はじめに
データサイエンスの分野に因果分析というものがあります。この分野が取り扱うテーマは、介入が目的変数に与えるインパクトを推計する因果推論・目的変数に影響する変数を特定する因果探索があります。これらはビジネスの世界において有用のはずですが、意外と一般的ではありません。
例えば、因果推論を活用すれば経営施策(新たなセールスプロモーションの導入・ECサイトにおけるリコメンデーションアルゴリズムの改定 など)が目的変数(販売数 など)に与えるインパクトを推計できるので、施策のコストとの対比より意思決定に役立てたり、事後評価により施策の改善に使えるはずです。また、因果探索を活用することで、目的変数に影響する知見や示唆を効率的に得られるようになるはずです。
しかしながら、現実には施策効果の推計は2群の平均を比較する、統計的検定活用する、という方法が主流であり、少しもったいない気がします。また、今後の経営施策に有用な示唆を得る際も、事前に得られている業務知見を踏まえた仮説の定義とその検証がメジャーのため、なかなか目新しいものが得られないように見えます。
そこで、本論は「Pythonによる因果分析」をタネ本に実験した結果を報告します。著書そのものの紹介は、以下に著者の紹介記事がありますので参照したうえで、適宜購入ください。ここでは、タネ本にある実装を踏まえた応用やその結果に見られる活用上の課題などを記したいと思います。
なお、私自身も因果分析について研究中の身ということもあり、理解や実装に誤りがあるかと思います。これらについて指摘などをいただけると大変助かります。
著書紹介
紹介そのものは著者の記事がありますのでこちらに譲ることとし、若干感想のようなものを記載します。
本著は「はじめに」に記載されているように因果分析について興味関心を持つビジネスパーソンや初学者をターゲットにしています。それゆえに理論的説明において数式がかなり控えめで、数式の読み解きが不得手の人でも読みやすく工夫がしてあります。ただし、これは言い方を変えると証明や導出仮定があまり厳密ではないことになりますので、厳密な理解をしたいという初学者にはもの足りないかもしれませんので留意ください。また、本著で紹介されている手法の実装についても疑似データを用いていることもあり、そのままの状態でビジネスの場に活用できるとは言い切れません。それゆえ、本著の実装を理解すればすぐにでも現場で活用できるものと思わず、あくまでも因果分析というものの可能性を感じ取るためのものと割り切ったほうがいいように思います。 加えていうと、この手の本にありがちな「Python実装入門」として1章割いていません。よって、Pythonの実装そのものに不慣れな方は、ちょっと苦労するかと思います。
著書は2部構成となっており、第1部が因果推論、第2部が因果探索になっています。全体で200ページ強とそれほどの分量ではありません。その上で記述の2割ぐらいは実装なので、その意味でかなりコンパクトにまとめている印象です。
なお、因果分析において結構重要な因果関係を表現するグラフ表現については触れられているものの、このグラフ表現と構造方程式の関係があまり語られていません。グラフ表現そのものが行列式によって表現できること、構造方程式も行列式で表現できること、よってグラフ表現と構造法的式は相互に行ったり来たりできる関係にあること、あたりを少し丁寧に説明しないと、第2部の因果探索は結構理解に苦労しそうな気がします。
とはいえ、私のように手法はツールであると割り切っている方にとっては、因果分析というツールの可能性を実装を通じて体感できる本著はとても有益ではないかと思っています。
因果推論
「Pythonによる因果分析」において紹介されている因果分析は基本的なものとして①回帰分析の活用、②逆確率重みづけ法(IPTW法)、Doubly Robust法(DR法)の3種と機械学習を用いた①T-Learner、②S-Learner、③X-Learner、④Doubly Robust Learnerの4種です。
まず、最初に基本的なもの3種について実装とその応用について扱います。
問題設定
ここでは、以下のようなシチュエーションを想定します。
X社は、新しいセールスプロモーション(SPとする)の導入を企画し、実証実験を行った。実験により入手できたデータは実験対象者別に性別・年齢・SPに対する反応の有無・売り上げ数である。これらを使ってSPが売上に与える効果を推計したい。
疑似データを生成するコードは以下です。
def data_create(num_size,SEED) :
import pandas as pd
import numpy as np
import scipy.stats as stats
from scipy.special import expit
