Rubyのシンタックスを息を吸うように書くために、少しでも理解が怪しいシンタックスを繰り返したくために書きます。
今回は正規表現です。これこそ、繰り返し書いて、息を吸うようにかけるようになりたい。
また、本記事で扱う正規表現は、初心者向けなため100%完璧に正しい表現でなく、そこそこの精度の表現で妥協しています。そこは、ご承知おきください。そこそこでもないぞ、と言う場合は、ご指摘ください。
正規表現は、まずパターンを見つけて言語化することが大事で、それができればあとは、そのプログラムを記述するだけです。
問題の確認は、以下のサービスを使っています。(置換は、エディタのAtomを使っています)
Rubular: Rubyで動作する正規表現を試せるオンラインエディタ
ここで学ぶ正規表現のメタ文字
| メタ文字 | 意味 | 例 |
|---|---|---|
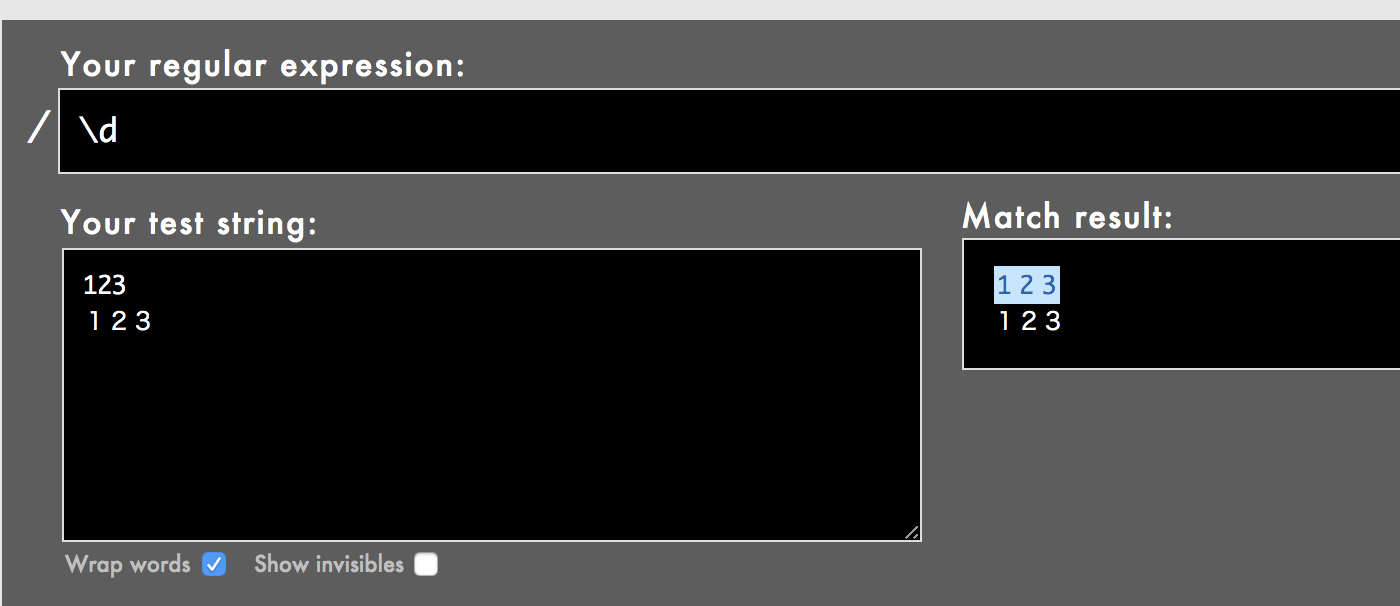
| \d | 1個の半角数字 | 0123456789 |
| \d\d\d\d | 4個の半角数字 | 1111 |
| {n,m} | 直前の文字やパターンがn回以上、m回以下連続する | - |
| \d{3,5} | 3個~5個連続する半角数字 | 123 や 12345 |
| [AB] | AかBのいずれか1文字 | - |
| - |
[]の中で使うと文字の範囲を表す |
- |
| [a-z] | aかbかcか...かzのいずれか1文字 | - |
| [-az],[az-] | aかzかハイフンのいずれか1文字 | - |
| [0-9] | 0か1か2か3か...か9のいずれか1文字 | - |
| . | 改行以外の任意の1文字 | あ |
| ? | 直前の文字やパターンが1回、もしくは0回現れる | - |
| .? | 改行以外の任意の文字が1回、もしくは0回現れる | - |
| * | 直前の文字やパターンが0回以上連続する | - |
| .* | 直前の文字の0回以上の繰り返し | - |
| *? | 直前の文字やパターンが0回以上連続する(最短マッチ) | - |
| + | 直前の文字が1回以上の繰り返し | - |
| +? | 直前の文字が1回以上の繰り返し(最短マッチ) | - |
| \ | メタ文字のエスケープ | - |
| \w | 半角英数字とアンダースコア1文字 | - |
| () | 内部でマッチした文字列をキャプチャまたは、グループ化する | - |
| [^] | 〜以外の任意の1文字を表す文字クラスを作る | - |
| ^ | 行頭 | - |
| $ | 行末 | - |
| \t | タブ | - |
| \s | 空白行文字全般 | \t\r\n\f\v |
| \n | 改行コード | - |
| \b | 単語の境界の位置を示す | - |
| {n} | 直前の文字やパターンがn回する | - |
| {n,} | 直前の文字やパターンがn回以上連続する | - |
| {n,m} | 直前の文字やパターンがn回以上、m回以下連続する | - |
問題1(電話番号)
日本の固定電話,携帯電話に基本マッチする正規表現を書いてください。
電話:03-1234-5678
電話:06-9999-9999
電話:090-1234-5678
電話:0799-12-3450
電話:04982-2-2002
郵便番号:150-0012
パターン1
を見ると、
半角数字が2個~5個 + ハイフン(-) + 半角数字が1個~4個 + ハイフン(-) + 半角数字が4個
で、基本マッチすることがわかりました。
正解1(電話番号)
\d{2,5}-\d{1,4}-\d{4}
問題2(電話番号)
番号自体は、問題1と同じですが、ハイフンでなく(や)の場合もありますよね。それにマッチする正規表現を書いてください。
電話:03-1234-5678
電話:06-9999-9999
電話:090-1234-5678
電話:0799-12-3450
