はじめに
こんにちは!
NTTデータ ペイメント事業本部 カード&ペイメント事業部デジタルペイメント開発室の、チーム tonttu です!
私たちのチームは決済中継サービスの非機能改善やインフラを担当しています。
プロジェクト概要は以下記事に記載があるので、気になる方は目を通して見てください。
今回、私たちは8月に福岡で開催された CloudNative Days Fukuoka 2023 へ参加してきました。
当日はオンライン/オフラインのハイブリッド開催で、3つのトラックに分けられた約20ものセッションがあり、とても学びが多い1日でした。
そこで、tonttu チームから現地参加した若手4名がそれぞれ印象に残ったセッションについてまとめてみました!
AIへの接し方とK8sGPTについて
✏️ セッション試聴後の要約・まとめ by 松井
こんにちは松井です。
私は当日AI系のセッションに複数参加し、中でも印象的だった2つのセッションについての概略を書き、最後に一言書きたいと思います。
セキュアな開発にgenerative AIを活用できるのか?AIセキュリティの米国最新情報をお届け!
脆弱性管理ツール Snyk 米国本社の Ravi Maira さんのセッションです。
セッションは英語でしたが、同時通訳もありました。
コードを書くのはAI?デベロッパー?
皆さんは CodeWhisperer というサービスを知っていますでしょうか。
これは AWS が提供する AI コーディング支援サービスです。デベロッパーが開発するよりも CodeWhisperer を使った方が早く開発できるという調査結果もあるとのことです。
ただ、セキュアなコードについては AI が書くよりもデベロッパーで書いた方が良いという調査結果があるにも関わらず、デベロッパーは AI が書いたほうがセキュアだと思いこんでいるとのことです。
コメントを加えたり、サマリーを提供したり、リファクタリングするといったレベルは低リスクで使用することができますが、コードの生成レベルになるとリスクが高くなると仰っていました。
AI Hallucinates
AI はとても便利なので有効に使うべきだが、AIが間違っていると思えるのは人間なので、信頼せず検証を行う必要がある。
GPT4 / GPT3.5 / Bird を対象に脆弱性テストを行ったところ、GPT4だけが気づいた項目があったり、正答率が50%を切るような場面もあった等の事例を見していただきました。
最後に、AI のことを手早いけど経験値が低い若手のデベロッパーとして扱い、すべてを疑おうと印象的な発言もありました。
K8sGPT Deep Dive: KubernetesクラスタのAI駆動型分析について
https://speakerdeck.com/nwiizo/k8sgpt-deep-dive-kuberneteskurasutanoaiqu-dong-xing-fen-xi-nituite
株式会社スリーシェイクの@nwiizoさんのセッションです。
ChatGPTが世に出てからAIへの関心が世界的に広がり、GPTという言葉はIT企業に努めていない友人でも知っているレベルになりました。そんな中「K8sGPT」という文字をセッション一覧で見かけたので気になり申し込んでみました。
K8sGPTとは
K8sGPT は Kubernetes クラスタ内の問題を探索し、評価、解説するためのツールです。
システム信頼性エンジニアリング(SRE)の専門知識が組み込まれているため、テクニカルな知識に自信がない人でも容易に使うことができるようです。
実行自体は本当にシンプルでk8sgpt analyzeというコマンドを叩くだけで実行できるとのことです。
K8sGPT のようなツールは一般的に AIOps(AIによる運用) と言われており、自動化や効率化、予防的な問題解決を可能にすることでIT運用のパフォーマンスと信頼性を向上させていると話がありました。
AIOpsとは
AIOps は Artificial Intelligence for IT Operations の略で2016年に Gartner によって名付けられたサービス運用を改善するテクノロジーの総称です。
AIOpsシステム は IT 運用の様々な領域/レイヤーをカバーしていますが、主に監視(Monitoring)、分析(Analytics)、自動化(Automation)の3つの領域から成り立っています。
この3つの領域に K8sGPT の仕組みを紐付けると以下のようになります。
AIOpsツールとしてのK8sGPT
■Observe(Monitoring)
データの取り込み方法としては以下2種類がある。
- k8sgpt CLI
- クラスタに接続する必要はあるが、分析はコマンドのみで実行可能
- k8sgpt Operator
- クラスタにデプロイする必要はあるが、分析はデプロイ後に自動で行われる
K8sGPT と K8s Operatorの連携による運用管理が有効そうです。
■ENGAGE(Analytics)
K8sGPTはデフォルトプロンプトしか受け取らないようになっているが、将来的には上書きできそうとのことです。
この説明では「Prompt Engineering」というワードも出てきました。
「Prompt Engineer」という職業が一般的になるのも遠くない未来な気がしました。
default_prompt = `Simplify the following Kubernetes error message delimited by triple dashes written in --- %s --- language; --- %s ---.