np.random.seed(SEED)
Gender = np.random.randint(0,2,num_size) ### 0:女性 1:男性
Age = np.random.randint(15, 76, num_size) ### 15-75の一様分布
base = (Age-40) + (1-Gender)*10+stats.norm.rvs(loc=0,scale=1,size=num_size)*5
SP = stats.bernoulli.rvs(expit(base*0.1), random_state=1234)
df = pd.DataFrame([Gender,Age,SP]).T
df.columns = ['Gender','Age','SP']
df['Sales'] = np.int64(30*Gender - Age + 10*SP + 80 + stats.norm.rvs(loc=0,scale=5,size=num_size,random_state=SEED))
return df
df = data_create(2000,1234)
はじめにSPをキーに売上(Sales)の平均を計算すると以下のようになります。
| SPに対する反応 | 売上(平均) |
|---|---|
| しない | 65.94 |
| する | 51.39 |
これによるとSPを行うと売上が下がることになってしまいますが、直観と合致しません。実際のデータ生成のコードからみても反応した場合にプラスの効果が出るようになっているので正しい分析結果ではないことがわかります。これはSalesに対してSPに対する反応以外の因子が影響しているために起きている事象です。このデータの場合でいうと、性別(Gender)および年齢(Age)がSalesに影響し、SPに対する反応のSalesに対する影響を打ち消していることが上記の結果となっている要因ということです。実際にGenderおよびAgeを使って区分けしてSalesの分布を可視化してみます。
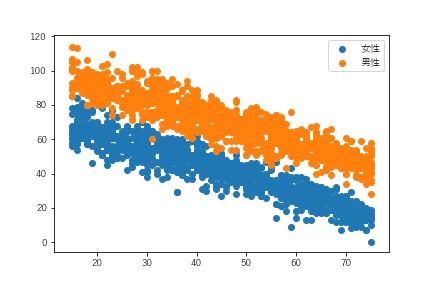
これより「女性より男性の売り上げは低い」、「年齢の上昇につれて売り上げが減少する」ということがわかります。よって集計するにあたりこの2つの要因を除外するかSPに対する反応にについて「あり」群と「なし」群で要因の同質化を図らないと正確な比較になりません。通常の実験の場合、こうした目的変数に影響しうる要因が比較する2群間で同質となるように対象者を設定するため気にする必要がありません。しかしながら、当初想定していなかった要因が目的変数に影響していることが実験後にわかったが再実験する余裕が場合、このデータを活用して分析を続ける必要があります。
そこで、年齢について40歳を境に高年齢と若年齢に仕分けして売り上げを集計します。
| 女性/若年層 | 女性/高年層 | 男性/若年層 | 男性/高年層 | 全体 | |
|---|---|---|---|---|---|
| SPに反応しない | 52.90 | 23.06 | 81.10 | 54.07 | 65.94 |
| SPに反応した | 56.46 | 29.07 | 86.10 | 58.30 | 51.39 |
| 全体 | 54.82 | 28.66 | 82.67 | 57.61 | 56.51 |
これにより、SPに反応したほうが売り上げが大きくなることが見えます。しかしながら、まだこれでも十分とはいえません。以下は性別と年齢階層を軸にSPに対する反応を集計したものです。
| 女性/若年層 | 女性/高年層 | 男性/若年層 | 男性/高年層 | 全体 | |
|---|---|---|---|---|---|
| SPに反応しない | 0.459 | 0.067 | 0.687 | 0.162 | 0.352 |
| SPに反応した | 0.540 | 0.932 | 0.312 | 0.837 | 0.648 |
| 全体 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
これによると、男性よりも女性、若年層より高年層、がSPに反応しやすいことがみられます。よって、年齢階層、性別によってセグメンテーションして平均売り上げを比較した結果に差異があっても疑似相関である可能性は否定できません。
このような与えられた変数が相互に関連を持っているような状況において介入(疑似データでいうSP)が目的変数(疑似データでいう売り上げ)に与える影響を推測することが、因果推論の扱う主要なテーマということになります。
回帰分析の利用
回帰分析を用いる方法とは、目的変数(疑似データの場合は売り上げ)に影響すると思われる変数(性別・年齢・SPへの反応)を入力とした回帰モデルを構築し、その係数から効果を推計する方法です。
