
LOD(Linked Open Data)の公開のためには、そのデータを含む SPARQL エンドポイントが常にアクセス可能になっていることが望ましいのですが、SPARQL エンドポイントとそのバックエンドの RDF ストアをウェブ上で運用するには通常なんらかのコストがかかってしまいます。しかし、Oracle Cloud を使えば無料でこれを運用することができます!
以前に投稿した こちらの記事 では Oracle Cloud の Always Free Cloud Services を利用して SPARQL エンドポイントを構築する方法を紹介しました。ただし、その方法では WebLogic の上でエンドポイントを動作させるため、商用利用の際には WebLogic の有償ライセンスが必要になってしまっていました。
今回、2022年10月にリリースしたバージョン 22.4 では新たに Tomcat を用いたマーケットプレイス・イメージを用意しました。こちらをお使いいただくことで、利用用途に関わらず無償で継続利用いただくことができます。もちろん、Always Free Cloud Services 自体は SLA とサポートの対象外 なので、商用本番利用においては有償のサービスをご検討ください。
準備
まず、以下を用意しておきます。パスワードは同じものを使用することも可能です。
- Oracle Cloud のアカウント
- SSH key pair (private key と public key)
- 2 つのパスワード
-
<password_1>: RDF Server 管理ユーザー用 -
<password_2>: DB 管理ユーザー用
-
ネットワークの作成
次のように画面を進み、SPARQL エンドポイント用のネットワークを作成します。Oracle Cloud のネットワークは詳細に設定が可能ですが、ウィザードを使うことで基本的な構成を簡単に作成できるため、今回はそれを使用します。
Oracle Cloud console
> Networking
> Virtual Cloud Networks
> Start VCN Wizard
> Create VCN with Internet Connectivity
> Start VCN Wizard
- Configuration
- VCN NAME:(ここでは
VCN1とします) - その他の項目: 変更の必要なし
- VCN NAME:(ここでは

VCN1 に作成されたパブリック・サブネットに対して次のルールを新しく追加して、4040 ポートを外部からアクセス可能にします。
Oracle Cloud console
> Networking
> Virtual Cloud Networks
> VCN1
> Public Subnet-VCN1
> Default Security List for VCN1
> Add Ingress Rules
- Add Ingress Rules
- Source CIDR:
0.0.0.0/0 - Destination port range:
4040 - Description:
For SPARQL Endpoint
- Source CIDR:

エンドポイント管理サーバーの作成
エンドポイント管理サーバー(RDF Graph Server and Query UI)は、マーケットプレイス・イメージとして配布されているので、次のように画面を進み「RDF」というキーワードが含まれるイメージを検索します。
Oracle Cloud console
> Marketplace
> All Applications

ここで「Oracle RDF Graph Server and Query UI」という名前のイメージが 2 つ表示されます。価格が「Free」と表示されているものは Tomcat を、一方「BYOL (= bring your own license)」と表示されているものは WebLogic を使っていますので、ここでは「Free」と表示されているものを選択します。
- Image
- Name:
Oracle RDF Graph Server and Query UI - Version:
22.4.0
- Name:

「Launch Stack」から設定に進みます。「Stack information」は変更する必要はありません。「Configure Variables」のページで以下を設定します。
- Compute Instance
- Resource name prefix: 任意の名前
- OCI compartment: お使いのコンパートメント
- Server available domain: 任意のドメイン
- Server shape:
VM.Standard.E2.1.Micro(Always Free で使用可)
- Add SSH keys
- SSH public key: お持ちの公開鍵 (e.g.
ssh-rsa AAAAB3NzaC...)
- SSH public key: お持ちの公開鍵 (e.g.
- Instance Network
- Virtual cloud network compartment: お使いのコンパートメント
- Existing virtual cloud network: 上で作成された VCN
- Subnet compartment: お使いのコンパートメント
- Existing subnet: 上で作成された VCN の public subnet
- Advanced Configuration
- Administrator User Name:
admin - Administrator Password:
<password_1>
- Administrator User Name:

インスタンスの作成には数分かかります。
作成完了後、ログ出力に新しいインスタンスの IP アドレスが表示されるので、これを控えておいてください。IP アドレスは後からコンピュート・インスタンスのページで確認することもできます。

エンドポイント管理サーバーへのログイン
作成されたエンドポイント管理サーバーにアクセスします。
- URL:
https://<ip_address>:4040/orardf
自己署名証明書が使われているため、セキュリティ警告が表示されます。
- Chrome: "thisisunsafe" とタイプします
- Firefox: Advanced > Accept the Risk and continue
イメージ起動時に指定したパスワードでログインします。
- User:
admin - Password:
<password_1>