Provide the most possible solution in a step by step style in no more than 280 characters. Write the output in the following format:
Error: {Explain error here}
Solution: {Step by step solution here}
`
https://github.com/k8sgpt-ai/k8sgpt/blob/main/pkg/ai/prompts.go
■ACT(Automation)
AnalyzeCmd という名の cobra コマンドが定義されており、コマンドが実行されると Run 関数内のコードが実行されます。このコードは GetAIResults を開始し、結果を取得して表示するというような処理になっているようです。
- 幻覚(hallucination)による実行能力の欠如
大規模言語モデルは実在しない情報を生み出すことがあり、専門家はこの現象を幻覚と呼んでいます。この不正確な情報が専門家や一般の人々にとっても紛らわしく、真実との見分けがつかないことがあります。
このような理由があり、K8sGPTは幻覚を実行してしまう可能性があるため、Execution機能がないとのことです。
問題を発見したあとに自動で復旧してくれれば開発者としては楽ですが、現実的には難しそうですね。
今回セッションを聴講して、AI への関心やツールやものすごい勢いで増えていること、AIの扱い方の大切さを再認識しました。
AWS CodeWhisperer だけでなく、8月末には Google Cloud から Duet AI の発表もあり、今後益々 AI を活用したツールやソリューションが登場することが予想されます。これらの情報を常にキャッチアップし、自分の業務にどう活かせるかまでを考えることが非常に大切だと感じました。
また、AI を信頼しきるのではなく、「道具」として扱うことを意識していきたいと思いました。私の所属する部署でも GPT を使うことができ、私もよく使っています。直近では Apache Beam の Pipeline を Python で書く必要があったのですが、私は Apache Beam に対する知見は全く無く、 Python も基本レベルの知識しかありませんでした。しかし、GPT を活用することで、やりたいことの基本的な雛形を簡単に作成することができました。存在しないモジュールを参照している等 100% そのまま使えるといったコードではありませんでしたが、生成結果を参考に開発を進めることができました。このように、今後も GPT の回答結果を 100% 信じず、あくまで 参考情報として活用していきたいと思います。
「Gateway API と eBPF で進化する GKE Networking」を聞いて、Networkingの理解と学びのきっかけを掴む
✏️ セッション試聴後の要約・まとめ by 石田
はじめに
こんにちは!
本セッションではGateway APIとGKEでの実装ケース、また、eBPFを活用したDataplane V2の紹介がされています。
普段kubernetesやGKEを利用していると、どこかで聞いたことがあるような気がするワードだけどなんだか良くわからないな、という方もいるかもしれません。(私がそうでした。)
私は今年度からGKEを扱うプロジェクトで初めてインフラ部分を主に担当する業務にアサインされたものの、既にNetworkingは構築済みだったこともあり、あまり深く理解出来ていない状態だったので、このセッションを機にNetworkingに興味を持ちました。
元々GKEに触れていてNetworkingに興味がある方はもちろん、興味はあるけどまだ良くわかってないんだよね、という方にもおすすめです!
※CNDF2023の公式ページにアーカイブ配信と資料が公開されているのでぜひそちらもご覧ください。
https://event.cloudnativedays.jp/cndf2023
GatewayAPIについて
Gateway APIとは、サービスを外部公開する際に利用するIngressの進化版であり、従来のIngressで抱えていた課題を解決する以下のような機能を備えています。
- ロール志向なリソースモデル
- ヘッダーベース ルーティングや重み付けベースのトラフィック分割などの多くの機能を提供
- Custom Resourceによる高い拡張性
ロール志向なリソースモデルとは?