電話:04982-2-2002
電話:03-1234-5678
電話:06(9999)9999
電話:090-1234-5678
電話:0799(12)3450
電話:04982-2-2002
郵便番号:150-0012
パターン2
半角数字が2個~5個 + ハイフン(-) か ( + 半角数字が1個~4個 + ハイフン(-)か) + 半角数字が4個
で、基本マッチすることがわかります。
正解2(電話番号)
\d{2,5}[-(]\d{1,4}[-)]\d{4}
問題3(表記ゆれを許容して社名を抽出する)
表記ゆれの多いワード「引越し」をサービス名にした引越し侍には、以下のような表記ゆれがある可能性があります。
引っ越し侍
引越侍
引越し侍
引っ越し 侍
引越侍
引越し 侍
引越し・侍
パターン3
-
引っ越と引越は、ちいさい「つ」(っ)があっても、無くても許容できるようにするために.?を使用する -
越と侍の間は何があってもいいように*?を使用する
で、基本マッチすることがわかります。
| メタ文字 | 意味 | 例 |
|---|---|---|
| .? | 任意の1文字か0文字 | - |
| .* | 直前の文字の0回以上の繰り返し | - |
正解3(表記ゆれを許容して社名を抽出する)
引.?越.*侍
ただこれだと、例えば「引っ越さない侍」とかでも許容してしまうので、どこまで厳密に抽出するかはその時の状況次第になります。
問題4(HTMLから文字列を抽出)
よく見る都道府県のHTML。ここから、valueの中身と、タグの中身のテキスト(pref_xxx,北海道)がある行ごと抽出する正規表現を書いてください。
<select name="pref_name">
<option value="pref_hokkaido">北海道</option>
<option value="pref_aomori">青森県</option>
<option value="pref_iwate">岩手県</option>
</select>
パターン4
pref_aomoriやpref_hokkaidoからパターンを導き出すと、
value= + " + aからzのアルファベットかアンスコが1文字以上 + "
- アルファベットかアンスコが1文字以上 =
[a-z_] - 直前のが1文字以上 =
+
つまり [a-z_]+
- 任意の1文字以上 =
[a-z_] - 直前のが1文字以上 =
+
タグの中身のテキストは、何かしらテキストが1文字以上あるので .+
で、基本マッチすることがわかります。
正解4(HTMLから文字列を抽出)
行全体をマッチさせるとしたら
<option value="[a-z_]+">.+<\/option>
optionの閉じタグにあるバックスラッシュは、/のエスケープを目的にしています。
Rubyは/を正規表現オブジェクトとして認識してしまうので。
問題5(HTMLをCSVに変換 - キャプチャ)
問題4にあるvalueの中身と、タグの中身のテキスト(pref_xxx,北海道)をキャプチャする正規表現を書いてください。
Rubyにおけるキャプチャとは何ができるやつなのか
- かっこ
()内の文字列を参照出来るようにすることができる -
$1,$2...に保存し、文字列を変数として参照できる(置換にも使える)
<select name="pref_name">
<option value="pref_hokkaido">北海道</option>
<option value="pref_aomori">青森県</option>
<option value="pref_iwate">岩手県</option>
</select>
パターン5
基本はパターン4と同じです。
キャプチャに関してはキャプチャしたい文字列を()で閉じ込めます。
正解5(HTMLをCSVに変換 - キャプチャ)
<option value="([a-z_]+)">(.+)<\/option>
キャプチャされてることがわかります。