この方法は、理解が直観的で使いやすいように思います。モデルが、
sales = w1×Gender + w2×Age + w3×SP + b1
として表現されるということは、SPが1(反応した)の場合のsalesの増加はw3であるということです。このモデルの導出は、因果推論独自の『介入効果(doオペレータ)』、『調整化公式』、『バックドア』、『d分離』などの概念・理論を用いて構造化方程式を式変形することで得られます。
実装は、機械学習に慣れている人であれば簡単です。本書では、scikitlearnの回帰モデルを使用しています。ただ、これだと係数の確からしさの評価ができないので、以下はstatsmodelsを使ったコードを掲載します。
import statsmodels.api as sm
x = sm.add_constant(df[['Gender','Age','SP']])
y = df[['Sales']]
model_OLS = sm.OLS(y,x).fit()
print(model_OLS.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Sales R-squared: 0.946
Model: OLS Adj. R-squared: 0.946
Method: Least Squares F-statistic: 1.157e+04
Date: Sun, 16 May 2021 Prob (F-statistic): 0.00
Time: 06:57:39 Log-Likelihood: -6061.1
No. Observations: 2000 AIC: 1.213e+04
Df Residuals: 1996 BIC: 1.215e+04
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 79.4607 0.328 241.936 0.000 78.817 80.105
Gender 30.3686 0.229 132.406 0.000 29.919 30.818
Age -1.0105 0.008 -131.188 0.000 -1.026 -0.995
SP 10.5715 0.285 37.132 0.000 10.013 11.130
==============================================================================
Omnibus: 1.487 Durbin-Watson: 2.053
Prob(Omnibus): 0.475 Jarque-Bera (JB): 1.399
Skew: 0.057 Prob(JB): 0.497
Kurtosis: 3.063 Cond. No. 149.
==============================================================================
ここから、SPの係数は10.57で疑似データ生成と同じでうまく推計できていることがわかります。また、確からしさを評価するP>|t|や係数の範囲推計([0.025 0.975])も良好です。
さて、ここから応用を考えます。問題設定で示した通り、得られたデータは実験結果です。実際にセールスプロモーションを実施する対象は、別に10000件あったとした場合、どの程度の売り上げ増が期待できるのでしょう。今、手元にあるモデルでは推計ができません。モデルの説明変数にSPに対する反応が含まれていますが、実際のセールスプロモーションは未実施のため、もう一工夫しないと推計できません。
そこで、事前の分析から性別・年齢とSPに対する反応に関係があることからSPに対する反応を予測するモデルを構築してSPを生成します。SPの効果はこの係数なので、SP=1の場合のみ係数を積み上げてあげれば全体の効果になります。このSP(SPに対する反応)ですが、通常の機械学習の場合は真に属する確率が所定の閾値より大きいというルールベースで決定します。しかしながら、特定の集団の分析についてこの方法を適用すると、都合が悪いことが生じます。例えば、対象100人全員について真に属する確率が0.8だとした場合、ルールベースだと100人全員がSPに反応するということになります。一方、確率0.8ということは100人中20人は偽(つまりSPに反応しない)ということを意味しているので、確率値と真偽の割合の整合が取れません。この確率と実際の判定結果の整合を図るためにロジスティック回帰モデルの出力値である真に属する確率をもとにベルヌーイ分布によるランダムサンプルを生成することにします。こうすることで確率0.8の場合、10人中2人程度が偽になるようにデータが生成できます。