従来のIngressでは、基本的に単一リソースで構成されているために、各NamespaceやアプリケーションごとにIngressが作成され、クラスタ管理者側で管理が困難であるという課題がありました。
さらに、IngressではIPアドレスの管理や証明書が必要であり、開発者側でインフラ寄りのタスクを担う必要があるケースもありました。
そこでGatewayAPIでは、複数リソースから構成されることで、インフラプロバイダ、クラスタ管理者、開発者などロール毎に操作可能なリソースを制限することが出来るので、権限の分離が行えるようになりました。
公式Docはこちらです。
また、gateway APIでは、namespaceを跨いで複数のサービスにルーティングさせる、ということも可能なので、セキュリティの向上とともにリソース管理もしやすくなります。
Custom Resourceによる高い拡張性とは?
Gateway APIでは以下のリソースタイプがあります。
- GatewayClass
- Gateway
- HTTPRoute
GatewayClassリソースとは、ロードバランサの種類などを定義するリソースです。マネージドKubernetesを利用する場合はクラウドプロバイダーが提供するGatewayClassから選ぶ流れになります。
GKEでは現在10種類のGatewayClassが提供されているようですね。
https://cloud.google.com/kubernetes-engine/docs/concepts/gateway-api?hl=ja#gatewayclass
Gatewayリソースとは、利用するロードバランサのGatewayClassNameを指定したり、トラフィックを受け付けるIPアドレスやプロトコル、TLS終端の設定などを定義するリソースになります。
また、アタッチを許可するリソースやNamespaceを指定することも出来ます。
HTTPRouteとは、HTTPトラフィックのルーティングを定義し、ホスト名やルーティングの条件などを設定することが出来ます。
上記のGatewayAPIが持つヘッダーベースルーティングや重み付けベースのトラフィック分割といった機能はこのHTTPRouteで設定します。
本セッションの配布資料にはGatewayAPIをGKEで実装する場合のイメージ図も描かれており、非常にわかりやすいので是非参照してみてください!
Istioで似たような機能を見たことがあるぞ?
なんて思った方もいるんじゃないでしょうか。私がそうでした。
Istioなどのサービスメッシュを利用していると、重み付けルーティングだったり、パスベースルーティングの設定をVirtualServiceに定義しますよね。
このようにサービスメッシュプロダクトでもGatewayAPIをサポートしています。
マルチクラスタGatewayもあります
マルチクラスタGatewayを用いると、1つのGatewayを用いて2つのクラスタにトラフィックを制御することも出来ます。
大規模なサービスを提供する組織にはとても便利そうですね!
Dataplane V2について
Dataplane V2とは、従来のiptables/Calicoベースのデータプレーンに代わる次世代のネットワークデータプレーンであり、高いパフォーマンスとスケーラビリティがあるそうです。
eBPF/Ciliumベースに実装されることで、kube-proxyを利用せず、iptablesによるボトルネックが解消してるそうです。
また、Observabilityやセキュリティ関連の機能も提供されています。
FQDN Network Policy (Public Preview)
従来のNetwork Policyでは、宛先がクラスタ外の場合はIPアドレスを指定していましたが、この機能を用いることでFQDNによるNetwork Policyが設定可能となり、
さらに、ワイルドカードもサポートされているため、非常に使い勝手が良くなっていますね。
以下の公式DocにFQDN Network Policyのマニフェストの例があるので参照してみてください。
Dataplane V2 Observability (Public Preview)
こちらは、Trafific flowsの収集や可視化機能です。
この機能を用いることでサイドカーを用いずともサービストポロジーの可視化が出来るようになります。
以下の公式Docにてトラフィックフローの可視化された様子が分かるので参照してみてください。
https://cloud.google.com/kubernetes-engine/docs/how-to/observe-your-traffic?hl=ja
自プロジェクトでの活用や今後について
GKEクラスタのアップグレードを定期的に行うのですが、現在はIn-Placeで実施しているためメンテナンス時間を設けています。
そこで、マルチクラスタGatewayを用いて、Blue/Greenデプロイメントにて実施することで、ダウンタイム無しでトラフィックの切り替えや、万が一の際のロールバックも出来るのではないかなと感じています。
ぜひ今回学んだ知識を活かして色々と検証環境で試してみたいなと思います。
