Rancher Advent Calendar 2017の12/4の記事です。
Splunkをカタログ化し、Rancherで簡単に動かせるようにするまでを描きます。
Rancher Meetup Tokyo #11でSplunkとrancherで乗り切るシステム監査というLT
をしたんですが、その続編ですね。
Splunkって?
Slideにもあるように、あらゆるデータにインデックスをつけて保存できるデー タ分析プラットフォームです。Splunk公式
ELKスタックと言われるkibanaやElasticsearchが競合にあたります。ELKとの大きな違いは
- OSSではない
- 無償版もあるが、ログの転送量などに制限がかかっている。
といった感じです。
ただ、Docker Storeで公式イメージを配布したりしていて、無償版なら気軽に利用できるようになっています。
1日あたりの最大インデックス作成容量が500MBまでは無料で利用できるので、小規模なら結構いけます。
他にも機能制限があったりするので、詳しくは比較表を確認してください。
Rancherで作る意味
設定の確認
Splunkはログを流し込むとリアルタイムでindex化します。なので解析のテンプレートを間違えて作ると後から解析し直すことになり大変面倒です。
なので、コンテナでサクッと検証環境を作成して試すと結構楽です。
影響の確認
少量のログなら影響は軽微でしょうけど、流量が多いログをいきなり本番に流しこむは無謀です。なのでRancherで作った検証環境に流し込んでみて、システムへの影響を確認しましょう。
カタログを作ろう
まずはDockerfile作る
githubに上がってる公式イメージでもいいんですけど、SplunkのApp(pluginのようなもの)によってはjavaが必要なケースがあるので、今回は公式からコピーしたのをいじってjavaを入れます。
とりあえず動かしたいとかjavaなんか要らないよって人は公式でOKなので、このセクションは飛ばしてください。
まずは必要なファイルを公式からcloneします。
$ git clone https://github.com/splunk/docker-splunk.git
Cloning into 'docker-splunk'...
remote: Counting objects: 817, done.
remote: Total 817 (delta 0), reused 0 (delta 0), pack-reused 817
Receiving objects: 100% (817/817), 156.04 KiB | 0 bytes/s, done.
Resolving deltas: 100% (393/393), done.
Checking connectivity... done.
dokcer-splunkというディレクトリができ、中身はこんな感じのはずです。
|-- docker-splunk
| |-- CONTRIBUTING.md
| |-- LICENSE
| |-- README.md
| |-- enterprise
| | |-- Dockerfile
| | |-- README.md
| | |-- build.sh
| | |-- docker-compose.yml
| | |-- entrypoint.sh
| | `-- publishImage.sh
| `-- universalforwarder
| |-- Dockerfile
| |-- README.md
| |-- build.sh
| |-- docker-compose.yml
| |-- entrypoint.sh
| `-- publishImage.sh
この中のDockerfileに加筆してjavaを入れます。
以下を加筆してください。COPY entrypoint.sh /sbin/entrypoint.shの前あたりかな?
RUN set -ex && \
echo 'deb http://deb.debian.org/debian jessie-backports main' \
> /etc/apt/sources.list.d/jessie-backports.list && \
apt update -y && \
apt install -t \
jessie-backports \
openjdk-8-jdk-headless \
ca-certificates-java -y
あとはbuildして、dokcerhubやgitlabなどのリポジトリにpushすればOK。名前は適時変えてください。
$ docker build -t <リポジトリURL>/splunk/java .
