kaggleに日本アニメのデータが掲載されていたので、リコメンデーションアルゴリズムの作成を行いました。
はじめに
データは、以下です。
https://www.kaggle.com/CooperUnion/anime-recommendations-database
元のデータは、myanimelist.netというサイトから取得したもので、2種類あります。1つはアニメの特徴を表すデータセット(anime.csv)でアニメコンテンツ単位にジャンルや評価値などのデータで構成されています。もうひとつ(rating.csv)は、このサイトユーザがアニメコンテンツに対して付与した評価値で、アニメIDとユーザIDでユニークになっています。
試行のゴール
想定するユースケースは、新規ユーザに対するリコメンデーションとします。この場合、コンテンツの閲覧履歴のないユーザに対するリコメンデーションとなりますので、anime.csvに含まれる特徴量をもとに類似するコンテンツをリスト化するアルゴリズムを作成します。
リストは、15件とします。この際、15件を固定的にリスト化するのではなく100~200件をコンテンツの類似性からリコメンド候補として抽出した上で、ランダムに15件に絞り込むというアルゴリズムにします。これによって新規ユーザという嗜好性が不明なユーザにとってバリエーションに富んだリストにします。
リコメンド候補リストの作成は、K平均法によるクラスタリングにて行います。これによってあらかじめ全コンテンツにクラスを割り振っておき、手にしたコンテンツと同じクラスに所属するコンテンツを抽出するという方法でリコメンド候補リストを作成します。
データの概要・特徴量の選択・事前処理
anime.csvには、『ID』、『作品名』、『ジャンル』、『タイプ(TVシリーズ・映画など)』、『エピソード数』、『評価値(0-10)』、『メンバー数(当該コンテンツに関するコミュニティに参加する人数)』が含まれます。今回は、以下を対象にすることにしました。
- ジャンル
コンテンツの特徴を表しているもので、一番メインとなるものです。
- タイプ
TVシリーズを手にしたユーザにTVシリーズをリコメンドしようとものです。
- 評価値
手にしたコンテンツと同程度の評価値のものをリコメンドするためのものです。
- メンバー数
メンバー数を話題になっていることを示す指標と解釈し、手にしたコンテンツと同程度のものを
推奨するためのものです。
ジャンルですが、ひとつの列にカンマ区切りで複数のデータが格納されているので、事前処理が必要です。最終的にジャンルをカラム名にしたOne-Hot化したいので、ジャンルに含まれる文字数をカウントしてベクトル化する方法で処理することにしました。具体的に言うと、scikit-leanに含まれるCountVectorizerを使います。
