はじめに
マーケターが、マーケターらしく、マーケターにしか発揮できない創造的な仕事に専念することを支援した記事です。
御託
マーケティング業務で求められる守備範囲はますます広がりつつあると感じています。
業務では当然、GA、GTM、Googleサーチコンソールなど様々なマーケティングツールを使いこなすことが求められます。
それに加えて、年々高度化するWeb広告の技術理解だけでなく、Webを支える技術(JS, HTML, CSS, ネットワーク, IPアドレス, URL, ドメイン)や、最近では、ReactやNext.JS などの新しい技術にも一定の理解が求められると思います。
これらの技術を、マーケターが知ってる・少しは使えるだけでも、会社の中で相当な価値を発揮できるかもしれません。
それに貢献できれば嬉しいと思って本記事を作成しました。
この記事の内容
正規表現をサポートしている、かつWebマーケティング業務で使われていそうなツールを使って「こう使うと便利!」と思える使い方を紹介します。
2021/04/7 に、Googleサーチコンソールの検索パフォーマンスのレポートが、正規表現フィルタをサポートしたニュースがありました。
また、GoogleSpreadSheet(スプレッドシート)も正規表現をサポートしています。なので、これらのツールを使ってどれくらい業務が便利になるか、実例を踏まえて紹介していきます。
御託
Webに関わるお仕事だと、業務において、URLの一覧や記事(文章)などの大量の検索対象(文字列)の中から、目的の文字列を抽出したいケースは多いですよね。手動で1キーワードつづつやると膨大な時間がかかりますが、そんな時に正規表現を使って時短できるかもしれません。
また、GAを使ってると、特定のURLで発火して欲しいイベントの設置においては、どうしても書かないといけないケースもあります。
そんなケースにおいてマーケターが困らないように、最低限必要な正規表現が書けるスキルを身に付けることを目的にしています。
対象読者
コピペでなんとなく正規表現を使ってるけど、基礎を覚えて業務を効率化させたい方向けです。
正規表現とは?
あいまいな文字列からルールを見つけ出して、パターンで表したものです。
文字列そのものを記述するのではなく、目的の文字列を検索や置換などをするためにはパターン化させたいですよね。
規則(Regular)に基づいた表現(Expression)と言うことで、英語だと Regular Expression と(略して Regex レゲックス とも)言われてます。