実装と結果は以下です。
Data_for_Predict = data_create(10000,12) ### 予測対象群
Data_for_Predict.drop(['SP','Sales'],inplace=True,axis=1) ### 本来の未知の項目を削除
#### 実験データからモデルを作成
from sklearn.linear_model import LogisticRegression as Logit
model_logit = Logit().fit(X=df[['Gender','Age']],y=df['SP'])
def SP_Decision(Prob) : ### 真に属する確率からSPへの反応を決定する関数
return stats.bernoulli.rvs(p=Prob)
P = model_logit.predict_proba(Data_for_Predict) ### 確率の推計
df_ = Data_for_Predict.copy()
result = [] ### 結果を格納する変数
for i in range(10000) : ##### サンプリングを1万回行う
df_['SP_'] = SP_Decision(P[:,1]) ### 個人単位に判定
df_['Sales_'] = df_['SP_'] * model_OLS.params['SP'] ### 判定結果をもとにした効果推計
result.append(np.mean(df_['Sales_'])) ### 効果の全体平均の計算
plt.hist(result,bins=100)
plt.show()
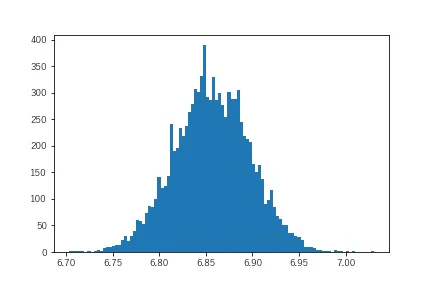
これから、効果平均は6.85あたりだということがわかります。本来の効果が10なので、大まかにいうと平均して3割程度の対象者がSPに反応しないことが要因ということもわかります。また、得られたサンプリングデータの分布のうち、0.0025より小さいケースは起きえないことと定義することで、最悪時の効果を推計することもできます。こうしたいくつかの効果を取得したうえで、SPに必要なコストを組み合わせることで費用対効果も可視化できるようになります。
IPTW法およびDR法
いずれも底通する考え方は同じで計算方法が若干異なるものです。この考え方とは、『因果効果とは、観測データ単位で、介入があった場合の目的変数と介入がなかった場合の目的変数の差異であり、これを集団として平均を求めること』ということになります。
このように考え方はシンプルなのですが、現実には介入があった場合となかった場合は同時に存在することがないため、単純に計算することができません。そこで、IPTW法やDR法といった方法が見出されました。
IPTW法とは、観測された目的変数に対して介入(疑似データでいうSPに反応)を受ける確率を用いて調整して計算する方法です。計算式および導出の過程は著書を読んで確認してもらうものとし、ここでは実装から始めて実験をしたいと思います。
#### 関数の定義
def IPTW_estimate(Y,Prob,Class) : ### Y:目的変数 Prob:クラス確率 Class:観測された介入の有無
tmp = Y/Prob[:,1]*Class - Y/Prob[:,0]*(1-Class)
return np.mean(tmp)
#### 実際の計算(確率の計算モデルは既に実装済みのものを使用)
predict_prob = model_logit.predict_proba(df[['Gender','Age']])
ATE = IPTW_estimate(df['Sales'].values,predict_prob,df['SP'].values)
若干、実装について説明します。まず、実際の売り上げを調整している部分が、Y/Probの部分になります。逆確率というだけあって、観測値に確率の逆数を乗算して重みづけをしています。Probの0列に偽値の確率、1列に真値の確率が格納されるようにしているので、スライスすることで重みを使い分けています。最後のClassの乗算は、Classの相違によって計算方法の使い分けを表現しています。つまり、Class=0の場合は後半のみ計算し、Class=1の場合は前半のみ計算するということにしています。結果は10.267と、実際の10に近似した結果となりました。
では、実装を前提に実験を始めます。上記では2値分類モデルをロジスティック回帰を使用していますが、別のモデル(例えばニューラルネット)を用いるとどのようなことになるのでしょうか?