ただし、このCountVectrizerはカンマやハイフンさらにスペースで単語を区切ってしまうため、Sci-Fi(日本でいうSF)やMartial Arts(武道・武術)は、SciとFiやMartialとArtsに分けて計測されてしまうので、ひとつの単語と認識されるように調節する必要があります。この調節は、目視確認してreplaceで対応しました。
コードは以下の通りです。
anime = pd.read_csv('anime.csv') # ファイルの読み込み
# 文字データをベクトル化するための前処理
def feature(txt): # CountVectrizerが機能しないものを置き換える関数
lists = txt.replace("Slice of Life","Life")
lists = lists.replace("Sci-Fi","SF")
lists = lists.replace("Shounen Ai","BL")
lists = lists.replace("Shoujo Ai","GL")
lists = lists.replace("Super Power","Superp")
lists = lists.replace("Martial Arts","Budou")
return lists
genre = anime['genre'].apply(feature)
# 文字をベクトル化
from sklearn.feature_extraction.text import CountVectorizer
vect =CountVectorizer()
word2vec = vect.fit_transform(genre)
# 結果をデータフレームに変換
genre = DataFrame(word2vec.toarray(),columns=vect.get_feature_names())
ジャンルにはnanが含まれていますので、上記の前にさらに前処理が必要です。自分は、nanをunknownに置き換え、K平均法を適用する場合はこのunkownの列を削除して対応しました。
また、このジャンルにはMusicが含まれています。このMusicですが、タイプがミュージックビデオの場合に付与されるとともにコンテンツ自身が音楽を扱っている場合(例:のだめカンタービレ)にもこのMusicが付与されます。どちらも同じコードでありながら意味合いが異なるのでクリーニングしたほうがいいと判断し、タイプがMusicの場合はジャンルのMusicを削除することにしました。
メンバー数ですが、最小値5、最大値1,013,917とあまりに幅がありすぎるのでlogで対数に変換しました。
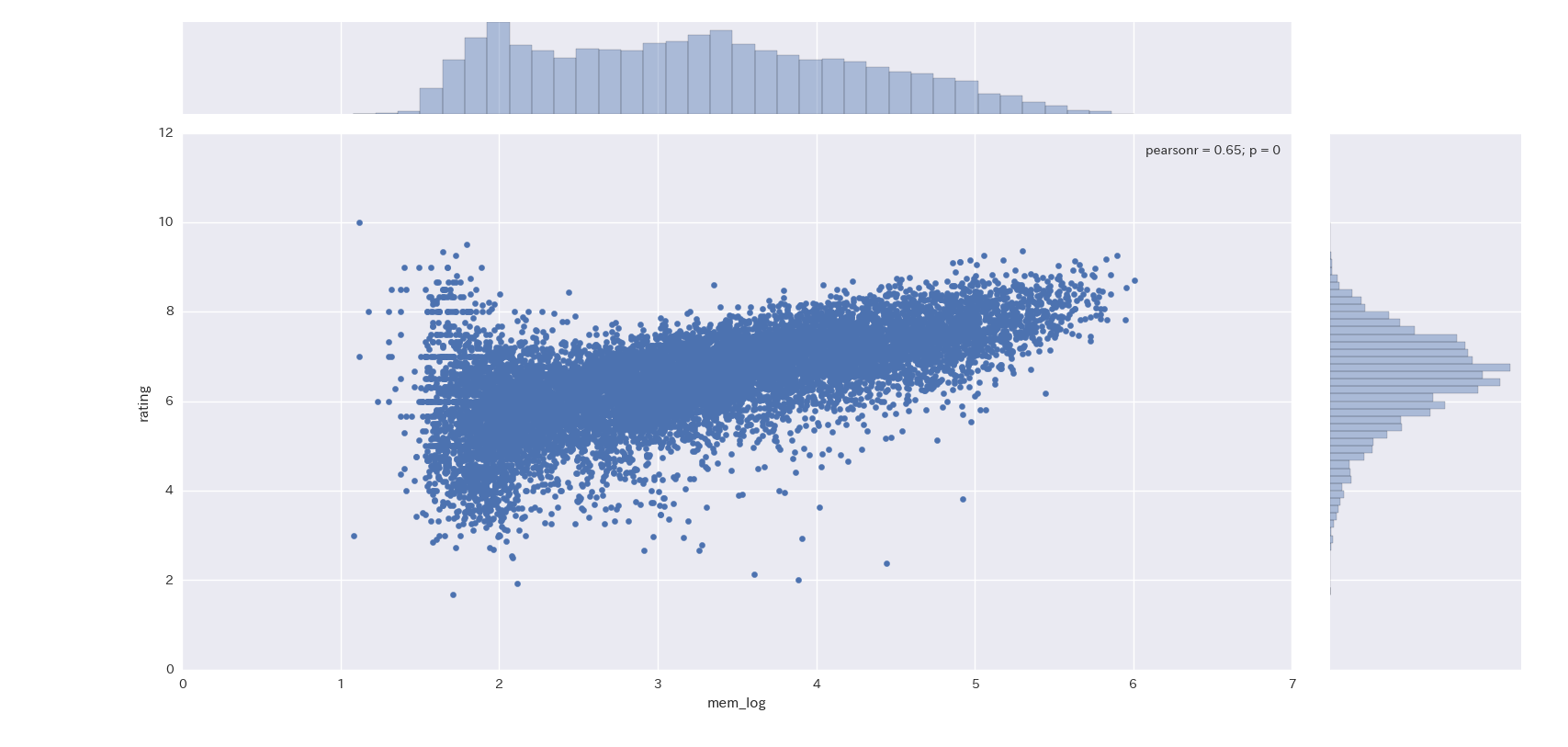
評価値ですが、nanが230件ほどあることが分かったので上記のメンバー数(log10によって置換)をもとに推計した結果を活用することにしました。参考までに評価値とメンバー数の関係を可視化したものを掲載します。
コードは以下の通りです。
import statsmodels.api as sm
