はじめに
本記事では、PentahoETLの基本的なデータ変換処理の実装例および各処理を実装するにあたっての注意点などを紹介します。全5回に分けて紹介する内、本記事は第3回目です。その他の回は以下のリンクからご参照ください。
PentahoETLの基本処理パターン集【データ入力編】(1/5)
PentahoETLの基本処理パターン集【データ加工編1】(2/5)
PentahoETLの基本処理パターン集【データ加工編3】(4/5)
PentahoETLの基本処理パターン集【データ出力編】(5/5)
注記
・本記事は、PentahoETLについての製品利用の必要知識を有する方を対象が対象です。
・本書内の画面などについて、Pentahoのバージョンによっては本書の内容と異なる可能性があることにご注意ください。
用語説明
PentahoETLで利用する機能の用語を紹介します。
| # | 用語 | 処理単位 | 内容 |
|---|---|---|---|
| ① | ジョブ Job |
実行処理単位 | 一つもしくは複数のTransformationをコーディネートするものです。スケジューリングされて実行されます。 |
| ② | データ変換 Transformation |
バッチ処理単位 | ソースデータをInputし、変換処理を実行してターゲットデータをOutputする最小単位です。 |
| ③ | ステップ Step |
処理の最小単位 | 事前に登録されている機能です。ステップのプロパティに具体的な値を入れることで要求する処理が実行されます。 |
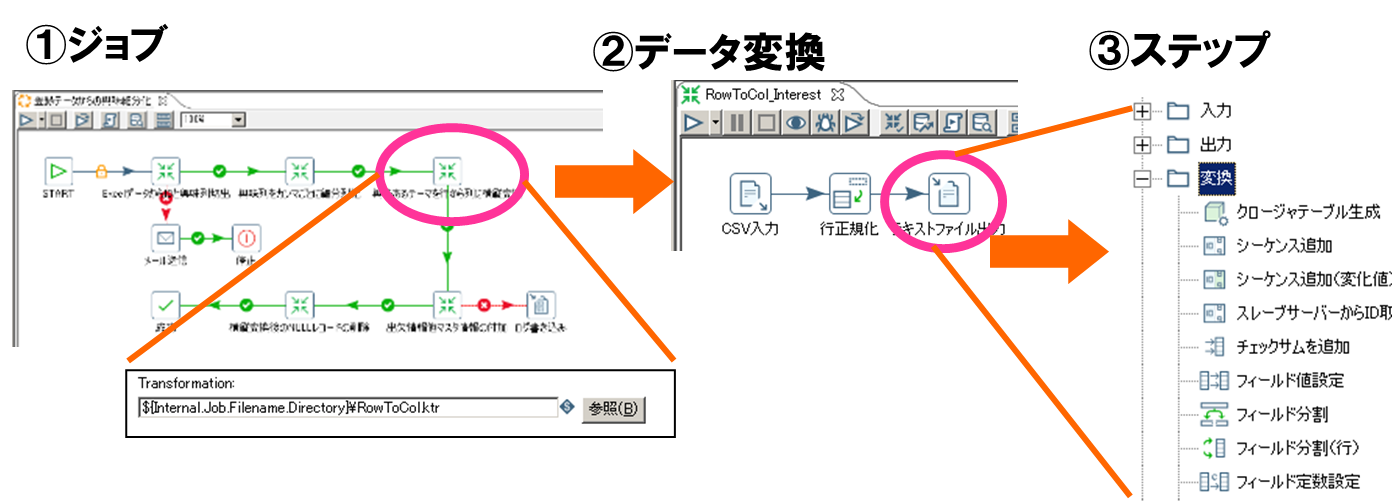
基本処理パターン例の見方

処理パターンリスト
| # | 処理 | 使用ステップ |
|---|---|---|
| 1 | 集計 1. グループ化による実装 2. メモリーグループ化による実装 |
・グループ化 ・メモリーグループ化 |
| 2 | 重複行削除 | ・重複行削除 ・重複行削除(HashSet) |
| 3 | 1レコードを複数レコードに展開 | ・フィールド分割 (行) |
| 4 | 1フィールドを複数フィールドに展開 | ・フィールド分割 |
| 5 | ピポット 1. 横→縦ピポット 2. 縦→横ピポット |
・行正規化 ・行非正規化 |
| 6 | 差分抽出 | ・行マージ(比較) |
| 7 | NULL値変換 1. NULL値→定数変換 2. 定数→NULL値変換 |
・NULL値定数変換 ・定数NULL変換 |
| 8 | フィルタリング | ・フィルター |
| 9 | 前後のレコードの値を参照 | ・分析クエリー |
| 10 | ランダムサンプリング | ・貯留槽サンプリング |
| 11 | 基本統計量算出 | ・単変量統計 |
1-1. 集計 グループ化による実装

1-2. 集計 メモリーグループ化による実装

2. 重複行削除

3. 1レコードを複数レコードに展開

4. 1フィールドを複数フィールドに展開

5-1. ピポット 横→縦ピポット

5-2. ピポット 縦→横ピポット

6. 差分抽出

7-1. NULL値変換 NULL値→定数変換

7-2. NULL値変換 定数→NULL値変換

8. フィルタリング

9. 前後のレコードの値を参照

10. ランダムサンプリング

11. 基本統計量算出

まとめ
今回はPentahoETLの基本処理パターン データ加工編2を紹介しました。
基本処理パターンは他の記事でも紹介しておりますので、ぜひご参照ください。
他社商品名、商標等の引用に関する表示
HITACHIは,株式会社 日立製作所の商標または登録商標です。
Pentahoは、Hitachi Vantara LLCの商標または登録商標です。
その他記載の会社名,製品名などは,それぞれの会社の商標もしくは登録商標です。