検索するときの参考にしてください。
正規表現の主な使い方
- まとめて検索: 大量の文字データから、何種類もある文字列を1回の検索でまとめて見つけ出せます
- 入力チェック(文章チェック): Webサービスのエントリーフォームの入力チェックでよく見かけます
- テキスト編集: 文末の「です。」「ます。」を「である。」「だ。」に一括置換できます
OSが Windows か Mac によって入力するコードが変わってくる問題
見ておいてもらえると助かります。
書いた正規表現をリアルタイムに検証できるツールを使っていきましょう
正規表現に慣れないうちは、どう書けばどんな文字列を探索しているかがわからないと思います。
そんな時、正規表現のルールを頭に叩き込むより
実例を勉強して、理論を学ぶを繰り返し、習うより慣れた方が学習効率が高いです。
そこで、オススメするのがRegExrという、正規表現をすぐ検証できるサイトです。
自分が入力した正規表現が、実際に検索対象の文章中のどの部分にヒットしているかをリアルタイムで確認できます。
これを利用しながら試しながら学習することをお勧めします。
例題. 「郵便番号にマッチする正規表現」
回答は1つではありませんが、郵便番号にマッチする正規表現は次のようになります。
^[0-9]{3}-[0-9]{4}$
| 文字 | 内容 |
|---|---|
| ^ | 直後の文字が行の 先頭 にある場合にマッチ |
| [0-9] | 0から9のいずれか |
| {n} | 直前のパターンを n 回繰り返す |
| $ | 直前の文字が行の 末尾 にある場合にマッチ |

^\d{3}-\d{4}$
| 文字 | 内容 |
|---|---|
| ^ | 直後の文字が行の 先頭 にある場合にマッチ |
| \d | 半角数字。それぞれ 1 文字ずつヒット |
| {n} | 直前のパターンを n 回繰り返す |
| $ | 直前の文字が行の 末尾 にある場合にマッチ |

下記のリンクを見ると、マッチしていることがわかると思います。
正規表現を書く上での基本
正規表現を書く上で、自分は以下の流れで正規表現を記述しています。
1. 固定な部分と、可変する部分を見分ける
2. 可変部のパターンを見分ける
3. 固定部はそのまま、可変部を正規表現で表現
今回の郵便番号のパターンでは
