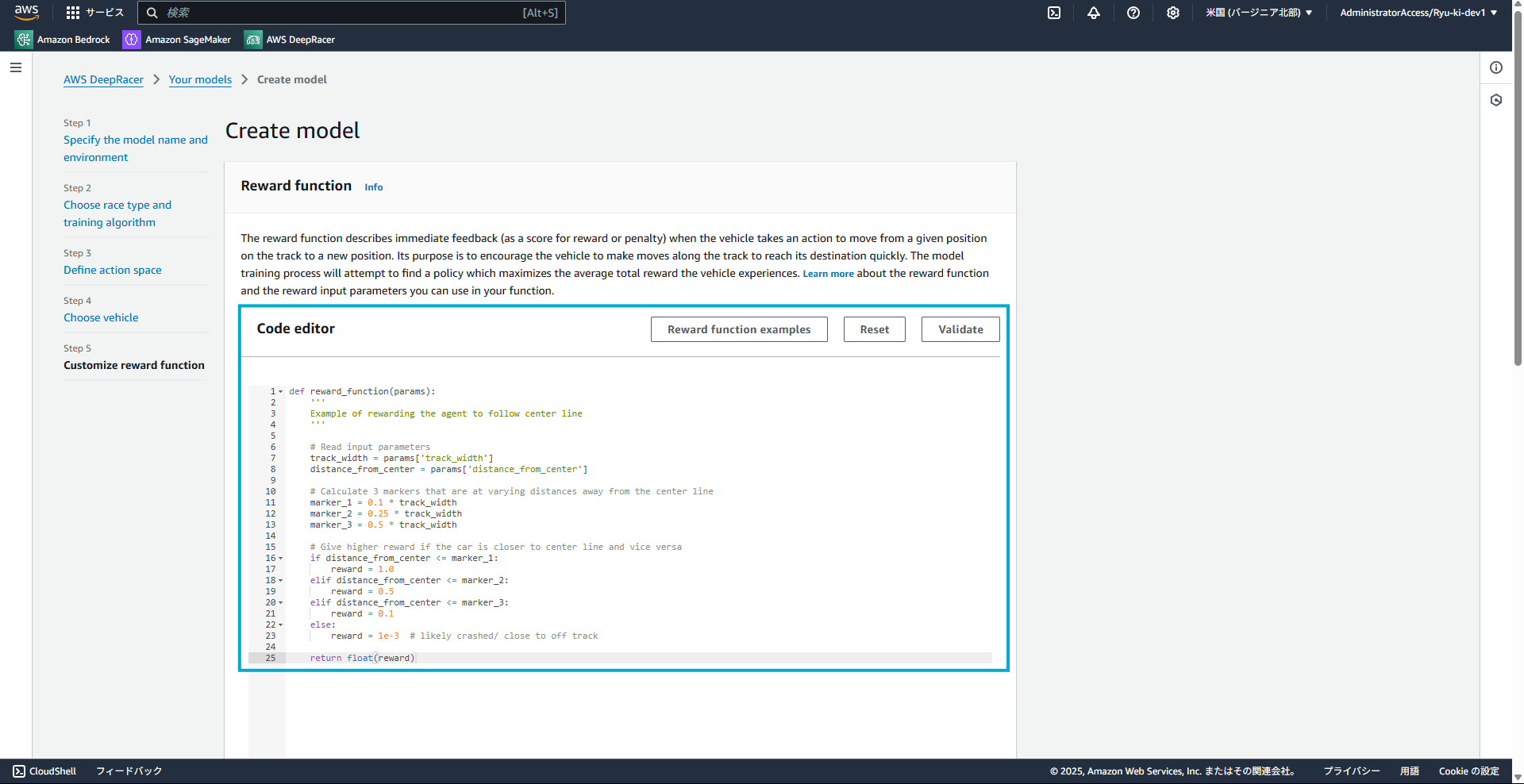
デフォルトでは以下のような実装がされています。
簡単に説明すると、車体がコースの中央から逸れるほど報酬が少なくなるような記述がされています。
(今回は車体の位置だけですが、車体の角度や、車体の速さなどの要素も報酬に含めることができます)
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
return float(reward)
1-6. トレーニング時間の設定
最後に、トレーニングの停止条件と、モデルのレース参加の設定をします。
今回はお試しなのでいったん5分で設定します。
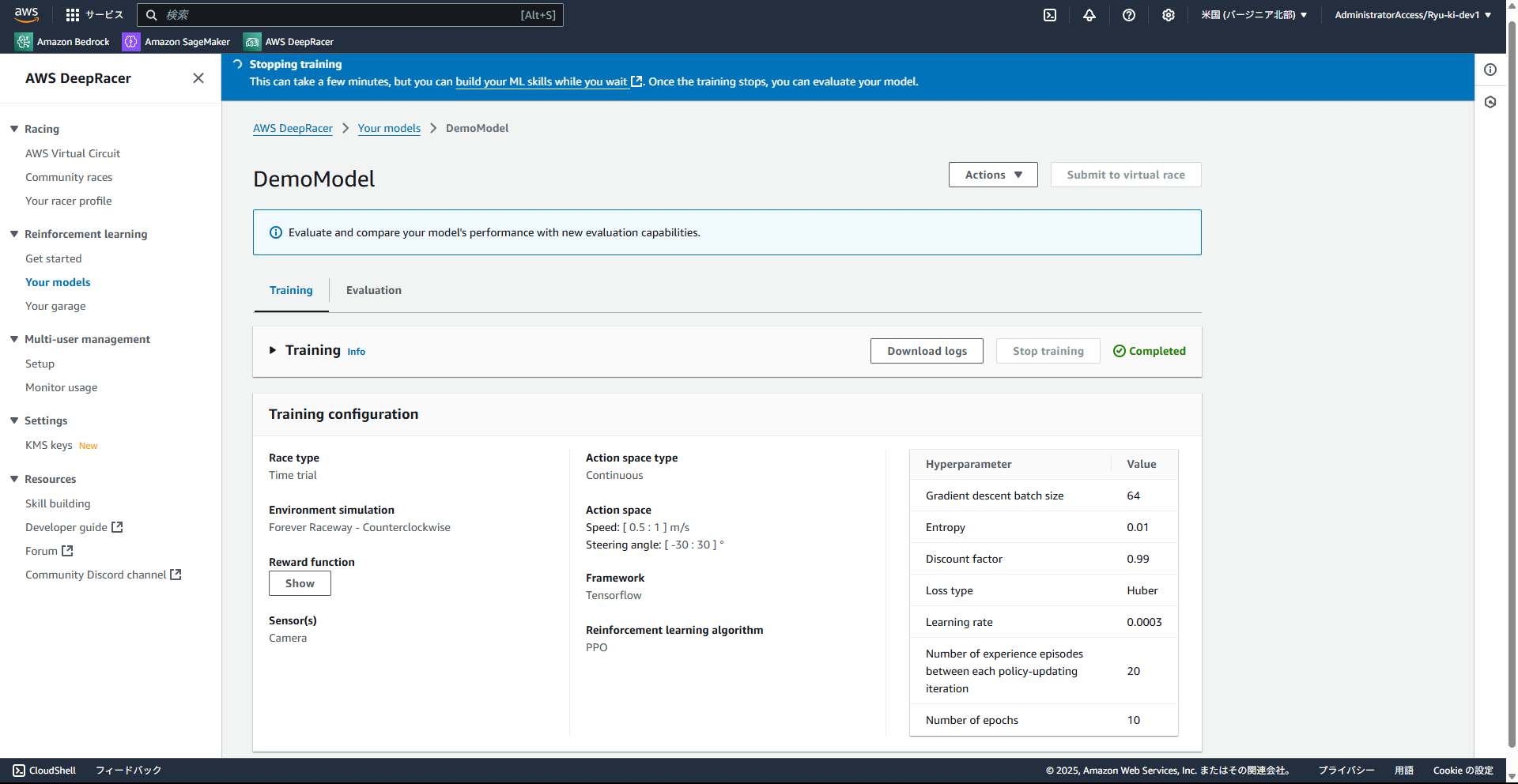