Rubularは置換できないので、代わりにエディタのAtomにやらせましょう(Atomじゃなくてもできると思います)
- Atomを正規表現モード(
.*ボタン押す)にして - 検索窓に
<option value="([a-z_]+)">(.+)<\/option>入りつけて - 置換後の形式(
$1,$2)を下の検索窓に借りつけてreplace Allボタンを押す-
$1と$2はそれぞれキャプチャされた1番目の文字列と2番目の文字列を表しています
-

問題6(HTMLをCSVに変換 - キャプチャ その2)
基本はパターン5と同じですが。valueに値がなくて、デフォでselectedがついてる場合もよくありますよね?その場合でもキャプチャできる正規表現を書いてください。
<select name="pref_name">
<option value="" selected>都道府県</option>
<option value="pref_hokkaido">北海道</option>
<option value="pref_aomori">青森県</option>
<option value="pref_iwate">岩手県</option>
</select>
パターン6
value= + " + aからzのアルファベットかアンスコが1文字以上または、何も無い + "
- アルファベットかアンスコが1文字以上 =
[a-z_] - 直前のが0回以上 =
*
つまり [a-z_]*
selectedに関しては、ある場合と、無い場合を考慮し、かつキャプチャされたく無いので?:をつける。
つまり (:? selected)?
最後の?は、selectedが無い場合も考慮して書いています。
タグの中身のテキストは、何かしらテキストが1文字以上あるので .+
で、基本マッチすることがわかります。
正解6(HTMLをCSVに変換 - キャプチャ その2)
<option value="([a-z_]*)"(?: selected)?>(.+)<\/option>
これで、キャプチャされてることもわかるかと思います。
また、エディタのAtomで置換できることもわかります。

正解6に関してはリファクタも可能で、
a-z_この部分ですが、\wで代替え可能です。なぜなら、\wは、半角英数字とアンダースコア1文字を表すからです。
<option value="([\w]*)"(?: selected)?>(.+)<\/option>
問題7(最長マッチと最短マッチ)
問題6までにあるHTMLを改行なしで行なった場合
<option value="pref_hokkaido">北海道</option><option value="pref_aomori">青森県</option><option value="pref_iwate">岩手県</option>
その場合の正規表現は
<option value="([a-z_]*)"(?: selected)?>(.+)<\/option>
Rubularでのキャプチャ結果(Match groups)は...
1. pref_hokkaido
2. 北海道</option><option value="pref_aomori">青森県</option><option value="pref_iwate">岩手県
- の部分が思ったように取れていませんが、それは、
.+(任意の文字が1個以上)が、最長マッチな量指定子(Quantifier)であるからです。また、.*(任意の文字が0個以上)も同じ最長マッチな量指定子です。
ググるといろんなワードが出てくるので整理すると、以下のような感じ。
| 可能な限り長い文字列をマッチ | 可能な限り短い文字列をマッチ |
|---|---|
| 最長マッチ | 最短マッチ |
| Greedy Match | non Greedy Match |
| 欲張りなマッチ | 控えめなマッチ |
| 貪欲なマッチ |
正規表現の量指定子
正規表現の量指定子を整理すると主に以下のようにまとめられます。
| 最長マッチ | 最短マッチ | 意味 |
|---|---|---|
| * | *? | 直前のパターンの0回以上連続 |
| + | +? | 直前のパターンの1回以上連続 |
基本的には、*や+は何も指定しない限り最長マッチになるので、そのメタ文字の後に?つければ最短マッチになると覚えておけば大丈夫ですね。
それでは、正規表現を変えてみましょう。
正解7(最長マッチと最短マッチ)
<option value="([a-z_]*)"(?: selected)?>(.+?)<\/option>

最初の>からはじめて、最初に見つかった<までで、終わらせていることがわかりますね。
正解7 別パターン (否定の意味があるメタ文字^)
最短マッチ以外では、否定の意味があるメタ文字^を使うといいと思います。
つまり
<option value="([a-z_]*)"(?: selected)?>([^<]+)<\/option>
この部分>([^<]+)<が変わったのですが、こう[^<]+することで、この文字<以外の1文字以上の連続した文字列を指定するので、<が出現した時点でマッチ完了します。

