みなさんこんにちは。
Saucy Dogにどハマり中の学生エンジニアです。
内定者インターンでwordcloud(ワードクラウド)を使って実装を行なったので、そのアウトプットとして記述していきたいと思います!
準備
今回は、GoogleColabを使ってwordcloudの実装を行なっていきます。
(GoogleColabは環境構築が不要で、ブラウザ上でPythonを実行できます。)
①ドライブをマウントする
まず、下記のコードを実行してマイドライブに保存されているファイルを参照できるようにします。
from google.colab import drive
drive.mount('/content/drive')
下記の画面が出てくるので、URLにアクセスしてください。
そうすると、貼り付けコードが出てくるので、コピーをして貼り付けます。
②日本語フォントを読み込む
GoogleColabには、デフォルトで日本語対応のフォントがインストールされていません。
wordcloudで日本語を取り扱うときは、日本語フォントの指定が必須なので、インストールを行います。
日本語フォントのインストールは下記に記載があります。
GoogleColab
僕はどうしてもSaucy Dogの公式ロゴに近いフォントを使いたかったので、以下のコマンドでフォントを扱えるようにしました。
a)マイドライブに「fonts」ファイルを作成
b)「fonts」ファイルに使用したフォントを格納
c)以下のコマンドを実行して、マイドライブからフォントをコピー
!cp -a "/content/drive/My Drive/fonts/" "/usr/share/fonts/"
※GoogleColabでは、/usr/share/fonts/ にフォントが置かれます
③モジュールのインストール
文字列(歌詞)を形態素解析をするために、MeCabをインストールします。
また、辞書には固有表現に強いのが特徴である「mecab-ipadic-NEologd」を使用します。また、wordcloudも併せてインストールを行います。
# MeCabのインストール
!apt install mecab libmecab-dev mecab-ipadic-utf8
!pip install mecab-python3
# mecab-ipadic-NEologdのインストール
!apt install git make curl xz-utils file
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n -
# wordcloudのインストール
!pip install wordcloud
テキストデータ
どハマりしているSaucy Dogの歌詞をテキストデータとして扱っていきたいと思います!
(みなさん一度聞いてみてください!!!!「結」がおすすめです!)
https://www.youtube.com/channel/UCs8nP5mUR3pwJmgixsul8Hw
さて、Saucy Dogがリリースしている全36曲の歌詞を表にまとめたので、
このテキストデータを使って、wordcloudを作成していきます!

形態素解析
wordcloudを作成するためには、文章(歌詞)を単語で分割する必要があります。そのため、先程インストールしたMeCabを使って、形態素解析を行なっていきます。
import pandas as pd
import MeCab
with open('読み込みたいファイルを指定してください!', 'r')as f:
#用意したSaucy Dogの歌詞リストを読み込む
df = pd.read_csv(f, sep=",")
#単語を格納するための空配列
results = []
#一行(曲)ごとに読み込み
for row in df.values:
#歌詞
lyric = str(row[3])
#mecab-ipadic-NEologd を指定
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
mecab = MeCab.Tagger(path)
node = mecab.parseToNode(lyric)
#形態素解析
while node:
# 単語を取得
if node.feature.split(",")[6] == '*':
word = node.surface
else:
word = node.feature.split(",")[6]
# 品詞を取得
part = node.feature.split(",")[0]
if part in ["名詞", "動詞", "副詞", "形容詞", "形容動詞"]:
results.append(word)
node = node.next
ワードクラウドの作成
いよいよワードクラウドの作成です。
ワードクラウドの作成にあたって、公式のgitHubを参考にしました。
また、wordcloudのパラメータの設定、メソッドがわからないときは以下のコマンドを実行すると、詳細を確認できます。
from wordcloud import WordCloud, ImageColorGenerator
help(WordCloud)
今回、マスク画像を使ってワードクラウドを作成したいと思ったので、
画像処理ライブラリPillow(PIL)を使って画像を取り扱います。その際、画像から背景を削除する必要があります。
https://www.remove.bg/ja/upload
import numpy as np
from PIL import Image
# 背景画像の設定
img = np.array(Image.open( "背景に使いたい画像のパス" ))
そしてwordcloudには、ImageColorGenerator というクラスがあり、
画像の色情報からカラーマップが作成でき、単語の色を変更できます。
from wordcloud import ImageColorGenerator
image_color = ImageColorGenerator(img)
そして、パラメータを設定して、ワードクラウドを作成します。
※設定したパラメータの内容
width... 描画領域の横の大きさ
height... 描画領域の縦の大きさ
color_func... カラーマップ