- 固定部分(ハイフン)と可変部分(数字部分)を見極める
- 可変部分(最初はなにかの数字3つ、次は何かの数字4つ)のパターンを見極める
- 固定部分はそのまま、可変部分のパターンを正規表現で書く →
\d{3}-\d{4}
例題. 「Googleサーチコンソールを使って、共通のユーザーニーズから発生したキーワード群を正規表現でまとめて検索」
Googleサーチコンソールを使うと、サイトがどんな検索クエリでやってくるかを把握することができます。
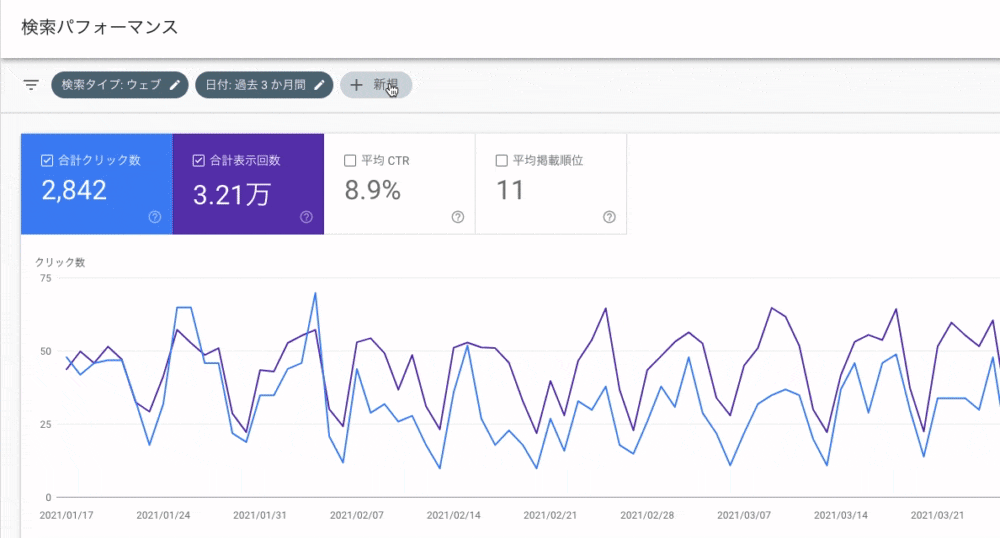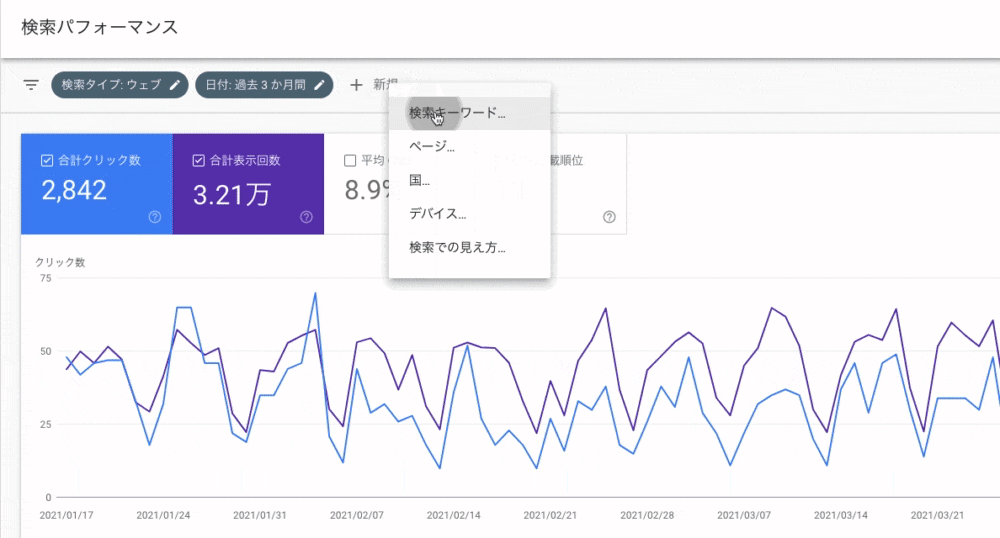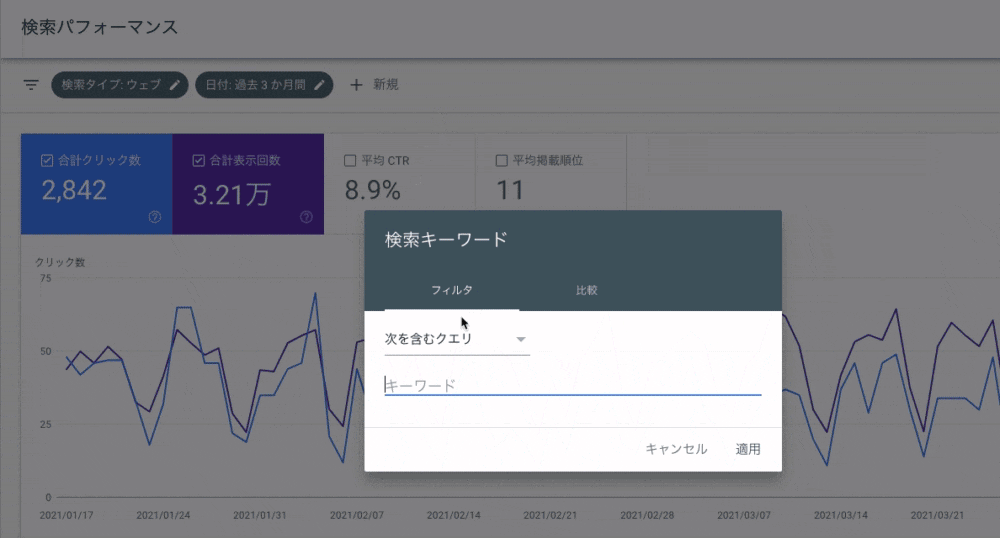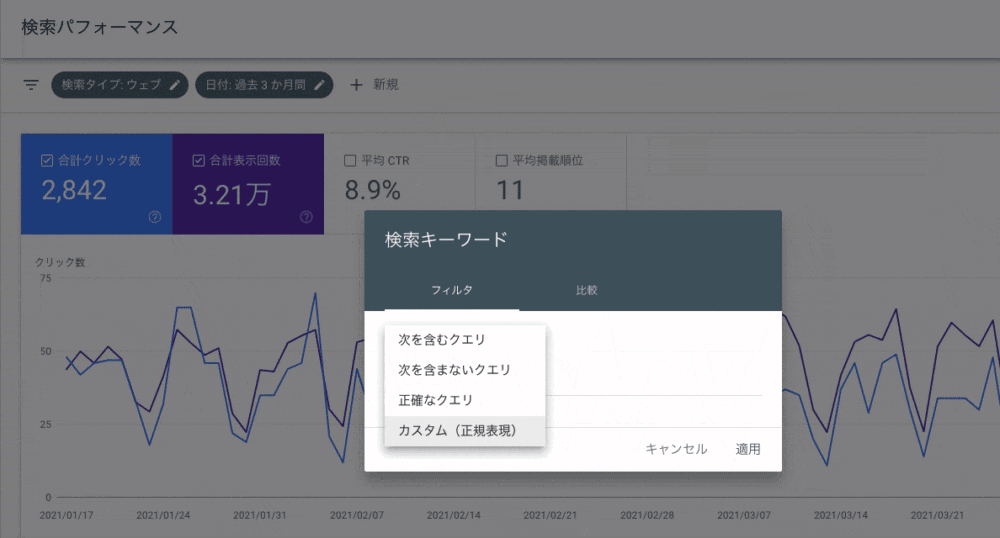
検索パフォーマンスを見ると、サイトにやってきた流入データを日付や、様々なディメンション(検索クエリやページ)ごとに、どのくらい表示されたのか、何回クリックされたのか、そして平均掲載順位などが確認できます。
( ☝️ 筆者が個人的に運営してるブログのサーチコンソールのデータです )
検索パフォーマンスにはフィルタ機能があります。本例題と次では、「クエリ」と「ページ」の正規表現フィルタの活用方法を紹介します。
( ☝️ 筆者が個人的に運営してるブログのサーチコンソールのデータです )
これまでのフィルタの問題点
これまでは、マッチタイプが「完全一致」と「部分一致」だけだったので、ある共通したユーザーニーズから発生するキーワード群をまとめて検索することができませんでした。
例えば、東京のラーメンに関してざっくり情報が知りたい人は「東京 ラーメン」とググる人もいれば「ラーメン 東京」とググる人もいると思います。
ですが、今までは、それらを「完全一致」や「部分一致」では一括検索できませんでした(キーワード「東京 ラーメン」というまとまりで部分一致してしまうので)。
なので、「東京 ラーメン」でフィルタかけて、今度は「ラーメン 東京」でフィルタをかける人も多かったのではないでしょうか?
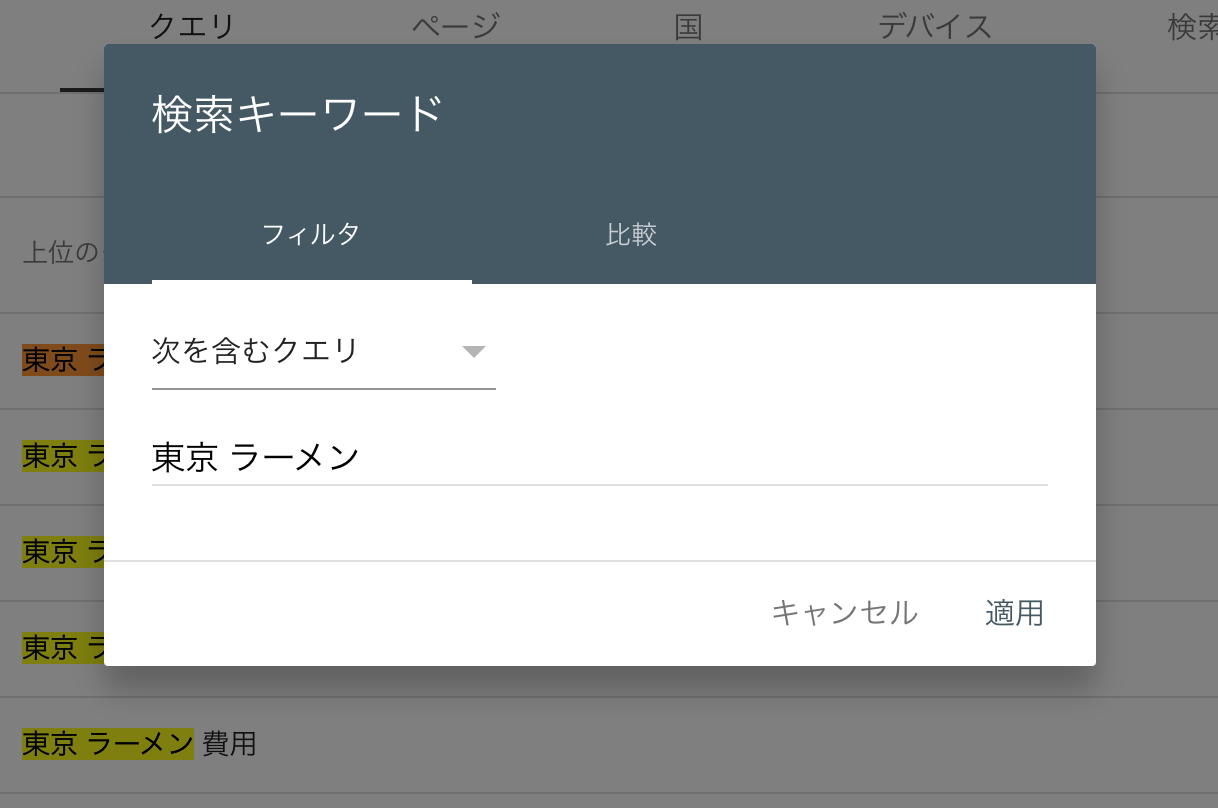
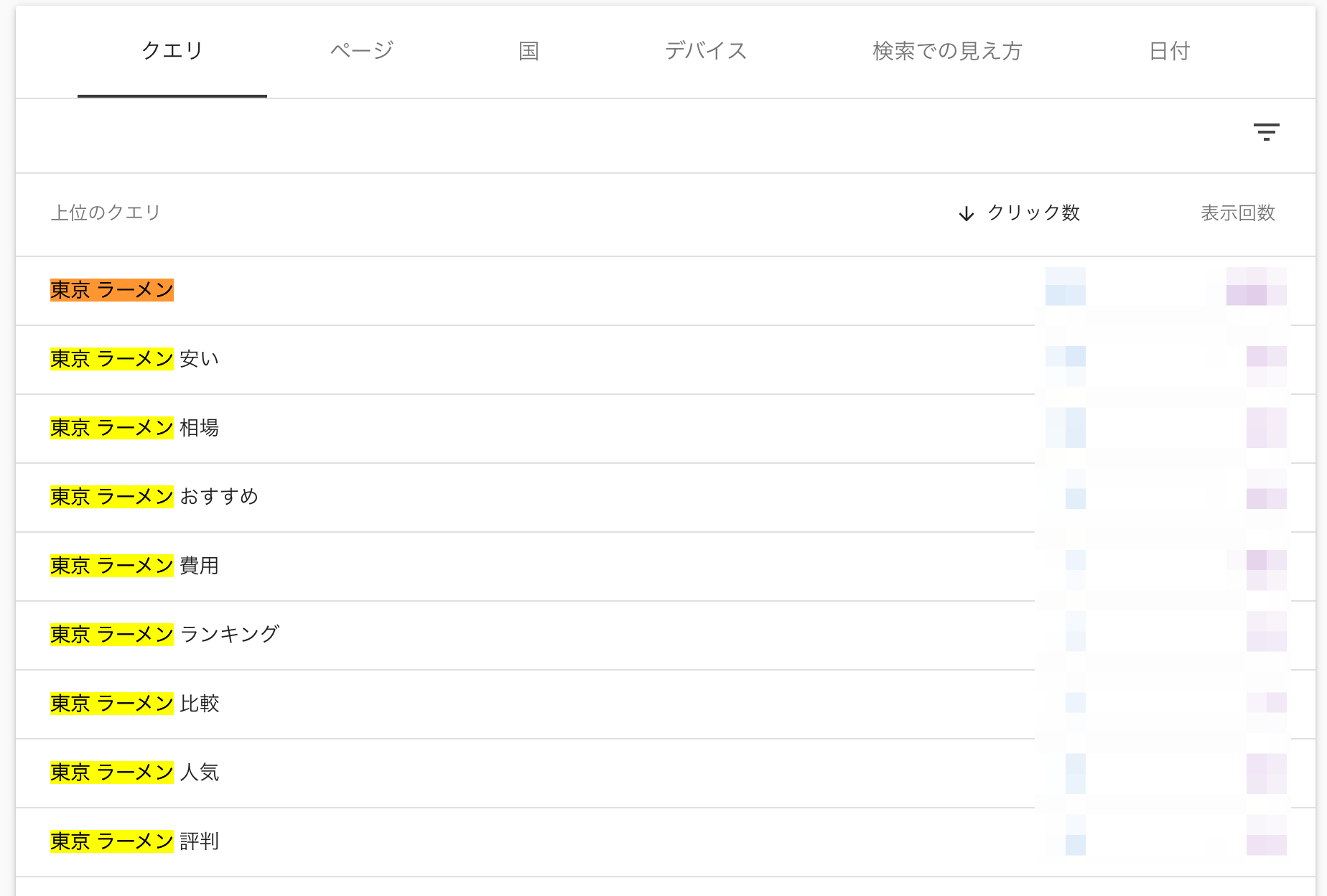
これを今度はスプレッドシートかなんかを使って合算させて分析していたのではないでしょうか?なかなか手間ですよね。