ログインできましたが、この時点ではエンドポイント管理サーバーはデータベースに接続されていないため、クエリ対象となるデータソースはありません。

データベースの作成
次のように画面を進み、データベースを作成します。このデータベースは Autonomous Database と呼ばれるフル・マネージド・サービスです。
Oracle Cloud console
> Oracle Database
> Autonomous Database
> Create Autonomous Database
- Configure the database
- Display name:
<db_name>(ここではADB1とします) - Database name:
<db_name>(ここではADB1とします) - Workload type:
トランザクション処理 - Deployment type:
共有インフラストラクチャ - Database version:
19cor21c - Password:
<password_2> - Choose network access:
Secure access from allowed IPs and VCNs only
- Display name:
ここで、先に作成したエンドポイント管理サーバーからアクセスができるように IP アドレスを入力しておき、簡単のため「Wallet」の設定なしに接続ができるようにチェックを外したままにしておきます。

すぐにデータベースが作成されます。

データベースへの接続
エンドポイント管理サーバーからデータベースへの接続を作成するため、Autonomous Database の管理画面から接続文字列を取得します。

ポップアップされた画面の「Connection Strings」という欄にて「TLS Authentication」を 必ず「TLS」に切り替えてから リストされたいずれかの接続文字列(ここでは adb1_medium のもの)をコピーします。

次に、この接続文字列を設定するため、エンドポイント管理サーバーに SSH でログインします。
$ ssh -i <private_key> opc@<ip_address>
まず、グローバル・リソースを server.xml に追記します。
$ cd /u01/app/tomcat/orardf/base/instance1/conf
$ vi server.xml
<GlobalNamingResources> の直下に <Resource> 要素を追加します。url は上でコピーした文字列を <password_2> はデータベースの管理ユーザーのものを記載してください。
...
<GlobalNamingResources>
<Resource name="jdbc/ADB1" auth="Container" global="jdbc/ADB1"
type="javax.sql.DataSource" driverClassName="oracle.jdbc.driver.OracleDriver"
url="jdbc:oracle:thin:@(description= (retry_count ... ssl_server_dn_match=yes)))"
username="admin" password="<password_2>" maxTotal="20" maxIdle="10"
maxWaitMillis="-1" />
...
次に、リソース・リンクを context.xml に追記します。
$ cd /u01/app/tomcat/orardf/base/instance1/conf
$ vi context.xml
<Context> の直下に <ResourceLink> 要素を追加します。
...
<Context>
<ResourceLink name="jdbc/ADB1"
global="jdbc/ADB1"
auth="Container"
type="javax.sql.DataSource" />
...
エンドポイントを再起動します。
$ sudo systemctl restart tomcat_orardf
エンドポイント管理サーバーの設定画面の Data sources タブからデータベースへの接続を作成して、Wallet をアップロードします。

JNDI Name として上で作成した jdbc/ADB1 を選択して、任意のデータソース名(ここでは ADB1)を入力します。

データソースが作成されると「Data」タブでこれを選択することができます。この時点ではデータソースにはまだ RDF network がありません。

RDF データのアップロード
ここでは、W3C のサイト(https://www.w3.org/TR/turtle/)に掲載されている次のサンプル・データをロードしてみます。
@base <http://example.org/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix rel: <http://www.perceive.net/schemas/relationship/> .
<#green-goblin>
rel:enemyOf <#spiderman> ;
a foaf:Person ; # in the context of the Marvel universe
foaf:name "Green Goblin" .
<#spiderman>
rel:enemyOf <#green-goblin> ;
a foaf:Person ;
foaf:name "Spiderman", "Человек-паук"@ru .
Data タブで先に登録したデータ・ソース (e.g. ADB1) を選択して、ここに RDF Network を作成します。ここで、Oracle Database における RDF Network とは、表や索引のセットからなる論理的な RDF ストアのことで、データベース上には RDF Network を複数作成することができます。

- Network owner:
ADMIN - Network name: 任意の RDF Network 名 (e.g.
NETWORK1) - Tablespace:
DATA

Data タブで先に作成した RDF Network (e.g. ADMIN.NETWORK1) を指定し、Import タブの Upload data アイコンをクリックして、ファイルをステージング表にアップロードします。

- Upload:
example1.ttl - Staging table: 任意の表名 (e.g.
EXAMPLE1_TABLE) - Overwrite: false (既存の表を使いたい場合には上書きしても OK)