# 欠損値となっている評価値を推計結果で補完する
# statsmodelで回帰分析を実施
x=np.log10(anime.dropna()['members'])
y=anime.dropna()['rating']
x=sm.add_constant(x,prepend=False)
lin_reg = sm.OLS(y,x)
results = lin_reg.fit()
# 評価値をモデルで補完する
tmp = anime[anime['rating'].isnull()==True] # 欠損値となっているデータの抽出
x = tmp['mem_log'] # 評価値の補完
tmp['rating'] = results.params[0] * x + results.params[1]
クラスタリングの結果
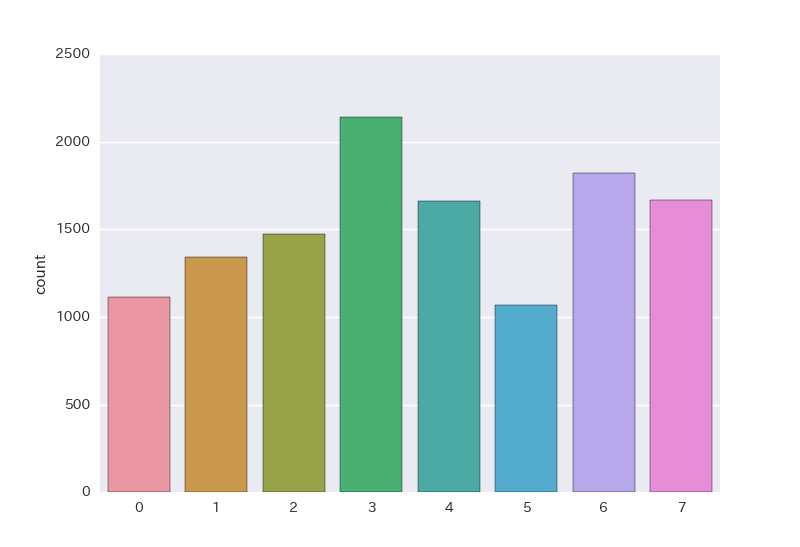
事前処理したものを統合したデータセットからクラスタリングを行います。まずは、クラスター数などのパラメータをデフォルト値で実施しました。
クラスの分布は以下の通りで、変に偏っておらずいい感じです。
各クラスタがどのような意味を持っているのかを確認するため、各クラスのジャンル構成上位5つをリストアップします。
sf 0.199578
action 0.171941
mecha 0.123840
adventure 0.099156
shounen 0.070464
Name: 0, dtype: float64
これからするとクラス0の名称は、少年向けSFメカアクションアドベンチャーでしょうか。
comedy 0.106620
action 0.100951
shounen 0.079920
fantasy 0.070227
adventure 0.069861
Name: 1, dtype: float64
同様にクラス1は、少年向けファンタジーアクションアドベンチャーコメディー。
hentai 0.388689
fantasy 0.055115
action 0.048271
drama 0.045389
romance 0.044308
Name: 2, dtype: float64
クラス2は、構成比からすると、変態の一言で片づけてもいい感じです。
comedy 0.181317
kids 0.145868
fantasy 0.089581
adventure 0.060838
drama 0.057006
Name: 3, dtype: float64
クラス3は子供向けファンタジーアドベンチャーコメディドラマ
comedy 0.117793
action 0.084767
romance 0.071006
drama 0.065226
school 0.058484
Name: 4, dtype: float64
クラス4は、学園ものアクションラブコメドラマ
comedy 0.170691
kids 0.130264
dementia 0.087030