また、もっとパターン数が多い場合は、抽出・合算すること自体が大変です。
2語の複合キーワードの場合
→「AB」「BA」の2パターン
3語の複合キーワードの場合
→「ABC」「ACB」「BAC」「BCA」「CAB」「CBA」の6パターン
そんな時、正規表現フィルタを使えば、1度で検索をかけることができます。
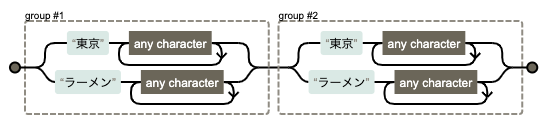
例えばこんな正規表現をかければ、「ラーメン 東京」を順不同かつ、それらの単語を含んで検索をかけることができます。
これで、東京のラーメンに関するユーザーニーズから発生するキーワード群をまとめて検索することができます。
(東京.+|ラーメン.+)(東京.+|ラーメン.+)
| 文字 | 内容 |
|---|---|
| (...) | 文字を1つのグループにまとめる |
| . | 任意の 1 文字 |
| + | 直前のパターンを 1 回以上繰り返す |
| | | OR 条件 |
例題. 「Googleサーチコンソールを使って、URLを必要なグループ単位で正規表現でまとめて検索」
サーチコンソールの検索パフォーマンスのフィルタ機能は、先ほどの「クエリ」以外にも「ページ」にも正規表現フィルタを活用できます。
「ページ」はURLのことだと思ってください。そして、URLの正規表現はググったり、書籍で多くのノウハウ・事例があります。
なのでここでは最低限の紹介に留めます。
グローバルなURLであれば誰でもアクセス可能なので、例題は、どのサイトでもいいでしょう。
今回は下記のWebサイトのURLを使って紹介します。
URLをグループ単位(カテゴリ単位)で分析できるように、まずはこのWebサイトのURLのパターンを調べてみましょう。
https://www.lifedot.jp/
TOPページからたどると地域ごとの商品一覧ページがあります。
suumoやhomesのような、地域ごとの商品一覧ページがあるデータベース型のサイトだということがわかります。
これらのサイトは、URLが同じではないにせよ、構造など共通点が多いです。
また、サイトの運営者でなくても、パンくずや内部リンクからWebサイトを巡回していけばURLのパターンが見えてきます。
サイトマップも参考になるでしょう。ちなみに、homesだと、サイトマップこんな感じですね。
BASEのURL + /sitemap.xml とやれば見つかることが多いです