2. モデルのトレーニング
モデルの作成ができればトレーニングを実施します。
3. モデルの評価
トレーニングが完了できれば、評価を行います。
評価は実際にコースを3周走らせ、そのタイムを計測します。
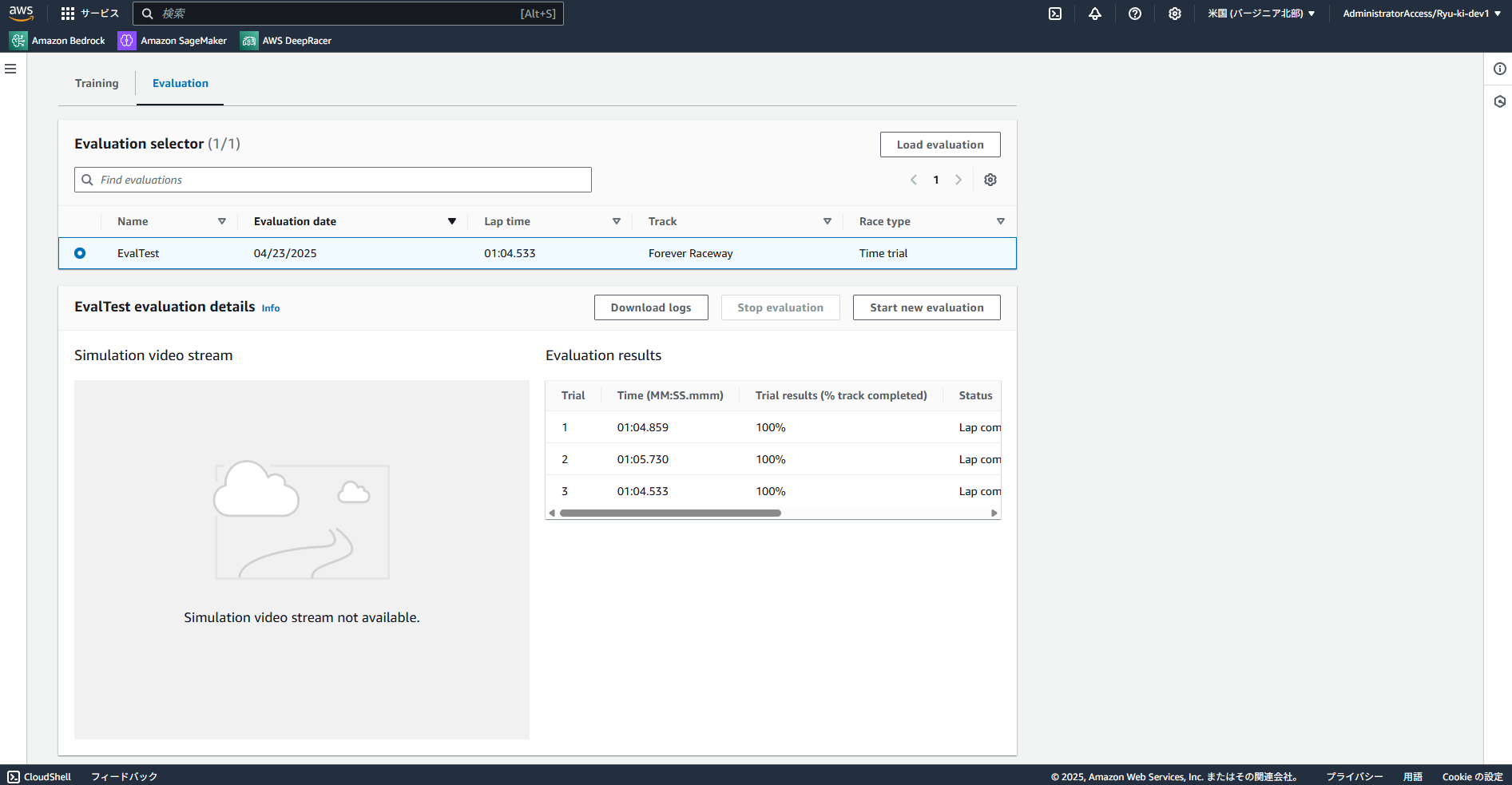
このような形でどのように走行しているか確認することができます。
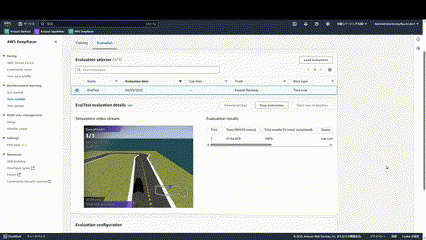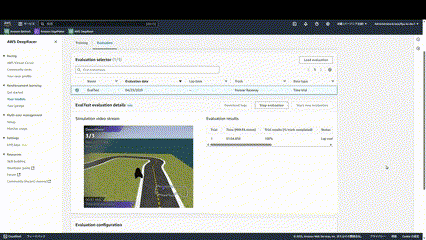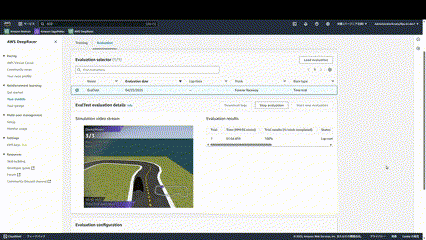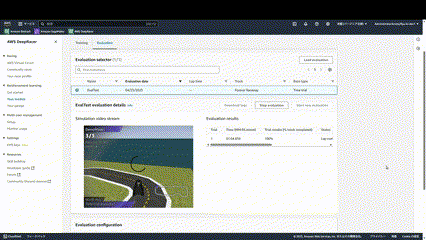
ほぼ学習できていないので、大きくコースアウトしてしまっていることがわかります。
ここから、パラメータや報酬関数を修正してどんどんタイムを改善していく流れになります。
4. モデルの改善(今回は未実施)
モデルの評価結果を踏まえて、モデルの改善を試みていきます。ハイパーパラメータや報酬関数を改良し、よりよいモデルを目指します。今回は未実施です。
おわりに
今回はAWS DeepRacerを触ってみました。レーシングカーでのトラック走行を題材としており、強化学習に入門するにはよいコンテンツだと感じました。わかりやすく、しかも簡単に始めることができるので興味のある方はぜひ触ってみていただきたいです。
余裕があればもう少し報酬関数をいじってみてその結果を整理できればと思います。
ありがとうございました。