はじめに
深層学習(ディープラーニング)の勉強を始めたので、画像分類の入門編であるMNISTにCNN(畳み込みニューラルネットワーク)を用いて取り組んでみた。
Pythonの実行環境は色々あるが、環境構築の手間や使っているPCがだいぶおじいちゃんなこともあり、基本的にGoogle colabを使用している。
MNISTデータセット
MNIST(Modified National Institute of Standards and Technology database)とは、0~9の手書き数字の画像データセットのことで、画像分類の初心者向けチュートリアルでよく使われているデータセットのこと(Hello World的な)。データが綺麗に整形されていて、高い精度が出やすいという特徴があるらしい。データセットは6万枚の訓練データと1万枚のテストデータで構成され、中身の画像は8bitのグレースケールで、0~255のピクセル値で表される。サイズは幅28×高さ28
MNISTは公式HPやKaggleコンペ、scikit-learn/Keras/TensorFlow/PyTorchのような各ライブラリが提供する機能など、様々な方法で入手することができる。機械学習の勉強でsklearnを使っていたので、今回はそのままsklearnで読み込んだ。(sklearnはアップデートで読み込み方が変わっていたので、それは以前の記事にまとめました)
MNISTデータの読み方は様々な手法があり、ライブラリからだとノートブックを開くたびに読み込むことになるので(自分の場合1分くらい)、PCの挙動が重い人は公式HPやKaggleからダウンロードしてローカルに落としておくのもありだと思う。(ただ.gzという単一の画像データセットになっているので、ライブラリから読み込む方が楽なそう)
環境
google colaboratory
Python 3.7.13
Keras 2.8.0
実装
1.ライブラリをインポート
必要なライブラリを読み込む
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from keras.utils import np_utils
2.データの読み込み
次に、sklearn.datasetsからMNISTデータを読み込む。
一行に画像1枚あたりのデータ(28×28=784)が入ったものが70000個入っている。
mnist_X, mnist_y = fetch_openml("mnist_784", version=1, return_X_y=True)
X = mnist_X.astype("float32")
y = mnist_y.astype(int)
# 確認
X.shape, y.shape
# ((70000, 784), (70000,))
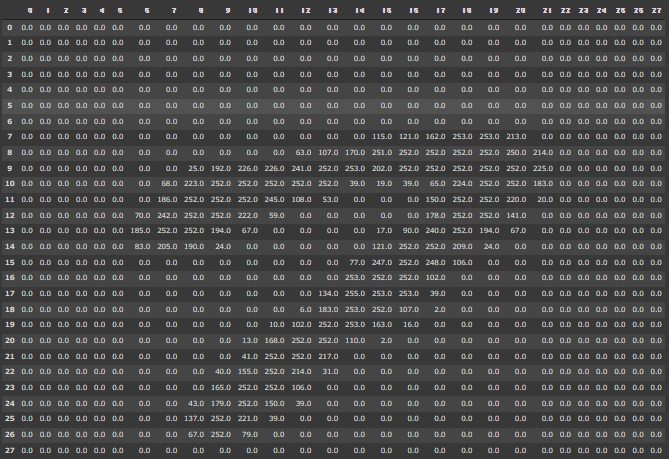
試しに、15番目の画像を見てみると
# カラム表示のデータ数上限を28に変更
pd.options.display.max_columns = 28
# 15番目の要素すべてをNumpy配列にして28×28に整形
value_img = pd.DataFrame(np.array(X.iloc[15,:]).reshape(28,28))
value_img
うっすらと「7」という数字が見える
これをmatplotlibのimshowを使って表示してみると
plt.imshow(value_img, cmap=matplotlib.cm.binary, interpolation="nearest")
plt.show()
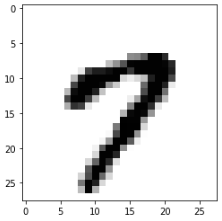
「7」という手書き数字が表示された。
3.データを整形
次に、学習用のコードを書いていく。
画像データを訓練データとテストデータに分割したあと、Kerasで使える形(データ数, 28, 28, 1)に整形する。白黒画像なのでreshapeの最後の引数は1になる。(カラー画像(RGB)の場合は3)
# データを分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/7, random_state=0)
# (データ数, 28, 28, 1)に変換して正規化
X_train = np.array(X_train).reshape(X_train.shape[0], 28, 28, 1).astype("float32")/255
X_test = np.array(X_test).reshape(X_test.shape[0], 28, 28, 1).astype("float32")/255
# 確認
X_train.shape, X_test.shape
# ((60000, 28, 28, 1), (10000, 28, 28, 1))
y_train, y_testも同様にKerasで使えるようone-hot化する。
one-hot化すると、例えば「7」という数字は[0, 0, 0, 0, 0, 0, 0, 1, 0, 0]という風に引数番目に1が入り、他は0の配列となる。また、0と1の大小関係が学習に影響しないよう、yの中身はunit8型にしておく
y_train = np_utils.to_categorical(y_train, 10).astype("u1")
y_test = np_utils.to_categorical(y_test, 10).astype("u1")