結果、同じ回答が得られましたね。
問題8(スペースやタブが余計なら消したい)
以下のRubyコードから、余計なスペースやタブがある場合、それを見つける正規表現を書いてください。
def output_name(name)
p "My Name Is #{name}"
end
output_name('john')
output_name('paul')
正解8(スペースやタブが余計なら消したい)
| メタ文字 | 意味 | 例 |
|---|---|---|
| ^ | 行頭 | - |
| $ | 行末 | - |
| \t | タブ | - |
| [AB] | AかBのいずれか1文字 | - |
| + | 直前の文字が1回以上の繰り返し | - |
| ^[ \t]+$ | 行頭から行末までスペースかタブが1文字以上繰り返す | - |
^[ \t]+$
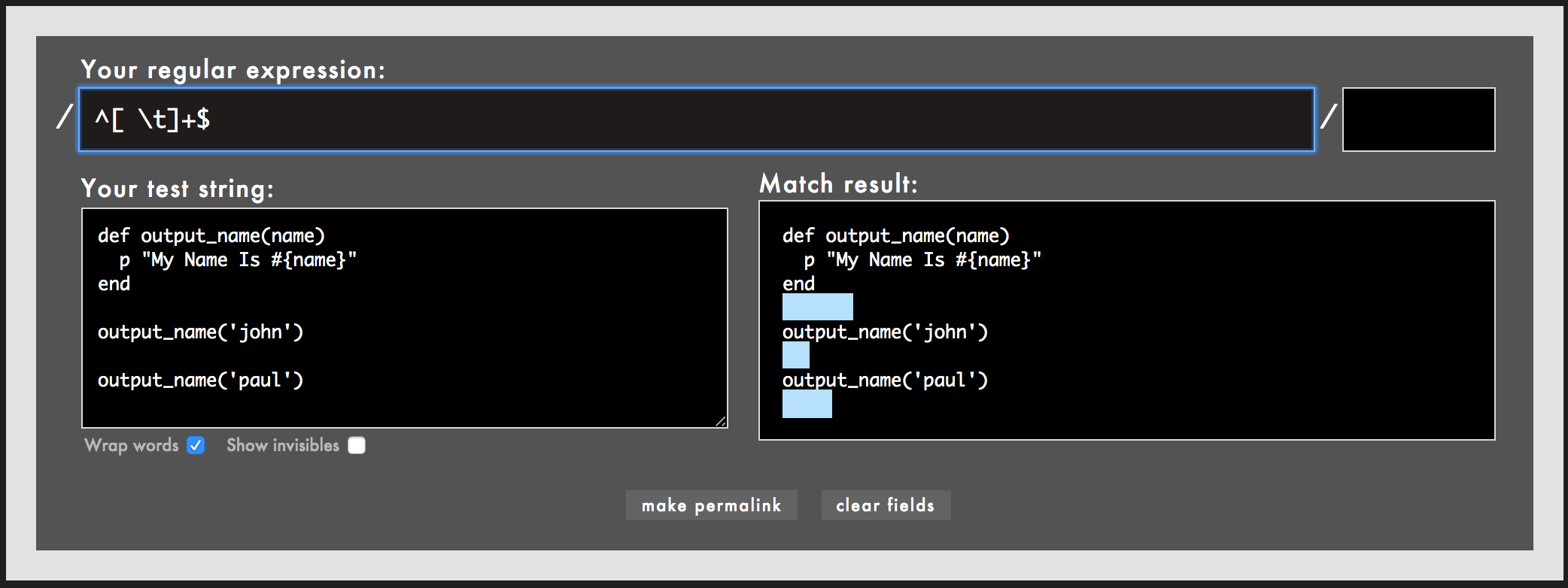
ありましたね。
問題9(スペースやタブが余計なら消したい その2)
行末に入った無駄な空白を見つける正規表現を書いてください。
def output_name(name)
p "My Name Is #{name}"
end
正解9(スペースやタブが余計なら消したい その2)
[ \t]+$

ありましたね。
問題10(インデントをそろえる)
以下のテキストのインデントを揃えてください。
行く川のながれは絶えずして、しかも本の水にあらず。
よどみに浮ぶうたかたは、かつ消えかつ結びて久しくとゞまることなし。
世の中にある人とすみかと、またかくの如し。
引用: 鴨長明 方丈記
パターン10
文頭からはじめって、スペースやタブが1個以上あるやつを見つければいいわけですね。それを正規表現にすると、以下の感じ。
正解10(スペースやタブが余計なら消したい その2)
^[ \t]+