$ docker push <リポジトリURL>/splunk/java
docker-compose.yml作る
カタログにはdocker-compose.ymlが必要なので作製しましょう。
でもこれも公式にあるので、そのまま使ってもOKです。
さっきpushしたイメージで行くよって人はimageのところをさっき作ったイメージ名にして、
公式でいいよって人はimageのところをsplunk/splunk:latestかsplunk/splunk:7.0.0にして下さい。
一応volumeを別にしてます。1514番Portは必須ではないです。syslogを受け付ける用のportです。
version: '2'
services:
splunkenterprise:
labels:
io.rancher.container.hostname_override: container_name
image: <イメージ名>
environment:
SPLUNK_START_ARGS: --accept-license
SPLUNK_ENABLE_LISTEN: 9997
SPLUNK_ADD: tcp 1514
volumes:
- opt-splunk-etc:/opt/splunk/etc
- opt-splunk-var:/opt/splunk/var
ports:
- "8000:8000"
- "9997:9997"
- "8088:8088"
- "1514:1514"
rancher-compose.yml作る
とりあえずこんな感じで大丈夫です。
version: '2'
catalog:
name : "Splunk"
version : "v0.1"
services:
splunkenterprise:
scale: 1
カタログ作成
カタログの作成に必要なのは
-
git cloneできる環境。今回はGitLab使ってます。 - その環境に接続できるRancher
だけです。
ディレクトリ構成
カタログのディレクトリ構成は、以下のような構成である必要があります。
0とか1がバージョンになります。svgは画面にに表示される画像です。お好きなロゴをどうぞ。
-- templates
|-- <カタログ名>
| |-- 0
| | |-- docker-compose.yml
| | |-- rancher-compose.yml
| |-- 1
| | |-- docker-compose.yml
| | |-- rancher-compose.yml
| |-- catalogIcon-cloudflare.svg
| |-- config.yml
config.ymlにはカタログの説明なんかを記述します。
とりあえずこんな感じでOKです。
name: Splunk
description: "Data Analysis"
version: v0.2
category: "Applications"
まずはディレクトリを上のように作って、さっき作ったdocker-compose.ymlとrancher-compose.ymlを
リポジトリに上げてみましょう。
Rancherに登録
作ったカタログをRancherに登録しよう。
Admin → Settingsと進み
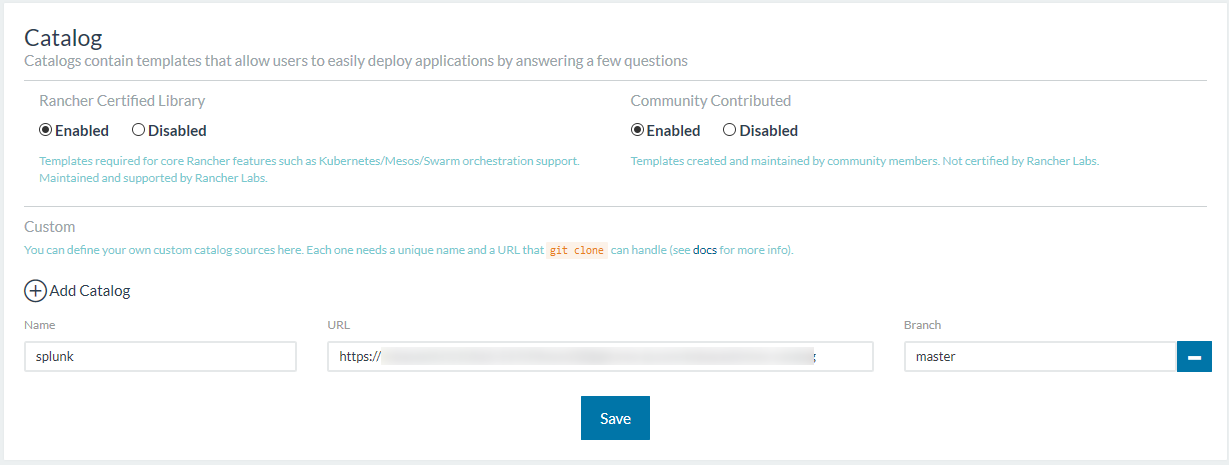
Catalog設定するところに名前、URL、Branchを設定。名前は任意でOKです。
認証が必要な場合は、https://<ユーザー名>:<トークンorパスワード>@<URL>と設定してください。
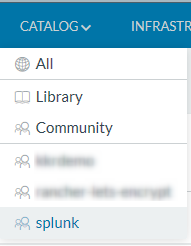
あとはSaveして問題なければ、Catalogに登録した名前が出てきます。
動かしてみよう
ここまで来たらあとは他のカタログと同じように、
選択して

Launchしましょう!