action 0.074116
adventure 0.052779
Name: 5, dtype: float64
クラス5はジャンルよりも評価値とメンバー数の平均が特徴的で、評価値が4.37 メンバーズ数が2.12と全体平均を下回っています。これからすると、クラス5は不人気作品群というところでしょうか。
comedy 0.240227
fantasy 0.064400
school 0.061001
romance 0.059868
life 0.053258
Name: 6, dtype: float64
クラス6は相違はあるものの、クラス4と類似しています。相違点はタイプにあってクラス4はTVシリーズに偏っていますが、クラス6はもう少し万遍なく分布しています。
kids 0.135842
comedy 0.133777
adventure 0.122074
fantasy 0.103029
drama 0.086508
Name: 7, dtype: float64
クラス7は、並びに微妙な相違はあるものの概ねクラス3と同じです。評価値の平均に相違があるようで、クラス3はやや低評価、クラス7は平均的評価とであることが見て取れます。
| クラス | 評価値 | メンバー数 |
|---|---|---|
| クラス3 | 5.710481 | 2.223979 |
| クラス7 | 6.878014 | 2.401120 |
以上よりK平均法によって作成されるクラスは相応に意味のあるものになることがわかりました。
続いて、さらにクラス数を増やします。
冒頭で説明した通り、1クラス100~200件(15件をランダムに選択するとして10回に1回程度で同じコンテンツが表示されるレベル感)にしようと思うので単純計算から60~120(全コンテンツ数約12,000を除算したもの)のクラスが必要となります。今回は中間の90を設定しました。
各クラスの件数は、以下になりました。
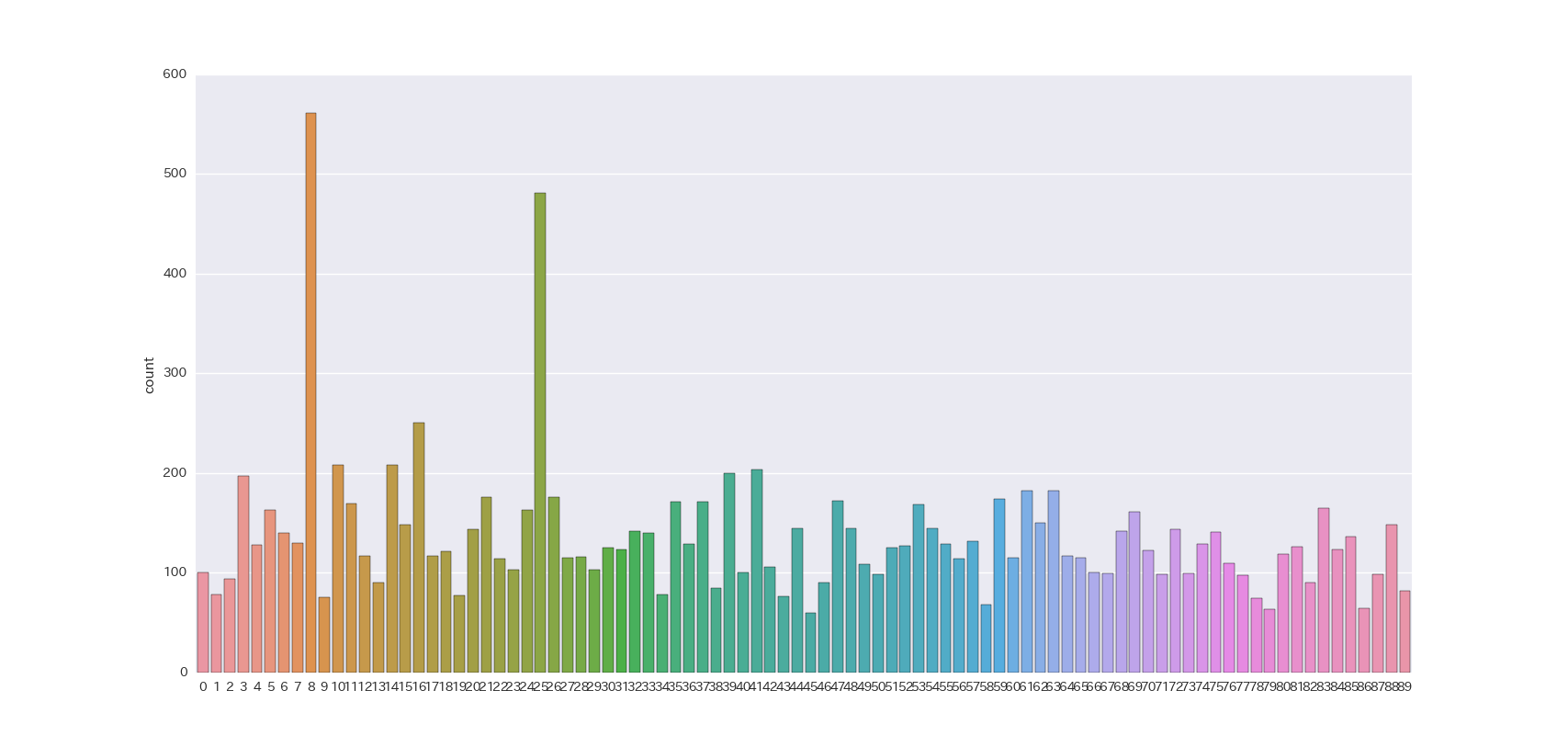
クラス8と25に偏った結果になっています。ジャンルの構成を見たところ、どちらも変態系アニメでした。この系統はクラス数8のときのクラス3に相当します。クラス数8で2000件だったものがクラス数90で500前後ということで、特徴量の偏りがきついような感じがするので、これで妥協することにします。
コンテンツの絞り込み
続いてリコメンデーション候補リストからの絞り込みアルゴリズムを構築します。
冒頭に述べた通り、絞り込みはランダムに行います。そのためnumpyのrandom.choiceを使います。ただ、そのままだと、どのコンテンツも同価値として扱われます。より人気のある(あるいは評価の高い)コンテンツのウェイトを高く設定したいと思います。
このウェイト付けにはRating(評価値)とレビュー数を使います。レビュー数はrating.csvを読み込み、anime_id単位で件数カウントしたもののことです。