地域の一覧ページは以下のようなパターンでした。
① /listがない 都道府県のページ
https://www.lifedot.jp/ohaka/pref-tokyo/
② /listがついた 都道府県のページ
https://www.lifedot.jp/ohaka/pref-tokyo/list/
③ /listがついた 何かしらの条件で絞り込んだのページ
https://www.lifedot.jp/ohaka/pref-tokyo/cond-section_type-nokotsu/list/
④ /listがついた 何かしらの条件で並び替えたページ(並び順はGETパラメータ)
https://www.lifedot.jp/ohaka/pref-tokyo/list/?order=price
⑤ /listがついた 都道府県に紐づいた市区町村のページ
https://www.lifedot.jp/ohaka/pref-tokyo/city-661/list/
⑥ /listがついた 何かしらの条件で絞り込んだ 都道府県に紐づいた市区町村のページ
https://www.lifedot.jp/ohaka/pref-tokyo/city-661/cond-section_type-normal/list/
⑦ /listがついた 何かしらの条件で並び替えた(並び順はGETパラメータ) 都道府県に紐づいた市区町村のページ
https://www.lifedot.jp/ohaka/pref-tokyo/city-661/list/?order=price
(2021/04 時点で確認したところ、上記のようなパターンが見られました)
これらのパターンはこのサイトじゃなくても、suumoやhomesでもすぐわかるかと思います。
例えば、① だけのパターンは、おそらく xxx の部分が都道府県ごとにあると思います。
https://www.lifedot.jp/ohaka/pref-xxx/
/list がつかないパターンが ① のパターンのみの場合、
正規表現の否定的先読み(negative lookahead)という方法を用いれば表現できます。
既に述べましたが、正規表現を書くときの手順
1. 固定な部分と、可変する部分を見分ける
2. 可変部のパターンを見分ける
3. 固定部はそのまま、可変部を正規表現で表現
/list が付いていない pref- + 1文字以上のword というパターンなのを正規表現に表すと...