更に後半のFQDN Network PolicyやDataplane V2 Observabilityも試してみたいところですが、GKEのバージョンが1.26.4-gke500以降のクラスタが必要であり、対応した環境をまだ持っていないため、準備でき次第検証してみたいと考えています。
「メルカリにおけるプラットフォーム主導のK8sリソース最適化とそこに生まれたtotiseの可能性」を聞いて、自Projectのリソース最適化を考える
✏️ セッション試聴後の要約・まとめ by 鳥海
Sessionの要約・感想
要約
- k8s上ではAutoScaler等がいい感じにNodeやpodのリソースを調整してくれる
⇨ これにはいくつかの戦略があるが、お金と安全性のトレードオフである
例えば、Nodeのスペースに常に余裕を持つことで、リソースの急増、障害等には強くなるが、その分お金がかかる。 - ただクラスター上の全てのsvcにHPAを適応すればいいのかというと、そうではなくVPA等もうまく利用しないと本当に最適化されない
⇨ 例えばsideCarがある場合、sideCar側のCPUが先にlimitに近づくとHPAによりPODが増えるがもう一つのコンテナではCPUに余裕がある。この時本当に必要なのはVPAによりどちらかのCPUを増減し、どちらのコンテナもほぼ同時にlimitに近づくように調整すること。 - 上記の経験からメルカリではHPAとVPAですべてうまく最適化できるよう、workloadを開発中。※開発中なので商用での利用は不可
https://github.com/mercari/tortoise
感想
- Autoscalingの条件などをあまり深く意識したことがなかったので、参考になった
- 今後顧客が増える見込みもあるので、自Projectでも活用できそう!!!
そもそもAutoScaleとはどんなもの?
PodのHorizontal Pod Autoscaling
- pod内の各コンテナの負荷に応じて自動的にpodの数を増減させる機能のこと
- 任意のtarget値(CPU, Memory)に近づけるようにスケーリングを行う
- スケーリングは定期的にメトリクスを取得したのちに行われるので、即時的には行われない(ただしVPAよりも即時的)
- custom metoricsを利用すればリソース以外の要素でもスケーリング可能
Resource, Pods, Object, Externalなど
PodのVertical Pod Autoscaling
- pod内のリソースの使用量に応じて、podのリソースを増減させる機能のこと
- Pod を時系列でモニタリングし、Pod が必要とする CPU とメモリリソースの最適な量を割り出す
⇨ メモリリソース使用率が定常的に低い場合、より小さなメモリリソースでpodを再作成する
NodeのHorizontal Autoscaling(クラスタオートスケーラー)
- スケージュールされたpodや削除されたpodに応じて、nodeの数を増減し最適化する機能のこと
- クラスター内に二種類以上のマシンタイプがある場合、需要に対してもっとも低価格なnodeを選択する
- nodeのスケールダウン時にpodが一台もなくならないためにはPDBの設定が必要
自Projectの現状ではどうしてる???
- 現状OutScale系は利用してない Nodeでは利用なし、PodではHPAはごく少数
⇨そもそも利用者が少なく、ピークになるようなアクセスが生じない - Podのリソースはどう決めている?
⇨ request: tes環境等での平均利用状態から2の冪乗で一番近い値 (どの状態を平均利用状態と定義しているかは不明)
limit : 上記の4倍の値? (4倍と記載あったが本当かは不明) - 上記の値はリリース初期から継続されている値
⇨ リリース初期は分からないのでしょうがない部分もあるが、今後ユーザーが増えていくので改善の余地あり - サービスなどによりかなり様々であるが、CPU, Memoryともに、定常的にrequestよりも低い状態のものも多い。
一方でlimitはかなりでかい、ここまで利用することはなさそう。
ex) 9/1~9/14の2週間での平均
| front系 Aサービス | Request | Limit | Useage | コメント |
|---|---|---|---|---|
| main container CPU |
32m | 2.00 | request値に対して 2.99% |
× request値よりかなり低いのでもっと少なくても良い |
| main container Memory |
128MiB | 1GiB | 148MiB | ○ ほぼ定常的に少しだけrequest値を超えている |
| istio-proxy CPU |
100m | 1.02 | request値に対して 5.93% |
× request値よりかなり低いのでもっと少なくても良い |
| istio-proxy Memory |
128MiB | 512MiB | 116MiB | ○ ほぼrequest値通り |
今後自Projectではどうすべきか?