両者は単位が異なるのでzscoreに換算して合算することで総合的な指標とします。さらにウェイトにするため、softmax関数によって総合的な指標を確率値に換算してウェイトとして使うことにします。
上記をコードで表現すると以下のようになります。
anime = anime[['anime_id','rating']] # 使用する項目のみ抽出
anime['class_no'] = results.labels_ # class_noを反映
# review数をカウントしてデータを統合
rating = pd.read_csv('rating.csv')
tmp = rating.groupby('anime_id').count().rename(columns={'user_id':'review'})
x = pd.merge(anime,tmp,left_on='anime_id',right_index=True,how='left').drop('rating_y',axis=1)
x.review = np.log10(x.review)
x.fillna(-0.01,inplace=True) # animeにあってratingにないケースに備えて補正
# class別にzscoreとsoftmaxを計算
idx = np.arange(90)
for i in idx :
if 1 == 0 :
tmp = x[x['class_no']==i]
tmp['zscore']=sp.stats.zscore(tmp[['rating_x','review']],axis=0).sum(axis=1)
tmp['recom_ratio'] = np.exp(tmp['zscore'])/np.exp(tmp['zscore']).sum()
else :
tmp2 = x[x['class_no']==i]
tmp2['zscore']=sp.stats.zscore(tmp2[['rating_x','review']],axis=0).sum(axis=1)
tmp2['recom_ratio'] = np.exp(tmp2['zscore'])/np.exp(tmp2['zscore']).sum()
tmp = pd.concat([tmp,tmp2])
まとめ
上記によって得られた結果(クラス番号・ウェイト)を使ったレコメンデーションのアルゴリズムの評価には至っていません。
試しに、rating.csvのデータよりランダムにユーザを選定、そのユーザのレビューを行ったコンテンツから1件をランダムに抽出という手順でテスト対象を設定し、設定したアルゴリズムでレコメンデーションのコンテンツリストを作成し、当該ユーザのレビュー履歴のあるコンテンツと照合することで精度を検証しましたが、ヒットしませんでした。
さすがにユーザの嗜好を反映しないレコメンドは、全件(約12,000)からランダムに抽出ものと相違がないようです。