stopwords... ワードクラウドから除外する単語
font_path... フォントを指定する ※日本語の場合は、設定必須
background_color... 画像の背景色を指定
mask... マスク画像を指定
max_words... ワードクラウドに表示する最大単語数
contour_color... マスク画像の輪郭線の色
contour_width... マスク画像の輪郭線の太さ
collocations... コロケーションやバイグラムを認めるかどうか
# 例) /usr/share/fonts/Ronde-B_square.otf
fpath = 'フォントのパスを指定する'
# ストップワードを指定する(ワードクラウドに表示させないワード)
stopwords = ["する", "いる", "れる", "なる", "てる", "ある"]
# ワードクラウド作成
wordcloud = WordCloud(
width=800,
height=600,
color_func=image_color,
stopwords=stopwords,
font_path=fpath,
background_color="white",
mask=img,
max_words=500,
contour_color='gray',
contour_width=5,
collocations=False).generate(text)
# ワードクラウドの描画した画像を出力
wordcloud.to_file("出力したいワードクラウドのファイル名")
最後に、作成したワードクラウドと元の画像を出力します。
import matplotlib.pyplot as plt
#画像の表示
plt.imshow(wordcloud, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
plt.show()
plt.imshow(img, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
plt.figure()
コード全体
import numpy as np
import pandas as pd
import MeCab
from wordcloud import WordCloud, ImageColorGenerator
import matplotlib.pyplot as plt
from PIL import Image
with open('/content/drive/My Drive/saucy_dog_2021-11-10.csv', 'r')as f:
#用意したSaucy Dogの歌詞リストを読み込む
df = pd.read_csv(f, sep=",")
results = []
for row in df.values:
lyric = str(row[3])
#辞書をneologdに指定する
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
mecab = MeCab.Tagger(path)
#形態素解析
node = mecab.parseToNode(lyric)
while node:
# 単語を取得
if node.feature.split(",")[6] == '*':
word = node.surface
else:
word = node.feature.split(",")[6]
# 品詞を取得
part = node.feature.split(",")[0]
if part in ["名詞", "動詞", "副詞", "形容詞", "形容動詞"]:
results.append(word)
node = node.next
#wordCloudの作成
text = ' '.join(results)
# ワードクラウド
img = np.array(Image.open( "/content/drive/My Drive/saucy_dog_thumbnail.png" ))
image_color = ImageColorGenerator(img)
fpath = '/usr/share/fonts/Ronde-B_square.otf'
stopwords = ["する", "いる", "れる", "なる", "てる", "ある"]
#stopwords=stopwords,
wordcloud = WordCloud(
width=800,
height=600,
color_func=image_color,
stopwords=stopwords,
font_path=fpath,
background_color="white",
mask=img,
max_words=500,
contour_color='gray',
contour_width=5,
collocations=False).generate(text)
wordcloud.to_file("saucy_dog_wordcloud.png")
#wordcloudの表示
plt.imshow(wordcloud, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
plt.show()
plt.imshow(img, cmap=plt.cm.gray, interpolation='bilinear')
plt.axis("off")
plt.figure()

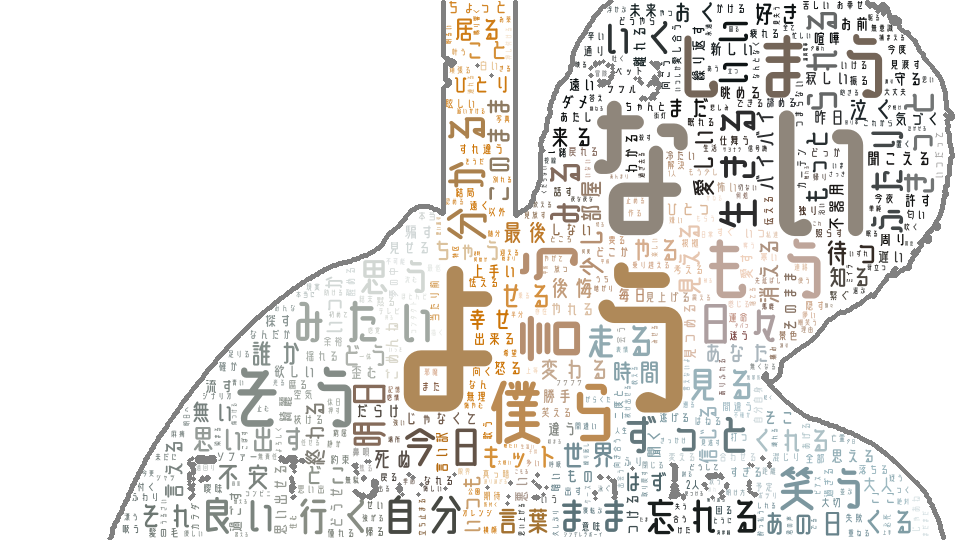
結果
今回、歌詞からワードクラウドを作成したので、ストップワードはあえて最小限にとどめました。(明らかにノイズであると判断したものはストップワードに設定しました。)
作成したワードクラウドを見てみると、「ない」「よう」が他の単語より大きくなっています。
実際に歌詞を見てみると、、、、
「ない」→ 否定系の意味で使われていることが多い
例)「一緒にいられない」「足りない」など
「よう」→ 比喩表現で使われていることが多い
例)「歯車のような人生」「アルビノ白く透き通った窓のようある日の欠伸」など
ワードクラウドを作成することで、文章によく使われがちな単語を可視化できます!
ぜひ皆さんもやってみてください!