揃いましたね。
問題11(不要なスペースの消去)
以下のjsonを整形してください(不要なスペースを消去してください)。
{
"01": "北海道",
"02": "青森県",
"03": "岩手県",
"04": "宮城県",
"05": "秋田県"
}
引用: 都道府県コード | knooto
パターン11
コロン:から始まって半角スペースやタブが1個以上か、0個以上あるものを検出できればいいですよね。
正解11(不要なスペースの消去)
:[ \t]*
検出できれば、置換後の文字列はコロンに半角スペース1個とかにすればいいのではないでしょうか?:
正解11 - 別解答 (不要なスペースの消去)
正規表現には、空白行文字全般を表すメタ文字があります。それが\sです。これを使って、別解もできます。
:\s*
ただ、注意しなきゃ行けないのは、Rubyの場合は、\sは、
- タブ:
\t - リターン:
\r - 改行:
\n - 改ページ:
\f - 垂直タブ:
\v
が含まれます。が言語が変わると、その定義も変わります。
参考
問題12(サーバログから任意のログを抽出)
初心者歓迎!手と目で覚える正規表現入門・その3「空白文字を自由自在に操ろう」 - Qiita を参考にして、Heroku上に出力されたRailsログをさらに加工しました。
これから、Webページへのアクセス以外を抽出・削除する正規表現を書いてください。
July 29 17:33:02 app/web.1: Completed 302 Found ...
July 29 17:36:46 heroku/api: Starting process ...
July 29 17:36:50 heroku/scheduler.7625: Starting ...
July 29 17:36:50 heroku/scheduler.7625: State ...
July 29 17:36:54 heroku/router: at=info method=...
July 29 17:36:54 app/web.1: Started HEAD "/" ...
July 29 17:36:54 app/web.1: Completed 200 ...
July 29 17:37:03 heroku/api: Starting process ...
July 29 17:37:47 heroku/scheduler.7625: Starting ...
July 29 17:37:51 heroku/scheduler.7625: State ...
July 29 17:37:51 heroku/router: at=info method=...
July 29 17:37:55 app/web.1: Started HEAD "/" ...
July 29 17:37:55 app/web.1: Completed 200 ...
引用: 初心者歓迎!手と目で覚える正規表現入門・その3「空白文字を自由自在に操ろう」 - Qiita
パターン12
Webページへのアクセス以外のログは
- heroku/api が含まれる行
- heroku/scheduler が含まれる行
上記どちらも取得対象としたいので、OR条件(|)を使用する
その場合、ORの範囲を明確にするため、キャプチャでなくグループとしての()が使われることが多いです
行ごと削除したいので
行頭からの何らかの文字が1文字以上 + Webページへのアクセス以外のログ + 行末にある改行コードまで何らかの文字が1文字以上
- 行頭は
^ - 何らかの1文字は
. - 直前の文字やパターンが1文字以上連続するのは
+ - 改行コードは
\n
正解12(サーバログから任意のログを抽出)
^.+heroku\/(api|scheduler).+\n

行末にある改行コードも含めているので\n、余計な空行もできずスッキリしましたね。
問題13(間違えやすい^について)
[^AB][AB^]
正解13(サーバログから任意のログを抽出)
| メタ文字 | 意味 | 例 |
|---|---|---|
| [^AB] | AとBでもない1文字 | C |
| [AB^] | AかBか^の1文字 | A |
^が[]のなか
問題14(特定の英単語に完全一致させる\b)
下記の「北風と太陽」的な適当な英文からwindという英単語を抜き出してください。
The North wind and the Sun had a quarrel about which of them was the stronger. While they were disputing with much heat and bluster, a Traveler passed along the road wrapped in a cloak.
The North winder and the windinan had a quarrel about which of them was the stronger. While they were disputing with much heat and bluster, a Traveler passed along the road wrapped in a cloak.
With the first gust of windam the ends of the cloak whipped about the Traveler's body. But he immediately wrapped it closely around him, and the harder the wind blew, the tighter he held it to him. The North wind tore angrily at the cloak, but all his efforts were in vain.
正解14(特定の英単語に完全一致させる\b)
\bwind\b
問題文から、普通に「wind」を検索すると、「winder」とか、「windinan」もマッチしてしまいます。そこで、\b。
\bというメタ文字は、単語の境界の位置を示します。\b英単語\bで検索できます。
問題15
filename=以降のファイル名を抜き出してください。
type=zip; filename=users.zip; size=1024;
type=xml; filename=posts.xml; size=2048;
type=html; filename=index.html; size=1024;
正解15
filename=([^;]+)

お勉強(先読み・後読み)
まず、先読み・後読みの解説します。
| 意味 | 構文 | 例 | 例の意味 | マッチする単語 |
|---|---|---|---|---|
| 肯定的先読み | (?=pattern) | green(?=tea) | 直後にteaがある直前のgreen | greentea |
| 否定的先読み | (?!pattern) | green(?!tea) | 直後にteaがない直前のgreen | greenmile |
| 肯定的後読み | (?<=pattern) | (?<=tea)green | 直前にteaがある直後のgreen | teagreen |
| 否定的後読み | (?<!pattern) | (?<!tea)green | 直前にteaがない直後のgreen | teagreen |
肯定的先読み