最後に、Import タブの Bulk load data アイコンをクリックして、ステージング表のデータを Model にロードします。ここで、Oracle Graph における Model とは、RDF Network 内のトリプルの集合の管理単位のことで、SPARQL クエリの対象として Model を指定したり、Model を束ねた Virtual Model を定義するといったことが可能です。

- RDF Data
- Model: 任意のモデル名 (e.g.
EXAMPLE1_MODEL) - Staging table owner:
ADMIN - Staging table: 上で作成したステージング表 (e.g.
EXAMPLE1_TABLE)
- Model: 任意のモデル名 (e.g.
- Options
- 全ての項目: 変更不要
- Event Trace
- 全ての項目: 変更不要

SPARQL クエリの実行
まずは、エンドポイント管理サーバーのクエリ UI 上で SPARQL クエリを実行してみます。
クエリ対象のモデル(ここでは EXAMPLE1_MODEL)を右クリックし「Open」からエディタを開きます。

Execute ボタンをクリックして、デフォルトで入力されている SPARQL クエリを実行してみると、結果として格納されているトリプルが表示されます。

こちらは、Spiderman という名前のヒーロー(変数 ?h)の敵(?e)の名前(?e_name)を検索するクエリです。
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX rel: <http://www.perceive.net/schemas/relationship/>
SELECT ?e_name
WHERE {
?h foaf:name "Spiderman" .
?e rel:enemyOf ?h .
?e foaf:name ?e_name .
}
LIMIT 500
Green Goblin が返されました!

エンドポイントの公開
この時点では、SPARQL エンドポイントはまだ公開されていません。エンドポイントの公開を可能するために、まず設定画面からこれを許可してデータ・ソース(ここでは ADB1)を選択します。
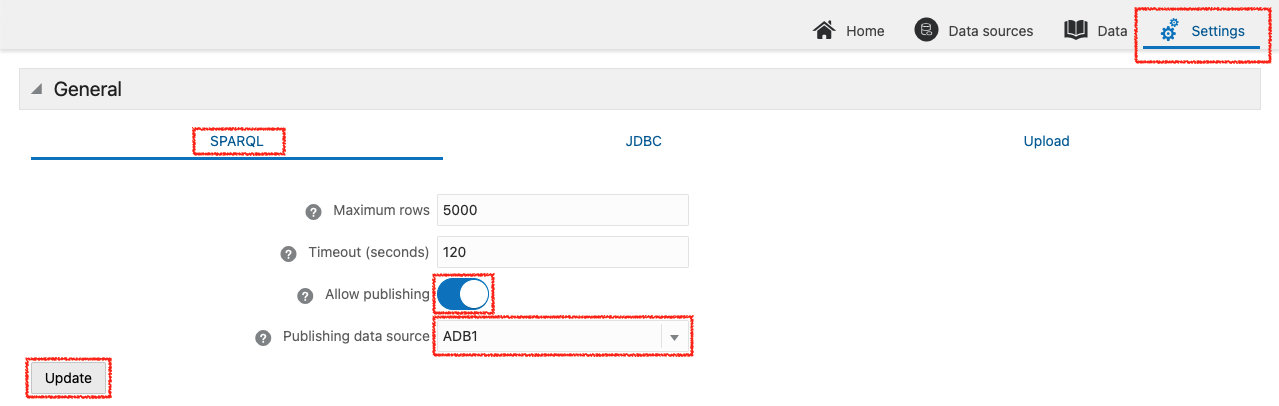
公開するモデルを右クリックして Publish を選択します。エンドポイント URL に使用するデータセットの名前(ここでは example1)を入力します。
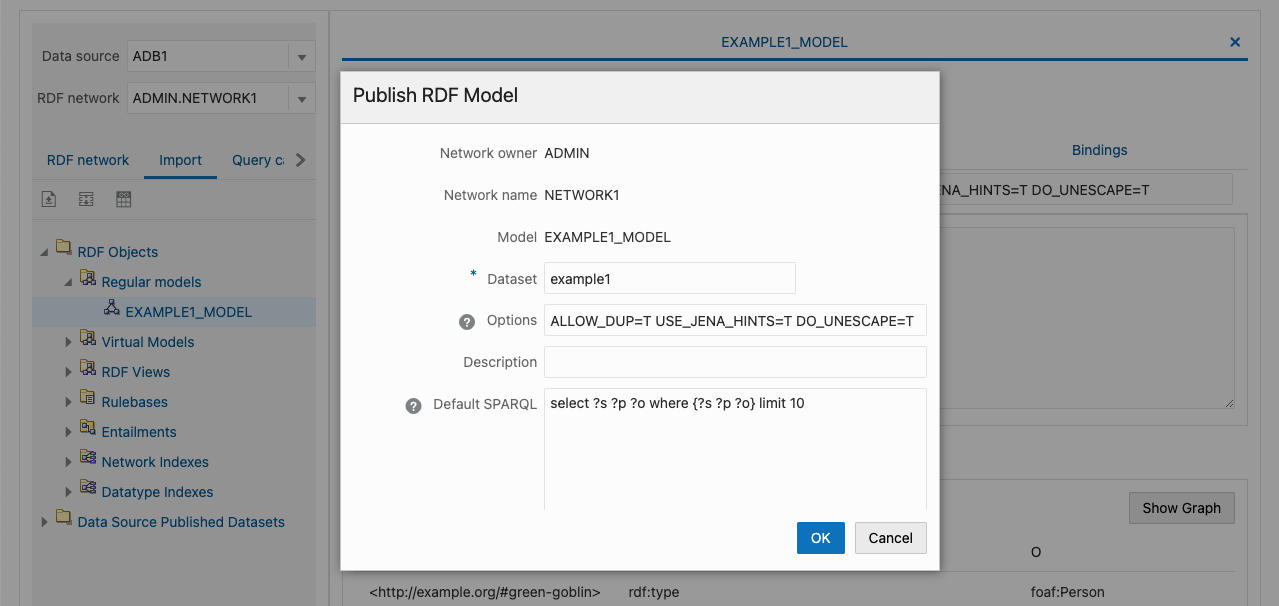
以下のようなエンドポイント URL が表示されるのでこれを保存しておきます。
https://<ip_address>:8001/orardf/api/v1/datasets/query/published/example1