import tensorflow.keras as keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.optimizers import RMSprop , Adam
batch_size = 50
num_classes = 2
epochs = 100 #
# モデルの作成
model = Sequential()
model.add(Dense(100, activation='sigmoid', input_shape=(2,)))
model.add(Dense(80, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
x_train = np.float32(df[['Gender','Age']].values)
y_train = keras.utils.to_categorical(df[['SP']].values, 2)
# 学習
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,validation_split=0.2
)
ニューラルネットの予測結果を用いた混合行列は以下です。
| 予測値=0 | 予測値=1 | |
|---|---|---|
| 観測値=0 | 536 | 168 |
| 観測値=1 | 274 | 1022 |
予測性能は、(536 + 1022) / 2000 = 0.779ということで、ロジスティック回帰のもの(0.780)と遜色なく、ATEの違いはそれほどでもないと思われますが、実際には大きく異なった結果となります。しかも、学習をやり直す(つまり、モデルパラメータが変化する)とIPTWの計算結果が変化してしまい安定しません。これがIPTW法の欠点といっていいかと思います。あらためて関数を見ると、調整には確率値の逆数を使用しているため、予測される確率値に計算結果が強く依存することになります。つまり、IPTW法は真値に属する確率値の推計性能が推計値を決めるといっても過言ではありません。しかしながら、この確率値自体の正確性を評価することはほぼ不可能です。評価に使用できるデータはSPへの反応という離散値しか存在しないので、ロジスティック回帰が、真に属する確率=0.6と予測した結果とニューラルネットが0.8と予測した結果でどちらがより正確であるのかと問われても判断することはできません。さらにいうと、計算の対象が実際のクラス(SPに対する反応)によってどちらか一方のみが計算されることになるため、クラス=1のデータに対して予測値が限りなく1.0に近く、クラス=0のデータに対しても同様の結果となっていると、この計算結果は、単純にクラス=1とクラス=0の平均値の差に近似していきます。
以上は、本書の第四章のまとめに『処置を受ける確率が各変数の線形和を用いるロジスティック回帰では表現できない場合は性能が悪化する』と記述されています。このあたりの具体的考察は範囲外ということのようで詳細な記述がありませんので、今後、もう少し調べたほうが活用時の留意点を抑えることができると思います。
続いてDR法です。DR法は、因果効果の考え方である介入がある場合と介入がない場合の差異を計算するというものを忠実に実現しようとするものです。そのために実際には存在しないケース(例えば、介入があったデータに対してはなかったデータ)をモデルによって推計したうえで、クラスに属する確率で調整するというものです。こちらについても計算式の導出の過程は本著を参照して確認してもらうことを前提に実装と検証を進めます。
#### DR法の関数
#### Y:売り上げ,C_0:Class=0の売上予測,C_1:Class=1の売上予測,Prob:クラスの確率,Class:観測されるクラス
def DR_estimate(Y, C_0, C_1, Prob, Class) :
ATE_1 = Y/Prob[:,1]*Class + (1-Class/Prob[:,1])*C_1
ATE_0 = Y/Prob[:,0]*(1-Class) + (1-(1-Class)/Prob[:,0])*C_0
return np.mean(ATE_1 - ATE_0)
df['SP_0'] = 0
df['SP_1'] = 1
df['Sales_0'] = model_LR.predict(df[['Gender','Age','SP_0']])
df['Sales_1'] = model_LR.predict(df[['Gender','Age','SP_1']])
result1 = DR_estimate(Y=df['Sales'].values,
C_0=df['Sales_0'].values,
C_1=df['Sales_1'].values,
Prob=predict_prob,
Class=df['SP'].values)
result2 = DR_estimate(Y=df['Sales'].values,