否定的先読み

肯定的後読み

否定的後読み

問題16
上の行は、マイルスデイビスのアルバム「カインド・オヴ・ブルー」時代のバンドメンバー
下の行は、マイルスデイビスのアルバム「ビッチェズ・ブリュー」時代のバンドメンバー
Miles:trumpet, John:sax, Bill:piano, Paul:bass, Jimmy:drums
Miles:trumpet, Wayne:sax, Chick:piano, Dave:bass, Airto:drums
このテキストの中から、ベーシストの名前だけを抜き出してください。
正解16
:bassというテキストの直前にある1文字以上のアーティスト名を抜き出すので、肯定的先読みで抜き出せばいいでしょう。
\w+(?=:bass)
これで、"Paul"(ポール・チェンバース) と "Dave"(デイブ・ホランド) を抜き出せました。

問題17(否定的後読み)
- 47都道府県で最後に「道」がつくのは北海道のみですが、そうじゃないのが混ざってるのを調べる場合の否定的後読みな正規表現を書いてください。
北海道
愛知県
京都道
大阪府
東京都
神奈川県
埼玉県
正解17
(?<!北海)道
(?<!北海) と書くと 北海 という文字列以外の直後の道にマッチするので、否定の後読みと言われるそうです。
京都道なんてのがマッチしましたね。これ、目で確認できなくなるくらい大き時には効果を発揮する探索方法になると思います。
問題18(否定的先読み)
以下のテキストから、「食べる方のおでん」だけを抜き出してください。
冬に食べるおでんはおいしい。『おでんくん』は、リリー・フランキーの絵本作品(小学館発行、2001年)。
正解18
おでん(?!くん)
これで、キャラクターのおでんくんは無視されるようになりました。

問題19(後方参照)
以下のhtmlから、「aタグのリンクが、viewにも表示されているリンク(1行目と3行目)」を検索できるような正規表現を書いてください。
<a href="https://www.amazon.co.jp">https://www.amazon.co.jp</a>
<a href="https://www.rakuten.co.jp/">楽天市場</a>
<a href="https://zozo.jp/">https://zozo.jp/</a>
<a href="https://www.cosme.net/">@cosme</a>
正解19
<a href="(.+?)">\1<\/a>

\1は、()でキャプチャされた1番目の文字列という意味です。つまり、hrefの値であるリンクのことですね。
問題20(総復習)
これまで学んだことを複数、生かして、総復習問題をやっていきましょう。
以下の記事を参考に問題を作成しています。
初心者歓迎!手と目で覚える正規表現入門・その4(最終回)「中級者テクニックをマスターしよう / ツイート、アカウント、ツイート日時を抽出する(メタ文字の複雑な組み合わせ)」 - Qiita
以下のテキストは、ツイートと、アカウント名と、ツイート日時を合わせています。
All You Need Is Love. - @ryosuketter 9s
Don't Let Me Down. - @odensan 12m
I Want to Hold Your Hand. - @wanpanman 8h
September in the Rain. - @higashimaru Feb 21
Two of Us. - @portdevelopment 11 Apr 2019
ここからツイートとアカウント名とツイート日時をそれぞれ抽出してみましょう。
以下のようにキャプチャできれば合格です。

パターン20
ツイートのパターン
行頭(^) + 0文字以上の文字列であれば、(.*)、1文字以上の文字列であれば、(.+) + スペース + ハイフン(-) + スペース
^(.*) -

ツイートの存在が必ず保証されれば、以下でも良いです。
つまり
^(.+) -

ツイートの内容が必ず
アカウント名のパターン
@ + 任意の文字列(\w)が1文字以上連続(+) + スペース
つまり
@(\w+)

ツイート日時のパターン
以下の2つ、どちらかですね。
- 1文字以上の数字(
\d) +sかmかh - 1文字以上の数字(
\d)がある場合がある + アルファベット3文字(最初だけ大文字) + 1文字以上の数字(\d)
つまり
(\d+[smh])|((?:\d+ )?[A-Z][a-z]{2} \d+)
直前の文字が1個、またはゼロ」を表すメタ文字 ? は、グループ化で使用している()の直後に置くと、カッコでグループ化された文字列が1個、または0個という意味になります。
() の直後に置ける量指定子は?だけでなく、+や*も置くことができます。
正解20(総復習)
- ツイート:
^(.+) - - アカウント名:
@(\w+) - ツイート日時:
(\d+[smh])|((?:\d+ )?[A-Z][a-z]{2} \d+)
^(.+) - @(\w+) (\d+[smh]|(?:\d+ )?[A-Z][a-z]{2} \d+)
動作確認をして、ツイート、アカウント名、ツイート日時がキャプチャされていることを確認してください。