例えばこんな正規表現をかければ、/listなしの全都道府県ごとのURLを検索することができます。
(?!.+list)ohaka\/pref-.+?\/$
| 文字 | 内容 |
|---|---|
| (?!正規表現) | 正規表現はマッチに含めたくない |
| \ | 直後の正規表現記号をエスケープ |
| . | 任意の 1 文字 |
| + | 直前のパターンを 1 回以上繰り返す |
| ? | 直前の繰り返し指定を最短一致でマッチ。できるだけ短くヒットさせます |
| $ | 直前の文字が行の 末尾 にある場合にマッチ |
👇 正しく検索できていることがわかります。
しくみを図解すると下記のような感じです。

上記はテストツールをみてもわかる通り、間違った正規表現ではありません。ですが、サーチコンソールでは想定通り動きません。
なぜなら、細かい話をすると、Googleサーチコンソールの正規表現はRE2というGoogle製の正規表現ライブラリを採用しているからです。
RE2は、他の正規表現ライブラリと比較しても高速みたいです。なぜなら、RE2以外の正規表現ライブラリの多くは、バックトラッキングという探索方法を採用しているおかげで、否定的先読み(negative lookahead)などの便利機能が搭載されている代わりに処理に時間がかかる場合があるというデメリットがあるかららしい。
RE2はオートマトン理論を用い、正規表現検索が入力のサイズに対し線形の時間内に走ることを保証しているそうです。
高速であることをメリットの1つとしている以上、遅くする原因になるような機能、例えば否定的先読み(negative lookahead)は今後もサポートしないだろうなと思います。
以下のISSUEを見ても、なんとなく察することができます。
否定的先読み(negative lookahead)は、慣れてくるとすごく便利な機能です。ですが、なぜか使えない場合にその理由が分からなくなり時間をかけ過ぎてしまうかもしれません。なのでマーケターの皆さんでも、正規表現をサポートしてるツールは、どんな正規表現ライブラリを採用していて、それができること・できないことをチラッとでも調べることは実は結構大事かなと思います。(なかなか難しいかもしれませんが...)
ちなみに、他の正規表現ライブラリの一覧は 👇
ちなみに、否定的先読み(negative lookahead)は、以下の記事が参考になりました。
- 正規表現で文字列を含まない、否定の記述 | UX MILK
- はじめての正規表現とベストプラクティス#4 先読みと後読みを極める|TechRacho(テックラッチョ)〜エンジニアの「?」を「!」に〜|BPS株式会社
- 一歩先 "読む" 正規表現 ~先読みを理解せよ~ - Speee DEVELOPER BLOG
話は戻り、サーチコンソールで/list が付いていない pref- + 1文字以上のword というパターンなのを正規表現はどう書くかと言うと...
力技かもしれませんが、以下の書き方でも取得できなくはありません
ohaka/pref-(hokkaido|aomori|iwate|miyagi|akita|yamagata|fukushima|ibaraki|tochigi|gunma|saitama|chiba|tokyo|kanagawa|niigata|toyama|ishikawa|fukui|yamanashi|nagano|gifu|shizuoka|aichi|mie|shiga|kyoto|osaka|hyogo|nara|wakayama|tottori|shimane|okayama|hiroshima|yamaguchi|tokushima|kagawa|ehime|kochi|fukuoka|saga|nagasaki|kumamoto|oita|miyazaki|kagoshima|okinawa)/$
| 文字 | 内容 |
|---|---|
| (...) | 文字を1つのグループにまとめる |
| $ | 直前の文字が行の 末尾 にある場合にマッチ |
| | | OR 条件 |
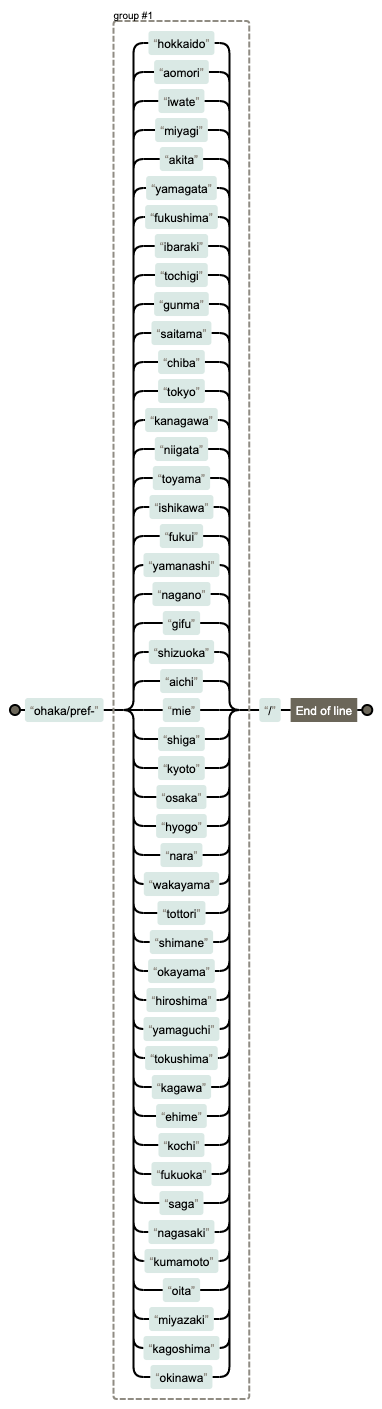
もっとスマートな書き方があれば是非教えて欲しいです!💦
他にも list/ が付いているものだけ検索する正規表現は...
ohaka\/pref-.+?\/.+list\/
| 文字 | 内容 |
|---|---|
| \ | 直後の正規表現記号をエスケープ |
| . | 任意の 1 文字 |
| + | 直前のパターンを 1 回以上繰り返す |
| ? | 直前の繰り返し指定を最短一致でマッチ。できるだけ短くヒットさせます |
テストツールを確認してもOKそうですね(他のURLパターンがあればNGかもしれません)。
サーチコンソールで正常に動作するpref-xxx/listパターンを正規表現はどう書くかと言うと...