C_0=df['Sales_0'].values,
C_1=df['Sales_1'].values,
Prob=predict_prob_nn,
Class=df['SP'].values)
print('ロジスティック回帰のケース ',result1)
print('ニューラルネットのケース ',result2)
結果は、いずれも10.0に近似したものとなりました。ニューラルネットを用いることでSPに反応するケースについてロジスティック回帰よりも確率が高いものになったとしても反応しないケースの確率が反対に小さいものとなって相殺してくれるので、最終的な結果は安定的になるようです。
機械学習の活用
先述した因果効果はどの観測値にも共通して生じることが前提になっています。先の疑似データでいうと、年齢階層や性別によらず10.57ということです。しかしながら、取り扱う分野によっては年齢階層や性別によって効果が異なることがあり得ます。全体を平均してしまえば、これらの属性の相違は気にしなくても構わないのですが、個人ごとの相違を可視化したい場合は都合がよくありません。こうした観測値ごとに異なる因果効果を推計することを目的にした方法として、第5章において機械学習を用いた方法が紹介されています。
問題設定
以下のようなシチュエーションをベースにした疑似データを考えます。
X社の人事部がマネージャ向けに部下に対するフィードバック面談法に関する研修を行った。その後の追跡調査により、部下の育成に対する熱心さ・研修の参加・部下の面談に対する満足度、が入手されている。このデータを活用することで研修実施の効果を推計したい。
疑似データを生成する関数は以下です。
def create_data(SEED,num_data) :
np.random.seed(SEED)
##random.seed(SEED)
# 部下育成への熱心さ
x = np.random.uniform(low=-1, high=1, size=num_data) # -1から1の一様乱数
# 人事研修に参加したかどうか
e_z = np.random.randn(num_data) # ノイズの生成
z_prob = expit(-5.0*x+5*e_z)
Z = stats.bernoulli.rvs(z_prob,random_state=SEED)
# 介入効果の非線形性:部下育成の熱心さに応じて段階的に変化
category = pd.cut(x,bins=[-np.inf,0,0.5,np.inf],labels=[0,1,2])
coef = np.array([[0.5],[0.7],[1.0]])
t = pd.get_dummies(category).values@coef.flatten()
e_y = np.random.randn(num_data)
Y = 2.0 + t*Z + 0.3*x + 0.1*e_y
df = pd.DataFrame({'熱心度': x,
'研修参加': Z,
'研修効果': t, ###本来は未知の項目 参考にするため、付与
'満足度': Y,
})
return df
df = create_data(1234,500)
本来、未知である研修の効果は以下です。分析に先立って、部下の育成に対する熱心度が異なると研修の効果も異なるという仮説があり、この相違を可視化することが分析のゴールとします。

t-learner
t-learnerは得られた分析用データを用いてモデルを2種類作成する方法です。因果効果は分析対象1件単位で、介入があった場合の目的変数の値と介入がなかった場合の値の差異のことと定義されます。この際、機械学習を用いて観測値に対して介入があった場合となかった場合の目的変数を推計できます。これによって、研修の参加・不参加のいずれかの満足度しか観測されていない状況に対して双方の満足度を得られることになるので、因果効果を推計できることになります。
実装は、本書に記載されているランダムフォレストを用います。
# 集団を2つに分ける
df_0 = df[df['研修参加'] == 0.0] # 研修不参加
df_1 = df[df['研修参加'] == 1.0] # 研修参加
# 研修に参加していないモデル
reg_0 = RandomForestRegressor(max_depth=3)
reg_0.fit(df_0[["熱心度"]], df_0[["満足度"]])
# 研修に参加したモデル
reg_1 = RandomForestRegressor(max_depth=3)
reg_1.fit(df_1[["熱心度"]], df_1[["満足度"]])
# ATEの推計
df['研修なし'] = model0.predict(df[['熱心度']])
df['研修あり'] = model1.predict(df[['熱心度']])
np.mean(df['研修あり']-df['研修なし'])
