はじめまして。ryuと申します![]()
Aidemyさんのデータ分析コースを受講したので、そこで学んだ内容を使ってデータ分析をしてみたいと思います!
お題は趣味でやっている株式投資を絡めて、株価の分析を行おうと思います。
今回はニューラルネットワークの手法の一つであるLSTM(Long short term memory)を用います。
LTSMについての解説は[こちら][link-1]が参考になります。
[link-1]:https://tips-memo.com/python-lstm
構成
以下の記事構成でご紹介させていただきます。
1.分析目標とデータ
2.結果
3.コード
4.所感
1. 分析目標とデータ
私自身が個別株の投資をやっているので、とある銘柄の株価を予測します。
ある日付時点から10日後の値動きを予測するというモデルです。※今回の分析では12/14~12/28の区間を予測しております。
使用するデータは[株式投資メモ][link-2]さんからwebスクレイピングを使用して取得しております。
"調整後終値"の5年分の時系列データを取得し、pandasでCSV形式に変換してLSTMにより将来値を予測を行います。
[link-2]:https://kabuoji3.com/stock/
2. 結果
では次に結果のご紹介です。以下に予測結果と実際の値動きをグラフ化したものを表示します。
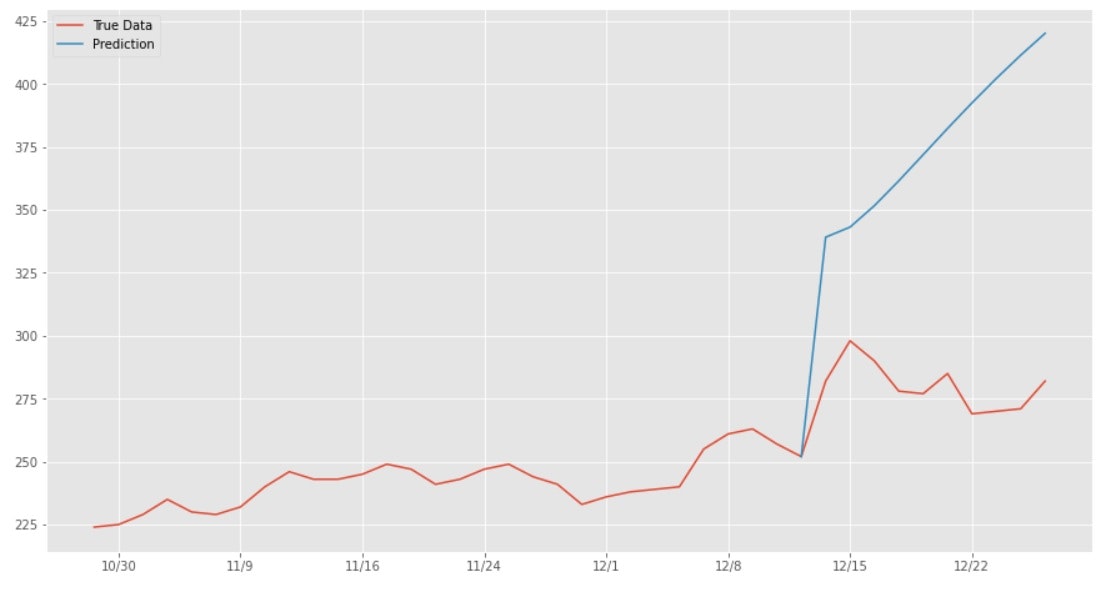
ご覧のような結果となりました。単純に終値だけを用いた予測では乖離が大きいようですね^^;
3. コード
今回の予測で使用したコードを以下に記載します。
3.1 必要なライブラリのインポート
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers.recurrent import LSTM
from sklearn.preprocessing import StandardScaler
plt.style.use("ggplot")
3.2 各関数の定義
3.2.1 時系列データを指定したwindow_sizeに区切る関数を作成
def apply_window(data,window_size):
sequence_lenght = window_size
window_data = []
for index in range(len(data) - window_size):
window = data[index: index + sequence_lenght]
window_data.append(window)
return np.array(window_data)
LSTMでは1つの時系列データを複数に分割し、それぞれのデータを基に学習します。
これはデータを分割する関数になります。
3.2.2 データの読み込みをする関数を作成
def data_load():
df_price_list = pd.read_csv("./stock_prices2.csv")
df_price_list["Date"] = pd.to_datetime(df_price_list["Date"])
df_price_list.sort_values(by="Date", inplace = True)
#調整後終値を抽出し、(X×1)の配列に変形