REST でエンドポイントにアクセス
GET もしくは POST を使ってエンドポイントに対して SPARQL クエリを発行してみます。まず、上でも用いた SPARQL クエリをファイルに保存しておきます。
sparql.rq
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX rel: <http://www.perceive.net/schemas/relationship/>
SELECT ?e_name
WHERE {
?h foaf:name "Spiderman" .
?e rel:enemyOf ?h .
?e foaf:name ?e_name .
}
LIMIT 500
このファイルを指定して POST リクエストを実行します。ここでは自己署名証明書を使っているため --insecure オプションを指定してこれを許可しています。
$ curl https://<ip_address>:8001/orardf/api/v1/datasets/query/published/example1 \
--data-binary @sparql.rq --insecure -X POST
結果はデフォルトでは W3C 標準 の JSON 形式で返されます。
{
"head": {
"vars": [
"E_NAME"
],
"links": []
},
"results": {
"bindings": [
{
"E_NAME": {
"type": "literal",
"value": "Green Goblin"
}
}
]
}
}
参考: データ・ロード時にグラフ名を指定
RDF データをロードする際に、それらのトリプルのグラフ名を一括して設定し、クアッドとしてロードしたい場合があります。その場合には、トリプルをステージング表にアップロードした後に、その表にグラフ名を追加したビューを作成して、これを RDF モデルにロードします。
まず、Create RDF Network で説明しているとおりに、データをステージング表にアップロードします。
- Upload:
example1.ttl - Staging table: 任意の表名 (e.g.
EXAMPLE1_TABLE) - Overwrite: false (既存の表を使いたい場合には上書きしても OK)
SQL を実行するため Database Actions を開きます。
Oracle Cloud console
> Oracle Database
> Autonomous Database
> 作成した ADB を選択
> Tools
> Open Database Actions
次の SQL クエリを実行してビューを作成します。この際、指定したいグラフ名で <http://example.org/graph1> を置き換えてください。
create view SAMPLE_VIEW as
select
RDF$STC_SUB
, RDF$STC_PRED
, RDF$STC_OBJ
, '<http://example.org/graph1>' as RDF$STC_GRAPH
from SAMPLE_TABLE
SPARQL エンドポイントに戻り、Import タブの Bulk load data アイコンをクリックして、作成したビューから新しいモデルへとデータをロードします。

- RDF Data
- Model: 任意のモデル名 (e.g.
EXAMPLE1_MODEL) - Staging table owner:
ADMIN - Staging table: 上で作成したステージング表 (e.g.
EXAMPLE1_VIEW)
- Model: 任意のモデル名 (e.g.
- Options
- 全ての項目: 変更不要
- Event Trace
- 全ての項目: 変更不要
次の SPARQL クエリでグラフ名が結果に含まれることを確認できます。
SELECT *
WHERE { GRAPH ?g { ?s ?p ?o }}
LIMIT 500
※ 冒頭画像 Photo by Cristian Escobar on Unsplash