- 過去、現状の利用者でのアクセス解析はできるはずなので、再度request値などを見直したほうが良い
- またCPUのリソースに対してMemoryが大きすぎるとガベージコレクションによりCPUThrottlingが発生したり、特定のSVCでOOMKが発生するなど、Podリソースに対しての問題がいくつか露見してるので、Project全体としてもナレッジを蓄積していきたい。
- また今後加盟店、ユーザーが大幅に増えるためスケールの設定は入れる余地あり
⇨ 実際にユーザー増加後grafanaで数ヶ月分解析し、実際に必要か検討すべき
参考
https://cloud.google.com/architecture/best-practices-for-running-cost-effective-kubernetes-applications-on-gke?hl=ja#fine-tune_gke_autoscaling
https://kubernetes.io/ja/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
https://qiita.com/sheepland/items/37ea0b77df9a4b4c9d80
「継続的プロファイルによる大規模アプリケーションの性能改善」を聞いて
✏️ セッション試聴後の要約・まとめ by 逆井
■ はじめに
こんにちは!逆井(さかさい)です。
こちらのパートでは、@ymotongpoo さんのセッションで学んだことをまとめていきます。
本セッションでは、オブザーバビリティにおける Primary Signals の一つであるプロファイルと、プロファイルを継続的に計測することでアプリケーションの性能を理解し改善する方法についての手法が丁寧に説明されています。
アプリケーションのパフォーマンスに課題を感じていたり、オブザーバビリティ主要な3本柱(これは旧来の呼称です。いまはプロファイルやダンプも含めて Primary Signals と呼ばれます。)しか扱ってない場合、多くの知見を獲得できるので一度観ることをオススメします!
セッションから学んだプロファイルや継続的プロファイルについてを簡単に記し、OSS のプロファイラーである Grafana Pyroscope を使ったプロファイルの計測についてご紹介したいと思います。
※ セッションでは、Cloud Profiler を用いてプロファイルの計測をデモンストレーションされています
■ プロファイルと継続的プロファイルについて
プロファイルは、プログラムを実行する際に取得できるリソースのデータ(一定期間サンプリングされたもの)です。
Go を使ったアプリケーションであれば、runtime/pprof を使ってアプリケーションを計装することで、CPU 時間やメモリ割り当て、ロックなど様々なアプリケーションのプロファイルを計測することができます。
次に最近よく聞くようになってきた "継続的" プロファイルに述べます。
オブザーバビリティにおいて重要な要素の一つとして、テレメトリー(計測したデータ)を一元的に集約し続け、必要なときにいい感じで取り出して解析できるようにしておくことが挙げられます。
既存のモニタリングの考え方とは異なり、複雑化したクラウドネイティブなシステムにおいて、大量で多くのディメンションを持つテレメトリーを使って解析することで未知のトラブルにも対応できる状態が大事です。オブザーバビリティの考え方については、"O'Reilly Japan - オブザーバビリティ・エンジニアリング" で詳説されているので、気になる方は一読してみてください。
https://www.oreilly.co.jp/books/9784814400126/
少し脱線しましたが、プロファイルについても同様です。特定の時間パフォーマンスを測定するだけでは(だけでも、示唆はたくさん得られるとは思います)、突然不安定になったサービスを調査したい際に、気づいたときにプロファイルを始めても遅い場合があります。
従って、サービスのプロファイルを計測し続け、一元的に集約する "継続的プロファイル" が重要になります。これにより知りたいスナップショットでアプリケーションのパフォーマンスを確認したり、リビジョンごとの性能比較なども可能になります。
継続的プロファイルツールは、Google Cloud の Cloud Profilerや、Datadog の Continuous Profilerなど多くのオブザーバビリティベンダーがサービスを提供しています。OSS では以下で簡単に紹介する Grafana Pyroscope などがあります。
CNCF のブログで継続的プロファイルツールの歴史について語られていて楽しいので、興味のある方はご覧ください。(山口さんのセッションの中でも詳しく説明されています)
https://www.cncf.io/blog/2022/05/31/what-is-continuous-profiling/
■ Grafana Pyroscope を使ったプロファイルの計測
Grafana Pyroscope は Grafana Labs の継続的プロファイルプロジェクトです。
Grafana Labs にはもともと Grafana Phlare というプロジェクトがありましたが、2023/3 にPyroscope 社を買収し、Grafana Phlare と Pyroscope が統合され「Grafana Pyroscope」となりました。
2023/9 に v1.0.0 がリリースされ、注目している OSS プロジェクトの一つです!