ohaka/pref-(hokkaido|aomori|iwate|miyagi|akita|yamagata|fukushima|ibaraki|tochigi|gunma|saitama|chiba|tokyo|kanagawa|niigata|toyama|ishikawa|fukui|yamanashi|nagano|gifu|shizuoka|aichi|mie|shiga|kyoto|osaka|hyogo|nara|wakayama|tottori|shimane|okayama|hiroshima|yamaguchi|tokushima|kagawa|ehime|kochi|fukuoka|saga|nagasaki|kumamoto|oita|miyazaki|kagoshima|okinawa)/list/$
でしょうか。
| 文字 | 内容 |
|---|---|
| (...) | 文字を1つのグループにまとめる |
| . | 任意の 1 文字 |
| $ | 直前の文字が行の 末尾 にある場合にマッチ |
次に、city-xxxをもつ一覧ページのパターンを正規表現でどう書くかと言うと...
ohaka\/pref-.+?\/city-\d.+\/.+list\/
| 文字 | 内容 |
|---|---|
| \ | 直後の正規表現記号をエスケープ |
| . | 任意の 1 文字 |
| + | 直前のパターンを 1 回以上繰り返す |
| ? | 直前の繰り返し指定を最短一致でマッチ。できるだけ短くヒットさせます |
| \d | 半角数字。それぞれ 1 文字ずつヒット |
テストツールを確認してもOKそうですね(他のURLパターンがあればNGかもしれません)。
しくみを図解すると下記のような感じです。

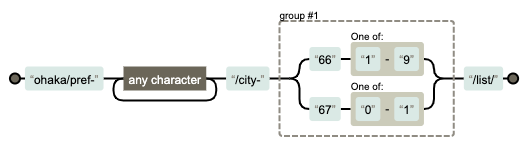
次に、city-661からcity-671の間の数字をもつパターンを正規表現はどう書くかと言うと...
ohaka\/pref-.+?\/city-(66[1-9]|67[0-1])\/list\/
| 文字 | 内容 |
|---|---|
| \ | 直後の正規表現記号をエスケープ |
| [0-9] | 0から9のいずれか |
| . | 任意の 1 文字 |
| + | 直前のパターンを 1 回以上繰り返す |
| | | OR 条件 |
| ? | 直前の繰り返し指定を最短一致でマッチ。できるだけ短くヒットさせます |
| (...) | 文字を1つのグループにまとめる |
テストツールを確認してもOKそうですね(他のURLパターンがあればNGかもしれません)。
しくみを図解すると下記のような感じです。
数値範囲の正規表現を自動生成してくれるツールもあるので活用してください。
ツールを使ったとしても正規表現の仕組みはちゃんと理解しておきましょう。
例題. 「Googleスプレッドシートで住所(所在地)を分割して取得する方法」
ここでは、正規表現を使ってスプレッドシートのREGEXEXTRACT関数とREGEXREPLACE関数を使って、住所(所在地)を便利に抽出する方法を紹介したいと思います。
正規表現が使える関数
| 関数名 | 概要 |
|---|---|
| REGEXEXTRACT | 正規表現に従って文字列を抽出できる |
| REGEXREPLACE | 正規表現に従って文字列を空白や任意の文字列に置換できる |
上記以外にも、正規表現が使える関数はありますが、今回は最も使用頻度が高そうなものだけを選びました。
構文
REGEXEXTRACTの構文
=REGEXEXTRACT("検索対象の文字列","抽出(正規表現)")
REGEXREPLACEの構文
=REGEXREPLACE("検索対象の文字列","抽出(正規表現)", "置換後の文字列")
これらを使って、Googleスプレッドシート上にある住所(所在地)から
- 都道府県名
- 市区町村名
- それ以外
を分割して取得する方法を紹介します。
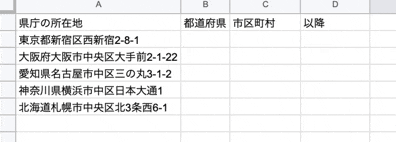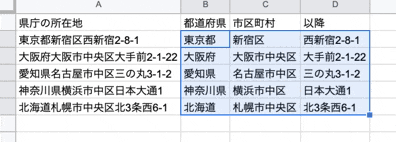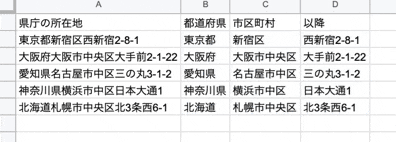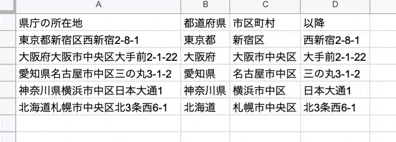