すべて、キャプチャできていますね。
問題21(メタ文字のキャプチャ)
ちゃんと、ファイルと拡張子を指定できている文字列を抜き出す正規表現を書いてください。
index.html
index@html
style.css
style%css
正解21(メタ文字のキャプチャ)
\w+\.\w+
問題22(n個以上やn個以下の指定)
これまで学んできた正規表現のこのメタ文字{n,m}の意味は、直前の文字やパターンがn回以上、m回以下連続する
という意味でしたが、細かく分けると、以下の表のような場合分けがあります。
| メタ文字 | 意味 | 例 |
|---|---|---|
| {n} | 直前の文字やパターンがn回する | - |
| {n,} | 直前の文字やパターンがn回以上連続する | - |
| {n,m} | 直前の文字やパターンがn回以上、m回以下連続する | - |
例えば以下のような文字列があるとします。
ateam
ateaam
ateaaam
ateaaaam
ateaaaaam
ateaaaaaam
正解2(n個以上やn個以下の指定)
「連続するaが2回続く」正規表現を描きたい場合は
atea{2}m

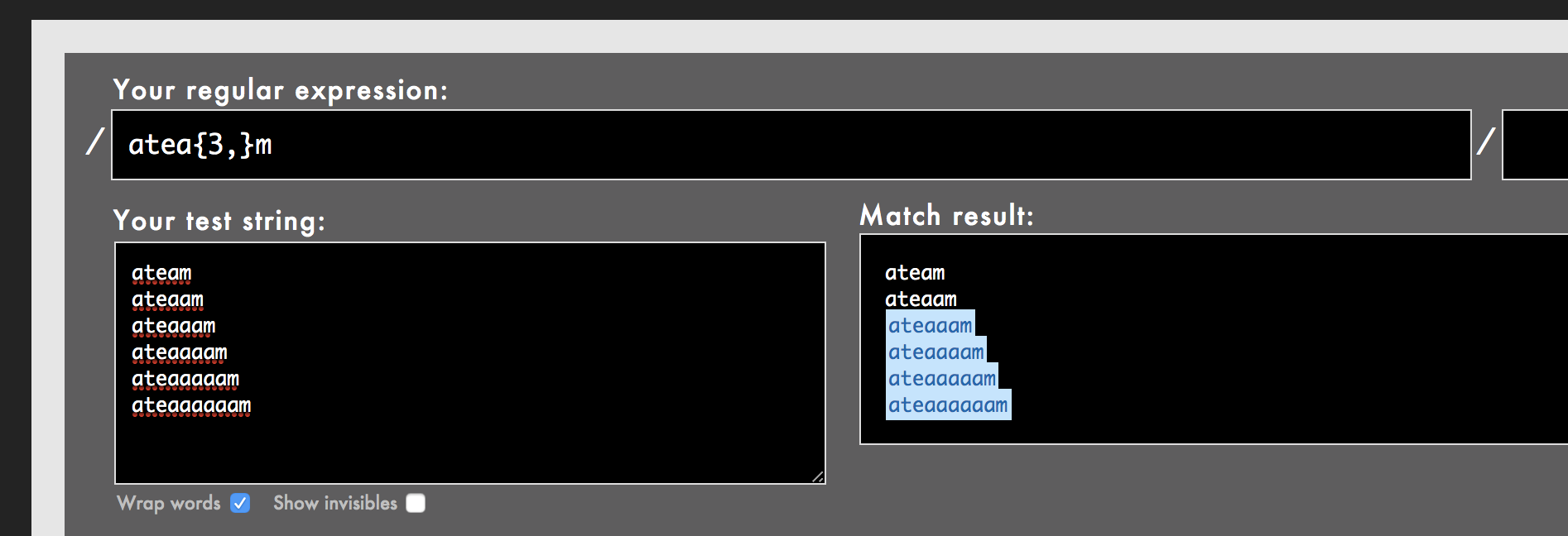
「連続するaが3回以上続く」正規表現を描きたい場合は
atea{3,}m
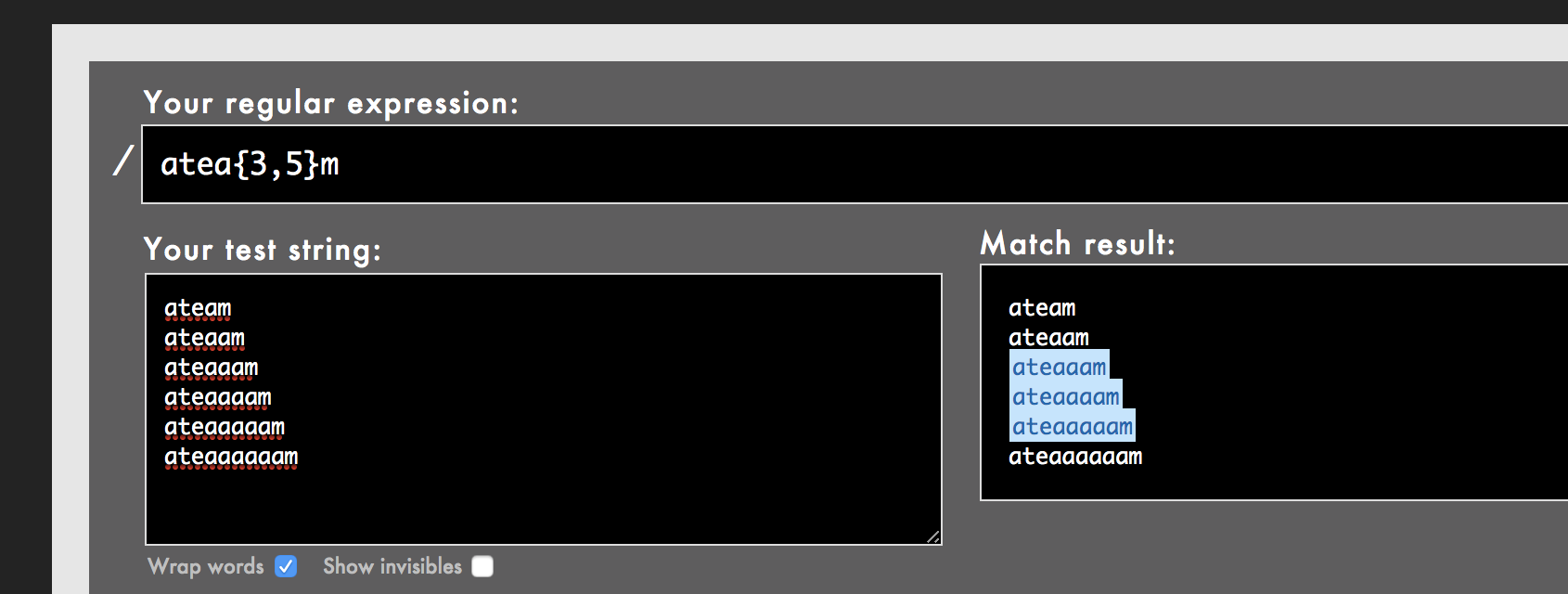
「連続するaが3回以上、5回以下続く」正規表現を描きたい場合は
atea{3,5}m
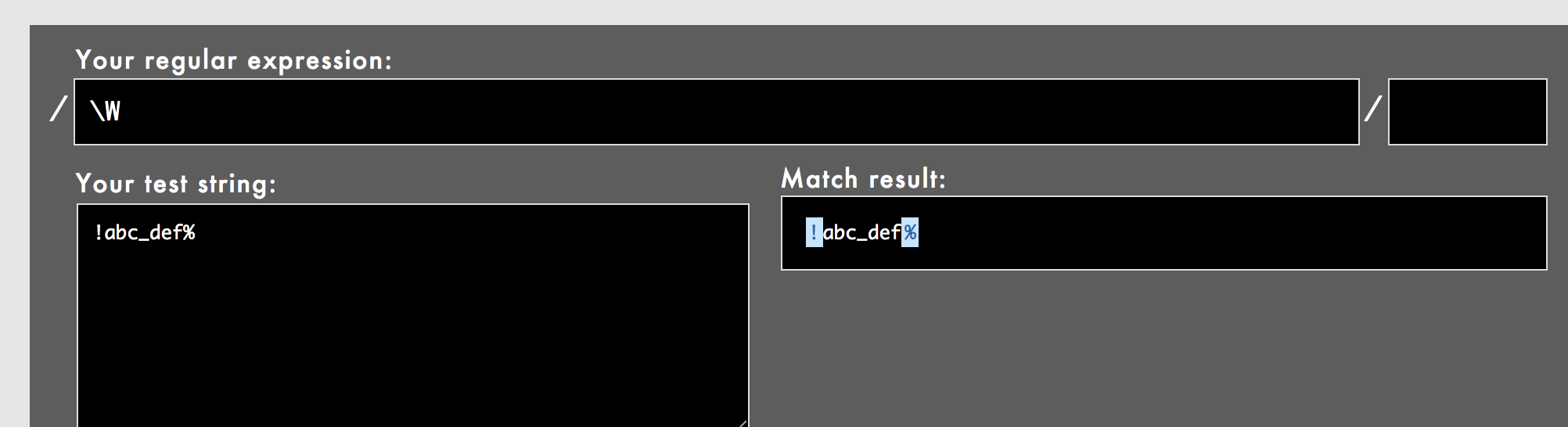
勉強23(\w \s \d が大文字になった \W \S \D は意味が反対になる)
| メタ文字 | 意味 | 例 |
|---|---|---|
| \w | 半角英数字とアンダースコア1文字(英単語の構成文字) | \t\r\n\f\v |
| \W | 半角英数字とアンダースコア1文字以外(英単語の構成文字以外) | % |
| \s | 空白行文字全般 | \t\r\n\f\v |
| \S | 空白行文字全般以外 | \t\r\n\f\v |
| \d | 半角数字 | abc |
| \D | 半角数字以外 | ABC |
\wと\W

\sと\S


\dと\D