https://grafana.com/oss/pyroscope/
■ アプリケーションへのプロファイル計装
プロファイルを取得するためには、アプリケーションに計装(テレメトリーを出力するように実装)する必要があります。(eBPF などを使ったテレメトリー収集の手法などもあり、その場合はその限りではありませんがここでは触れません。)
プロファイル計装自体はとても簡単で、Grafana Pyroscope が提供しているプロファイラー pyroscope-go を使えば良いです。内部的には上記の runtime/pprof を使って各種プロファイルを計測しています。
以下は、Go アプリケーションに、pyroscope-go を使ってプロファイル計測したサンプルコードです。
func main() {
// 環境変数からアプリバージョンを取得
appVersion := os.Getenv("APP_VERSION")
// profiling 設定
/* Mutex Profile 設定(オプション)
mutexProfileRate は Mutex Profile の収集される頻度です。
mutexProfileRate = 1 のとき全ての Mutex Event が収集されます。
mutexProfileRate > 1 のとき mutexProfileRate 回のうち 1 回 Mutex Profile が収集されます。
*/
mutexProfileRate := 1
runtime.SetMutexProfileFraction(mutexProfileRate) // ・・・(1)
/* Block Profile 設定(オプション)
blockProfileRate は Block Profile をサンプルする際の Block 時間(ns)です。
blockProfileRate = 0 のとき Block Profile が無効になります。
blockProfileRate > 0 のとき blockProfileRate n秒単位で Block ごとに Block Profile が収集されます。
*/
blockProfileRate := 1
runtime.SetBlockProfileRate(blockProfileRate) // ・・・(2)
pyroscope.Start(pyroscope.Config{
ApplicationName: "calculator",
// Pyroscope のエンドポイントを設定
ServerAddress: "http://pyroscope.pyroscope.svc.cluster.local:4040",
Logger: pyroscope.StandardLogger,
// タグを設定することで、タグ指定でのプロファイル表示や、タグ間のプロファイル比較ができ便利です
Tags: map[string]string{
"hostname": "calculator",
"version": appVersion,
},
ProfileTypes: []pyroscope.ProfileType{
// デフォルトで取得するプロファイル
pyroscope.ProfileCPU,
pyroscope.ProfileAllocObjects,
pyroscope.ProfileAllocSpace,
pyroscope.ProfileInuseObjects,
pyroscope.ProfileInuseSpace,
// オプショナルで取得するプロファイル
pyroscope.ProfileGoroutines,
// ・・・(1) の設定が必要
pyroscope.ProfileMutexCount,
pyroscope.ProfileMutexDuration,
// ・・・(2) の設定が必要
pyroscope.ProfileBlockCount,
pyroscope.ProfileBlockDuration,
},
})
...
プロファイルの設定についてはこの部分だけです。とても簡単ですね!