close_ts = df_price_list["調整後終値"]
close_ts = np.expand_dims(close_ts, 1)
return close_ts
3.2.3 訓練データとテストデータに分割する関数を作成
def split_train_test(data,train_rate=0.7):
#訓練データの割合と、元データの数をかける
row = round(train_rate * data.shape[0])
train = data[:row]
test = data[row:]
return train,test
学習に使用する訓練データと、検証に使用するテストデータに7:3の割合で分割します。
3.2.4 学習関数を作成
def train_model(X_train, y_train, units = 100):
#入力データの形式を取得
input_size = X_train.shape[1:]
#レイヤーを定義
model = Sequential()
model.add(LSTM(
input_shape=input_size,
units=units,
dropout = 0.3,
return_sequences=False))
model.add(Dense(units=1))
model.compile(loss="mse", optimizer="adam", metrics=["mean_squared_error"])
model.fit(X_train, y_train, epochs=15, validation_split=0.3, verbose=2, shuffle=False)
return model
入力層にはwindow_sizeで定義した数のデータが渡されます。
中間層は無し。出力層は予測の終値になるので1で設定。
3.2.5 予測関数を作成
def predict_ten_days(data,model):
#何日後を予測するか定義
prediction_len = 10
prediction_seqs = []
curr_frame = data.copy()
data_len = len(curr_frame.flatten())
predicted = []
for i in range(prediction_len):
pred = model.predict(curr_frame.flatten().reshape(1,-1,1), verbose = 0)
#予測結果を取得
prediction_seqs.append(pred[0,0])
#入力データを1つ削り、予測結果を次の入力データに利用
curr_frame = curr_frame[1:,:]
curr_frame = np.insert(curr_frame, data_len -1, pred[0,0], axis=0)
return prediction_seqs #予測結果を1次元arrayに変換
3.3 データ処理
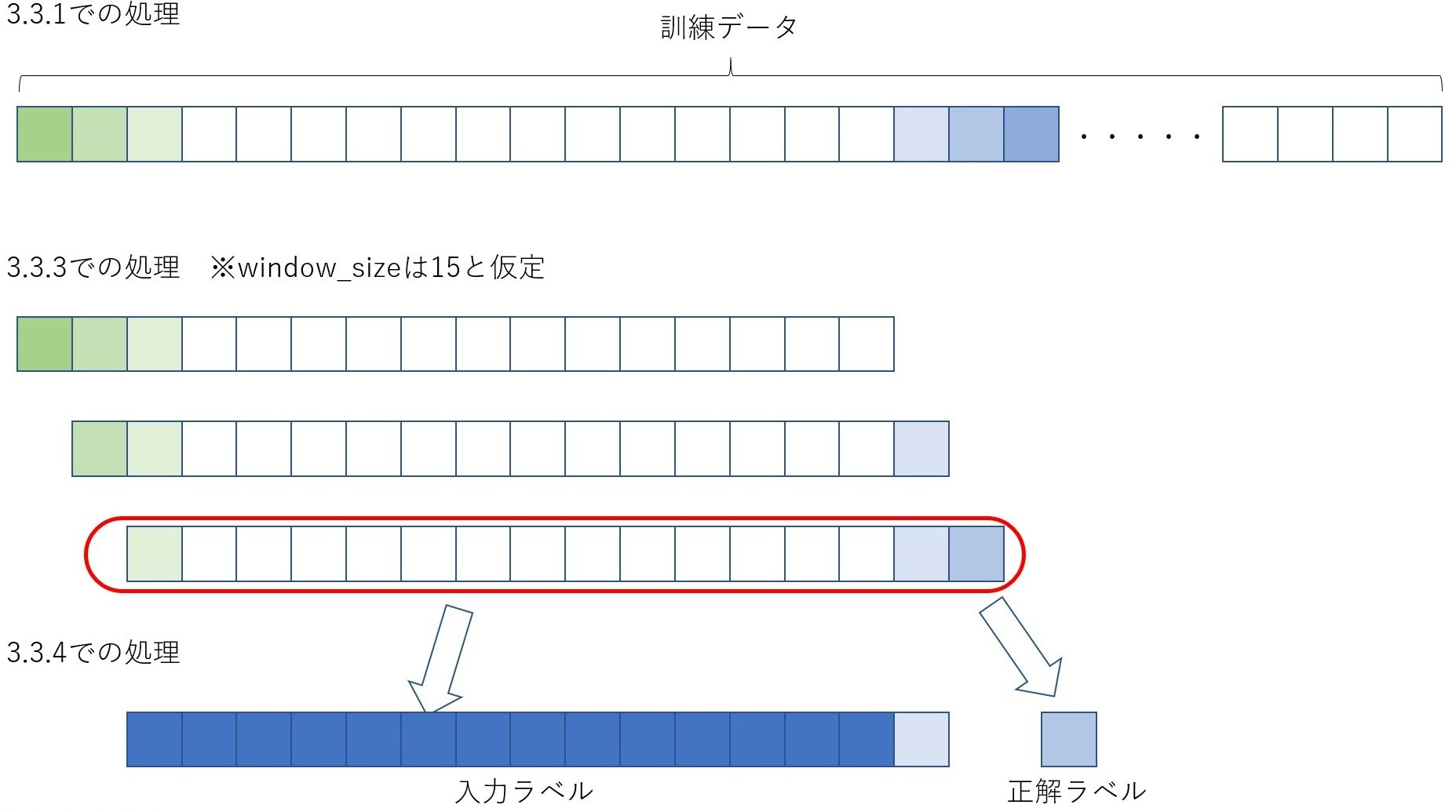
3.3.1 window_sizeで区切られた訓練データとテストデータを作成
window_size = 30
# data_load関数で株価の終値を取得
close_ts = data_load()