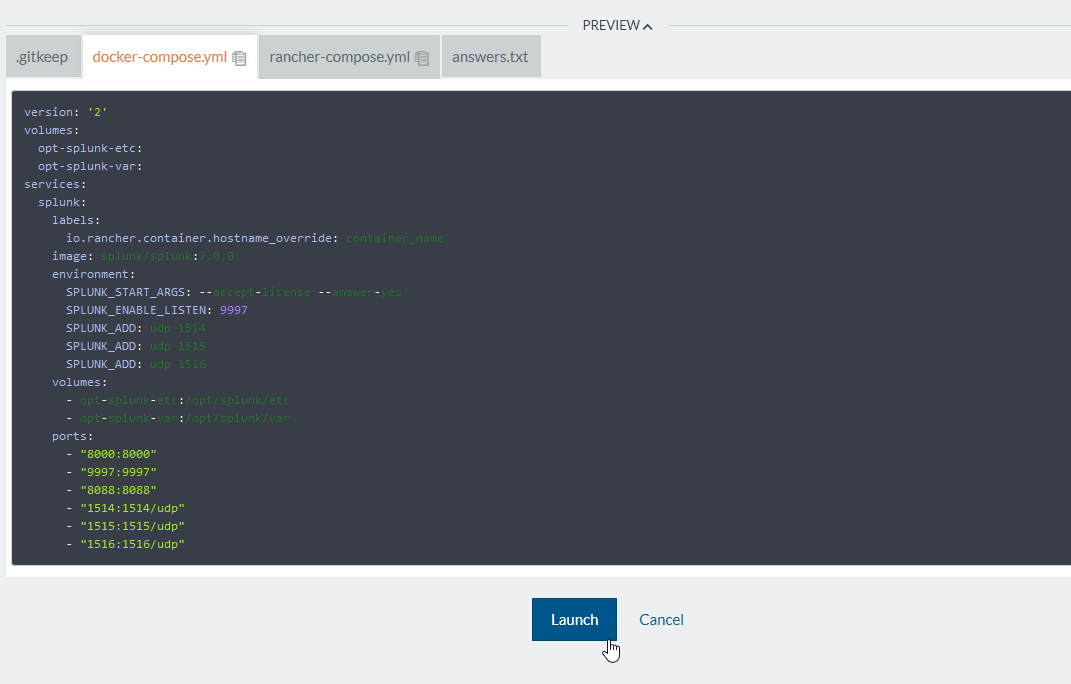
無事起動してこんな感じになればOKです。

splunkの管理画面は8000番portを使うので、さっきのStack画面の8000のところをクリックしてみましょう。

こんな感じでsplunkの画面が出てくるはずです

デフォだとログイン後の言語が英語なので、日本語にしたい場合は
URLの
http://<IP or Hostname>/en-US/account/login?return_to=%2Fen-US%2F
の
en-USのところをja-JPに変えましょう。
こんなこともできるよ
起動後にPortを追加したい
ポートの追加はStackのUpgradeから行えます。
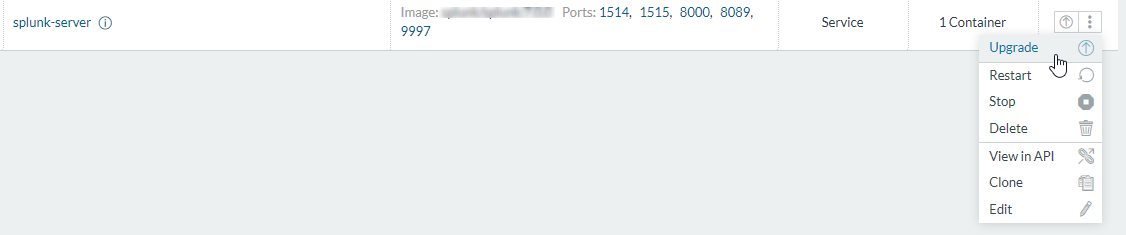
こんな感じですね。
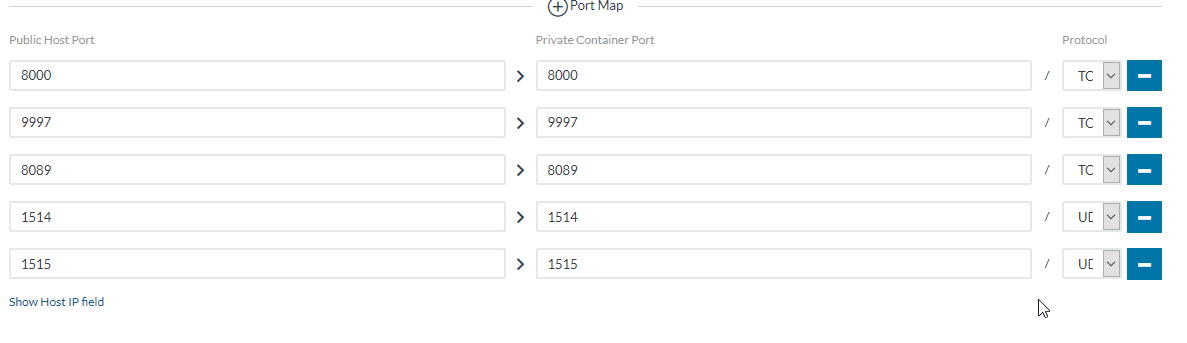
システムの負荷状況もコンテナ管理画面から確認できます。
起動前にPortを変更したい
複数環境作るのでportが重複しないように、Stack作成前に管理画面のPortを変えたい!みたいなときは、rancher-compose.ymlとdocker-compose.ymlを変更し、パラメータで渡せるようにする必要があります。
そんなときはrancher-compose.ymlにquestionsというセクションを足すことでパラメータを渡すことができます。
rancher-compose.ymlをこういう風に記述し、
questions:
- variable: "port_web"
description: "HTTP port for Splunk Web interface"
label: "HTTP port:"
required: true
default: 8000
type: "string"
docker-compose.ymlにこういう記述をすると
ports:
- "${port_web}:8000"
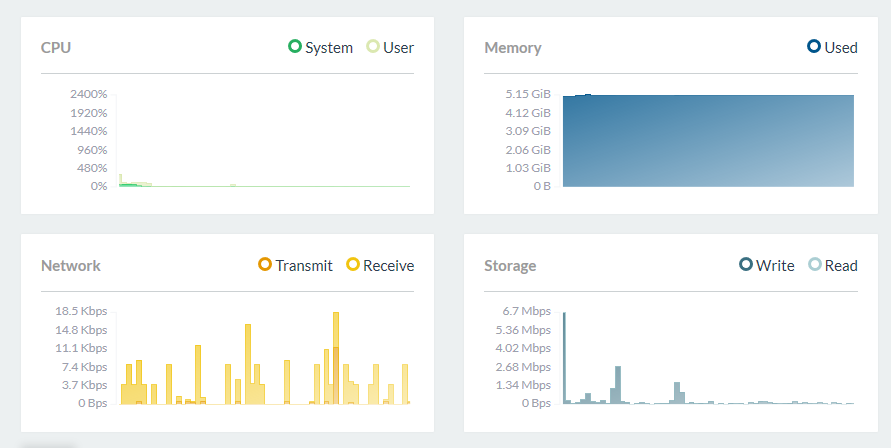
画面にこんな項目が増えます。他のも混ざってますが、要領は同じです。
課題
ほかのコンテナも同様なんですが、制限をかけない限りはホストのCPUやメモリを使い切ろうとするのでほかのアプリへの影響を考えないとだめです。
また、クラスタ構成にするのであれば同一ホストで動くとあまり意味がないでうまく分散させてあげないとだめだし、本番で使おうとするならストレージどうするの?ていう課題も出てきます。
でも今回紹介した手順でコンテナの最大のメリットである「環境の高速デプロイ」は達成できるので、検証環境や学習環境が目的であれば十分かと思います。
参考資料
compose.ymlの詳細な情報は下記をご覧ください。
Rancher プライベートカタログとCompose
Rancher Docs - Creating Private Catalogs
また、公式カタログを見るのもお勧めです
rancher/community-catalog: Catalog entries contributed by the community