はじめに
いちおう,機械学習の分野に関する内容です.
そして,完全に備忘用になってます.
大規模機械学習
英語ではLarge scale machine learningとなる.
大量の学習データを使ってバッチ学習させようとすると,計算量がとんでもないことになる.併せて,学習データ自体がメモリに展開できないということもある.
計算処理に工夫
\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}
これは,回帰モデルを勾配降下法を使って,パラメータ$\theta_j$を更新させる式である.
$m$の値が,400,000,000や1,000,000,000などの学習データを用意していた場合,そのまま計算するのは現実的ではない.そこで一工夫を加える.
注目するのは$\sum$の部分である.この合計処理は,結果的にすべての数値を足せば良いのだから,分割して部分的に合計を出して,そのあとに最終結果を出しても同じになる.そうすれば,並列処理の話に持ち込めるようになる.
かりに,$m = 400$とおいて4つに分割すると,
\begin{align}
&\sum_{i=1}^{400}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \\
= &\sum_{i=1}^{100}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} + \sum_{i=101}^{200}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \\
&+ \sum_{i=201}^{300}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} + \sum_{i=301}^{400}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)} \\
\end{align}
という風になる.分割した部分を別々のPCで計算させて,その結果を1台のPCに集めて,最終結果を求める.こうすることで,$\sum$の部分の計算時間を4分の1に減らすことが出来る.
単一PCでゴリゴリ計算させる方法と分散して計算させる方法のイメージはこんな感じだろう.
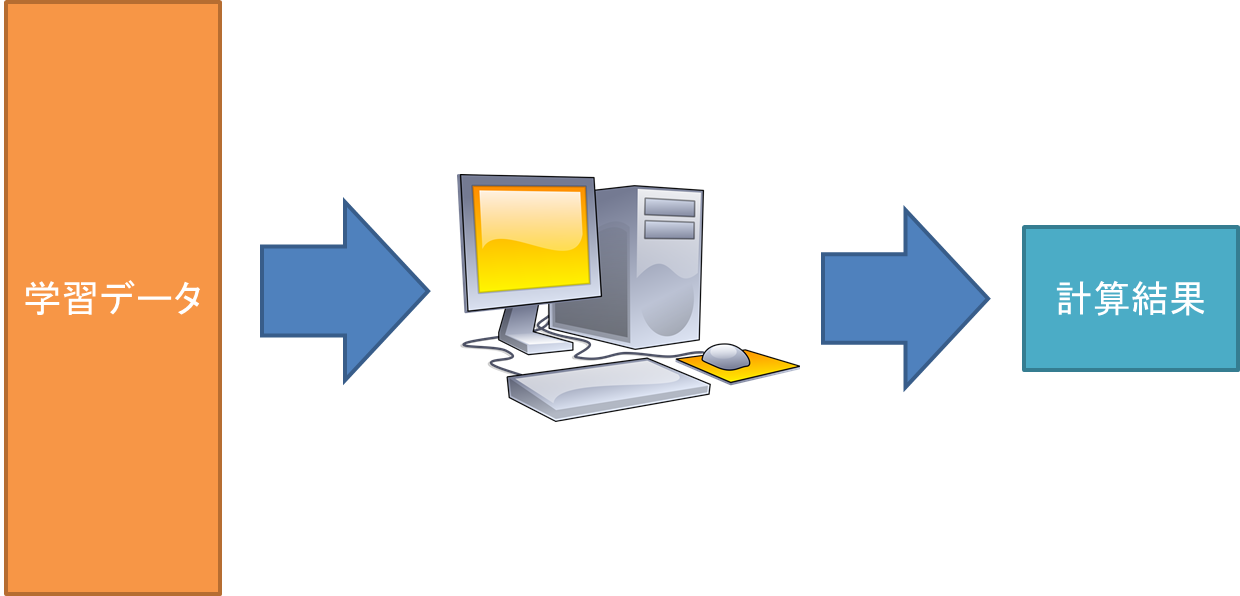
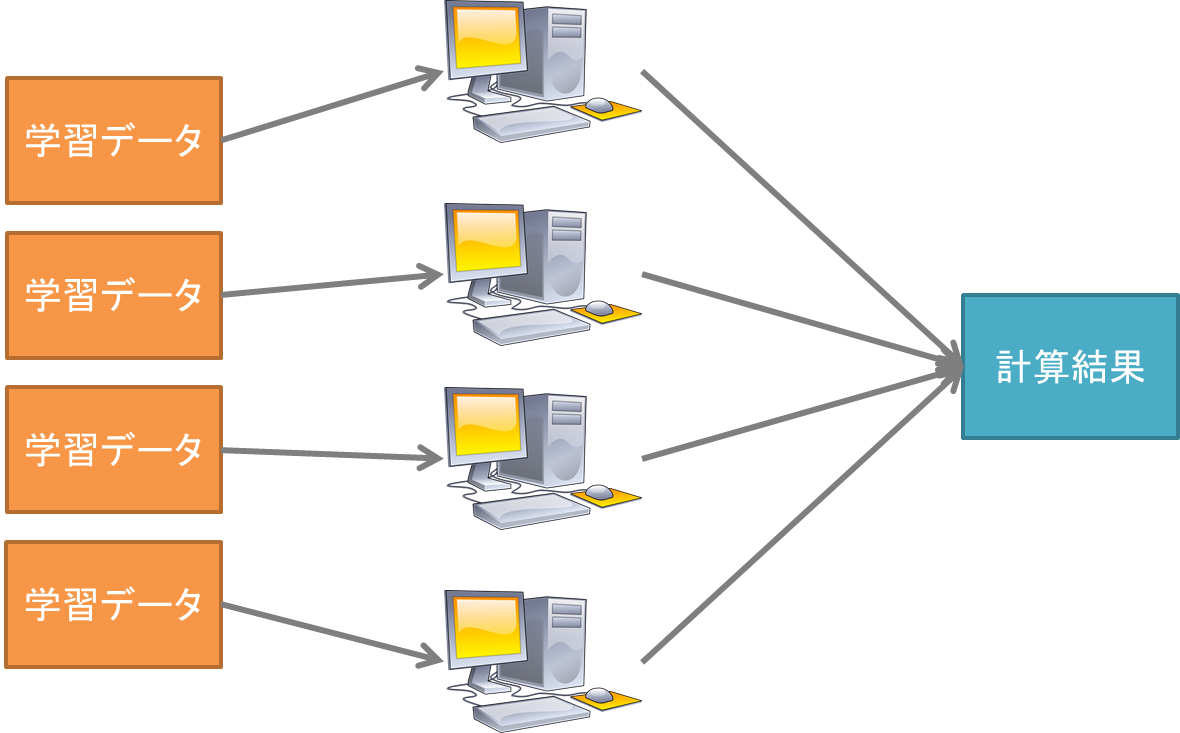
これは,Map-Reduceのアイディアでもある.
このやり方は,1台のPCでマルチコアを使った並列プログラミングで実現することも可能である.しかし,マルチコアで計算させる実装はライブラリ内ですでに実装されていることもあるため,確認が必要とのこと.
まとめ
大量データを使って学習させようとするとき,$\sum$など計算自体が分割できるものがあれば,工夫して複数台で計算させるというMap-Reduceの方法がある.(これを実装しているフレームワークはHadoopが有名なのかな?)
複数台に分散させるときは通信のオーバーヘッドがあるため,単純にN分の1にならないことが多い.また,1台でマルチコアを利用する場合でも,使用言語のライブラリですでに実装されいるか確認しておく必要がある.