まずは、住所(所在地)から都道府県名を取得します。
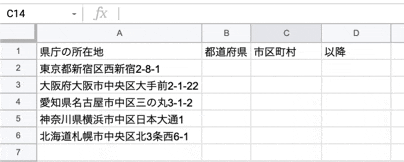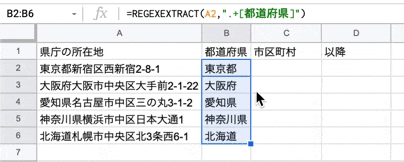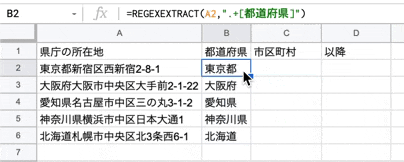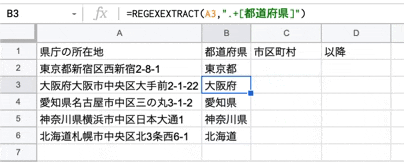
関数は以下です。
=REGEXEXTRACT("検索対象の文字列",".+[都道府県]")
使ってる正規表現
| 文字 | 内容 |
|---|---|
| . | 任意の 1 文字 |
| + | 直前のパターンを 1 回以上繰り返す |
| [...] | [...]に含まれるいずれか1文字にマッチ |
次に、住所(所在地)から市区町村を取得します。
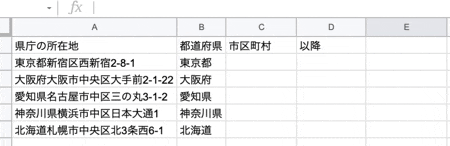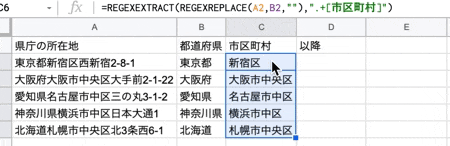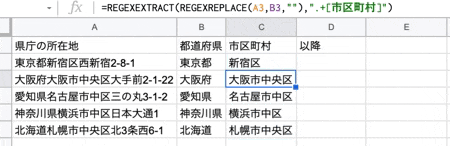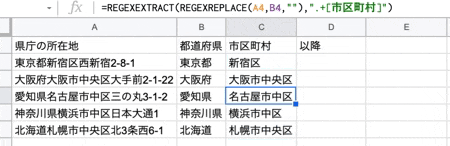
関数は以下です。
=REGEXEXTRACT(REGEXREPLACE("検索対象の文字列","県名が格納された文字列",""),".+[市区町村]")
上記は何をやっているかと言うと、例えば、東京都新宿区西新宿2-8-1 の場合、まず東京都新宿区 を取得して、都道府県名を空文字に置換した結果新宿区だけが返されます。と言う感じです。
さいごに、住所(所在地)から市区町村名以降の文字列を取得します。
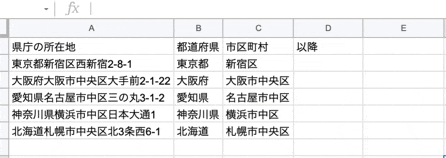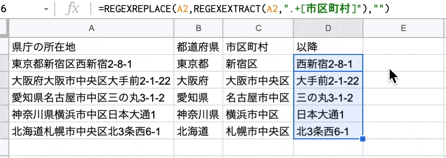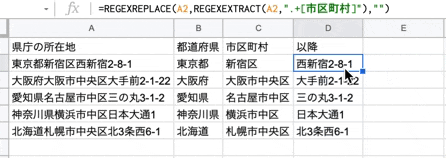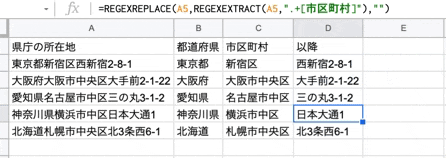
関数は以下です。
=REGEXREPLACE("検索対象の文字列",REGEXEXTRACT("検索対象の文字列",".+[市区町村]"),"")
何をやっているかと言うと、例えば、東京都新宿区西新宿2-8-1 の場合
抽出した文字列 東京都新宿区西新宿2-8-1 から 東京都新宿区 を 空文字にした結果
市区町村名以降の文字列が取得できた。と言う感じです。
大事なこと
ある程度正規表現に慣れてくるとわかるかもしれませんが、、、
これは正規表現あるあるで、厳密に書こうとすればするほど、正規表現はどんどん複雑になります。
例えばGoogleで
メールアドレス 正規表現 厳密
とか調べてみてください。すると、とても複雑な正規表現がでてきますよね?
厳密であれば確かに間違いはなくなると思いますが、
業務においては、ミスはある程度許容できるものだったり、厳密性が求められないことはしばしばあります。
そんなとき、いちいち正規表現を厳密に書くために時間をかける必要はありません。
工数が削減できればいいんです。 ぜひ、沼にはまらず楽をしてください。
さいごに、上記と矛盾してるかもしれませんが、正規表現を書く時の注意点を2つあげます。
- 抽出したいパターンはモレなく抽出できたか?
- 抽出したくないパターンはモレなく抽出されていないか?
正規表現を実際に書くシーンでは、どこまで抽出させるべきかというのを、ご自身の目的に合わせて正規表現を書いていきましょう。
参考
さらに学習を進めたい方へ
理解しないと気が済まない方は、以下の学び方をお勧めします。
👇 を一通り、テストツールで実際書きながら読む(土日でガッツリやるか。1週間だけ1-2時間毎日やれば読めます)。
次に、👇 を例題を解きまくります。何度も何度も。
ここまでできれば、マーケターとしては十分すぎると思います。
正規表現の魅力に取り憑かれてしまった方は以下の書籍を読めば、もう完璧だと思います。
ただし、エンジニアじゃない方にはあまりお勧めしません。
以上です。ありがとうございました。