# 確認
y_train.shape, y_test.shape
# ((60000, 10), (10000, 10))
4.モデルを構築
データの前処理が終わったので、モデルを構築していく。
Conv2Dの引数stridesはフィルターを動かす距離を、paddingは画素数が落ちないようパディングを行うかどうかを指定している。パディングを行う場合はpadding="same"とする。
ここではoptimizerを名前で指定しているので、パラメータはすべてデフォルト値となる。過去のサイト等を参考にoptimizerからAdamimportして使おうとするとkeras 2.6.0以降のバージョン違いによるエラーが出たので、こちらにまとめた。
model = Sequential()
model.add(Conv2D(32, kernel_size=(3,3), strides=1, padding="valid", activation="relu", input_shape=(28,28,1)))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation="relu")) # Dense(n)は、n個のhidden unitを持つ全結合層
model.add(Dense(10, activation="softmax"))
# 学習プロセスの設定
model.compile(loss="categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])
5.学習
モデルを学習させていく。
学習の経過を描画したいので学習過程をhistoryに格納している。batch_sizeとepochsはテキトーに設定した。batch_sizeには2の階乗の値を設定する風習があるらしいが、特に意味はないらしい。
verbose=nとすると、Epochがn回ごとに表示されるようになる。0にすると表示されない。
# 学習
history = model.fit(X_train, y_train,
batch_size=32,
epochs=10,
verbose=1,
validation_data=(X_test, y_test)
)
学習経過は以下のようになった。

テストデータを入れた時の出力を見てみると
# 予測
pred = model.predict(X_test)
pred_y = np.argmax(pred, axis=1)
# 確認
pred.shape, pred[0], pred_y.shape, pred_y[0]
# ((10000, 10),
# array([1.0000000e+00, 6.7456698e-16, 1.5935905e-12, 3.0622331e-15,
# 2.3965442e-14, 6.6899869e-15, 2.4114765e-08, 3.7310405e-14,
# 5.0209201e-11, 3.7833270e-09], dtype=float32),
# (10000,),
# 0)
長さ10の配列が10000個入っている。つまり、predには手書き数字が取り得るそれぞれのラベル(0~9)の確率が配列の中に入っているため、np.argmaxで一番高い確率の引数を取り出す。
↑では、「0」となる確率が限りなく1に近い値となっている。
6.学習曲線を描画する。
historyを用いて学習過程を可視化する。
# 描画領域を設定
plt.figure(1, figsize=(13,4))
plt.subplots_adjust(wspace=0.5)
# 学習曲線
plt.subplot(1, 2, 1)
plt.plot(history.history["loss"], label="train")
plt.plot(history.history["val_loss"], label="test")
plt.title("train and valid loss")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.legend()
plt.grid()
# 精度表示
plt.subplot(1, 2, 2)
plt.plot(history.history["accuracy"], label="train")
plt.plot(history.history["val_accuracy"], label="test")
plt.title("train and valid accuracy")
plt.xlabel("epoch")
plt.ylabel("accuracy")
plt.legend()
plt.grid()
plt.show()
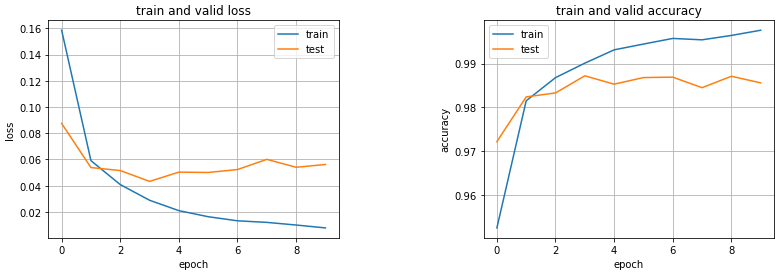
一見バラついているように見えるが、testデータでもMNISTに対して正解率98%と非常に高い精度が出ている。精度が良すぎて逆に不安なレベル。testデータよりtrainデータに適合していて過学習気味であるが、損失も正解率も差が小さいので個人的にはまぁ許せる範囲。MNISTデータの高い精度が出やすいということはこういうことなんだろうなぁ、と実感。
画像分類の初歩は学べたので、次はCIFAR10をKerasとPyTorchで比較しながら実装してみようと思います。