■ Grafana Pyroscope で可視化
このアプリケーションを稼働させて、数時間取得したプロファイルを可視化したものが以下のフレームグラフになります。可視化は Pyroscope の UI を使って簡単に確認することができます。
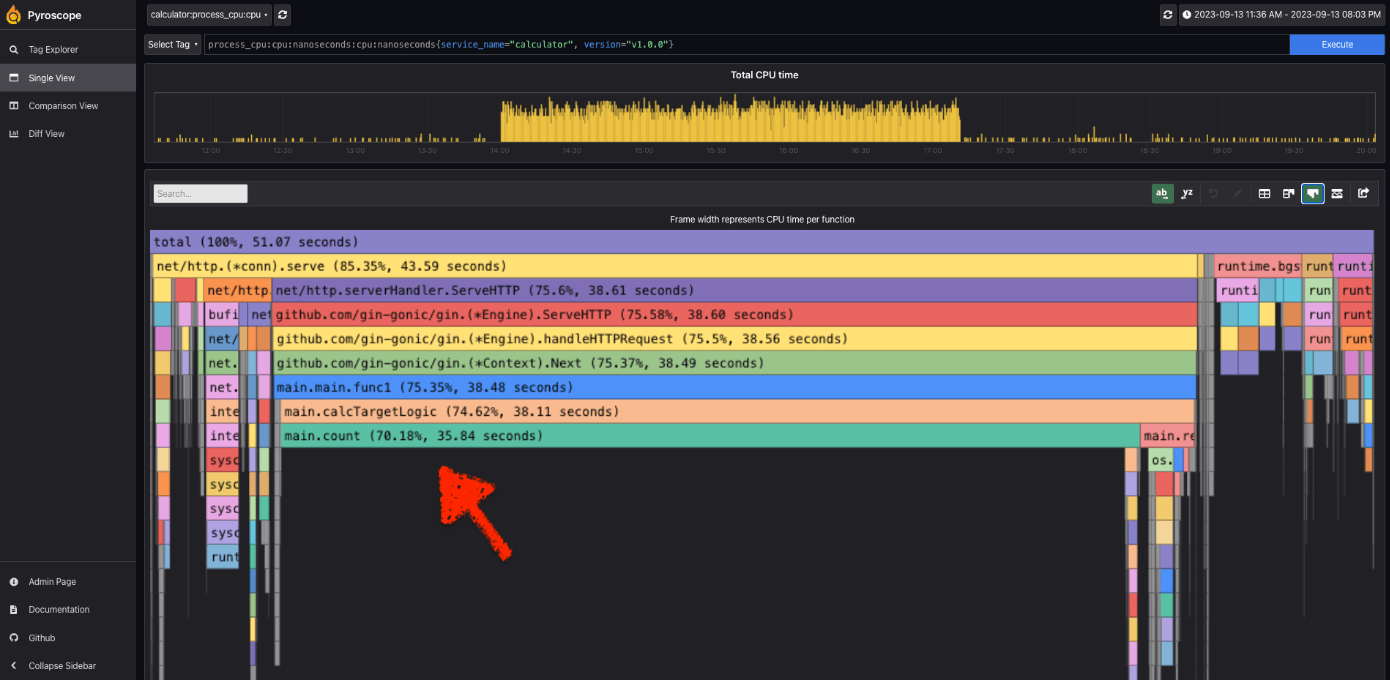
フレームグラフでは、横軸が計測したプロファイル(今回は CPU 時間をプロットしています。)縦軸が、リソース消費した関数のコールスタックとして表示されています。
この例では、main.count という関数で CPU 時間の約 7 割近くを消費していて、パフォーマンス改善の余地がありそうです。
このように、継続的プロファイルツールを使って簡単にアプリケーションの性能を計測・分析することができました。
この内容の本編は、Zenn の "Grafana Pyroscope を用いて Go のアプリケーションで継続的プロファイルしてみた" に詳細をまとめているので気になる方は合わせてご覧ください!ボトルネックの特定から、改善間で行ってみています。
https://zenn.dev/k6s4i53rx/articles/021a1d65af9e95
■ 最後に
プロファイルはオブザーバビリティにおいて重要なテレメトリーの一つです。(オブザーバビリティ4本目の柱 by Grafana Pyroscope。4 本目なのかは分かりませんが。)
本セッションを観ることでプロファイルの基礎知識から、なぜプロファイルが重要なのか、どのようにプロファイルを計測し分析できるかを網羅的に学べることができるかと思います。
ぜひ、皆さん、プロファイルをしてアプリケーションの性能改善をしていきましょう!
終わりに
今回はCloudNativeDaysの現地参加レポートを書いてみました。
私たちのような若手がこのような外部イベントに参加することを快諾してくれる環境に感謝し、今後も積極的に技術のキャッチアップをしていこうと思います!
最後まで読んでいただきありがとうございました。