結果は、0.681となりました。この値は、疑似データに付与されている個人別の研修参加時の効果の平均(0.671)と近似し、うまく推計できていることがわかります。ちなみに回帰モデルと同じ方法で研修参加の効果を推計すると、0.678となります。
from sklearn.linear_model import LinearRegression
LR_model = LinearRegression()
LR_model.fit(X=df[['熱心度','研修参加']],y=df[['満足度']])
print(LR_model.coef_)
ただ、これだと個人単位の因果効果がわかりません。一方、機械学習を用いた場合、個々の対象について満足度の推計結果があるのでこれを活用することで個人別の因果効果を推計することができます。
plt.scatter(df['熱心度'],df['研修効果'],label='真の効果')
efficiency = df['研修あり'] - df['研修なし']
plt.scatter(df['熱心度'],efficiency,alpha=0.5,label='推計効果')
plt.xlabel('熱心度')
plt.ylabel('研修効果')
plt.legend()
plt.show()

この結果を用いることで、次回に研修を行う際により効果を高める施策を吟味することができます。つまり、熱心度がゼロを割り込んでいる場合の効果はそれほど大きくないので、このケースは除外して研修を行うという判断ができます。あるいはこの熱心度がゼロ以下の対象者については、異なる研修(例えば、熱心度を引き上げることを目的としたもの)を企画実施するという判断も可能となります。
s-learner
s-learnerは、t-learnerと方向性は同じでモデルを使って介入がある場合とない場合の目的変数を推計して差異を求めるものです。相違点はモデルを1つ作成して入力データを変化させることになります。
# 研修参加を説明変数に含めたモデル
reg_ = RandomForestRegressor(max_depth=4)
reg_.fit(df[["研修参加","熱心度"]], df[["満足度"]])
df['研修不参加_仮想'] = 0
df['研修参加_仮想'] = 1
# ATEの推計
df['研修なし'] = reg_.predict(df[['研修不参加_仮想','熱心度']])
df['研修あり'] = reg_.predict(df[['研修参加_仮想','熱心度']])
print(np.mean(df['研修あり']-df['研修なし']))
結果はt-learnと近似したものとなります。使い分けは、モデルの予測の性能によって決めることになるかと思います。t-learnにしてもs-learnにしても予測結果の差異を因果効果とするという考え方に相違がないことから構築したモデルが観測値に近似していることが因果効果の推計の確からしさを決めるといっていいはずです。
x-learner,Doubly-Robust-Learner
本書は、他に2つの方法が紹介されています。いずれもこれまでのT-LearnerやDR法などをベースに機械学習を応用したものへと拡張したものです。それゆえに計算手順の多く、結構面倒です。x-learnerは、介入ありとなしの2モデルに加えて、因果効果そのものを推測するモデル、さらに介入が生じる確率を推計するための2値分類モデルを構築する必要があります。これまでの疑似データに見られるような取り扱うデータ項目が少数なのであればいいのですが、数百~数千といった膨大な項目が存在する場合、機械学習モデルを構築するだけでかなりの時間と労力を必要としそうです。 このあたりの手間がビジネスの場において因果推論があまり普及していかない要因なのかもしれません。
ここまでのまとめ
思いのほか分量が多くなったのでいったんここで終わりにして続きである因果探索は次に回したいと思います。因果推論は、ビジネスの場において本来はとても重要なものです。ある施策を行うにあたり、その施策の有効性を検証するために実験を行うことはよくあることかと思います。その実験結果から施策が目的変数に対して有効なのかどうかを正しく推計することは重要なことです。
一方、因果推論も万能ではありません。因果推論は手元にあるデータの解析に比重が置かれた手法のため、未知の対象者に対して施策を行った場合の効果を推計してくれません。あくまでも施策がうまくいった場合の効果を推計するまでがスコープです。そのため、因果効果とは少し異なる方法(先のSPのケースにおいて活用したシミュレーション など)を応用して因果効果の結果を活かしていく必要があります。
また、より複雑な効果を推計する必要がある場合は機械学習の応用が必要となります。機械学習について実装経験のある人であれば、相応の性能が出るモデルを構築するだけでも意外と苦労します。その上、SPのケースであれば、因果効果を推計するためにモデル(SPに反応するかどうかの2値分類)を構築するよりもSPに反応するかどうかを識別するモデルを適用してSPを展開する対象者を絞ってしまったほうが費用対効果が高くなるかもしれません。