# データを訓練・学習データに分割
train, test = split_train_test(close_ts)
3.3.2 データの正規化
scaler = StandardScaler()
train = scaler.fit_transform(train) #訓練データを正規化
test = scaler.transform(test) #テストデータを訓練データに合わせて正規化(fitは使わない)
すべてのデータが平均0,分散1と一定の基準に収まるようにスケール調整を行い、大きな値によるモデルへの影響を低減します。
3.3.3 一定長さのデータを作成
train = apply_window(train, window_size + 1)
test = apply_window(test, window_size + 1)
上記で訓練データとテストデータを3.3.1で定義したwindow_sizeに分割します。
3.3.4 訓練用とテスト用の入力データと正解ラベルを定義
# 訓練用の入力データ
X_train = train[:,:-1]
# 訓練用の正解ラベル
y_train = train[:,-1]
# テスト用の入力データ
X_test = test[:,:-1]
# テスト用の正解ラベル
y_test = test[:,-1]
3.4 実行
3.4.1 学習モデルで学習
model = train_model(X_train, y_train, units=100)
3.4.2 予測モデルで予測
# テストデータをどの位置から予測データに使うか指定する
start_point = 324
prediction_seqs = predict_ten_days(X_test[start_point], model)
3.12 結果の可視化
# 結果の可視化
plt.figure(figsize=(15, 8))
plt.plot(range(start_point-window_size, start_point + 10), scaler.inverse_transform(y_test[start_point-window_size:start_point + 10]), label='True Data')
plt.plot(range(start_point - 1, start_point + 10), scaler.inverse_transform(np.insert(prediction_seqs, 0, y_test[start_point-1])), label='Prediction')
plt.xticks([295,300,305,310,315,320,325,330],["10/30","11/9","11/16","11/24","12/1","12/8","12/15","12/22"])
plt.legend()
plt.show()
こちらを実行すると2.項のグラフが出てきます
4.所感
今回は1つの変数による時系列データの予測を行いました。
やはり株価は様々な影響を受けて変化するものなので、終値だけの時系列解析では予測精度はそこまで高くできないようです![]()
なので次回は他の変数(指数、出来高、信用残高など)を組み込んだモデルを使って予測を行ってみようと思います!
最後までご覧にいただき、ありがとうございましたm(_ _)m