はじめに
Pycaret3.0からPycaretに時系列分析が追加されたということだったので、試してみました。
pycaret 3.0のインストール
pycaret 3.0はまだ、RC版のため通常ではインストールできません。
以下のように「--pre」をつけてインストールしてみてください。
!pip install --pre pycaret
試したこと
今回は、日経平均株価の予測というタスクを試してみました。
日経平均株価を直接取得する方法はわからないかったので、今回は銘柄コード「1321」の「Nomura NF Nikkei 225 ETF」を使って予測モデルを作成しました。
コードはこちらにアップしております。
(google colaboratoryの利用を想定しています。)
まず、必要なモジュールのインポート
import os
import datetime as dt
from datetime import datetime, timedelta
import pandas_datareader.data as web
import pandas as pd
from pycaret.time_series import *
import numpy as np
DataReaderを使って、データのダウンロードを実施
データローダを利用して、今回は銘柄コード「1321」の「Nomura NF Nikkei 225 ETF」の銘柄を予想します。
皆さんも確認したい銘柄コードを入力してみてください。
#銘柄コード入力
ticker_symbol="1321"
ticker_symbol_dr=ticker_symbol + ".JP"
#2017-01-01以降の株価取得
start='2017-01-01'
end = dt.date.today()
#データ取得
df = web.DataReader(ticker_symbol_dr, data_source='stooq', start=start,end=end)
#2列目に銘柄コード追加
df.insert(0, "code", ticker_symbol, allow_duplicates=False)
pycaret の時系列分析では日付の欠損値が許容されないようなので、休日や祝日の値も補完します。
# 開始日付から2000日分の日付データを作成する
date = pd.date_range(start, periods=2000, freq="D")
date_df = pd.DataFrame({"Date": date})
# 作成した日付データとマージする。
df = pd.merge(date_df, df, on="Date", how="left")
df = df.reset_index()
data = df[['Date','Close']]
# 日付データをpd.Period形式に変換する。(pycaretの日付データがpd.Period形式しか受け付けていないため。)
tmp_list = []
for i in range(data.shape[0]):
#idx = pd.date_range(data.index[i], periods=1)
#idx = idx.to_period()
idx = pd.Period(data.Date.iloc[i],freq='1D')
tmp_list.append(idx)
data['date'] = np.array(tmp_list)
# 欠損値を線形補完する。
data = data.set_index('date')
data = data.drop('Date',axis=1)
data['Close'] = data['Close'].interpolate(axis=0,limit_direction='both')
# 訓練データとテストデータに分ける。
test_days = dt.timedelta(days=60)
end_val = (end - test_days).strftime('%Y-%m-%d')
df_train = data[data.index <= end_val]
df_test = data[data.index > end_val]
データセットの準備をする
30日ぐらいの予測がしたかったこと、周期性は取りあえず1週間位という想定、時系列分析で交差検証がどういう意味があるのかわからなかったこともあり、
fh:forcast horizon (予測対象期間)
seasonal_priod:周期
fold:交差検証の検証数
s = setup(df_train, fh = 30, session_id = 123,seasonal_period = 7,fold=1)
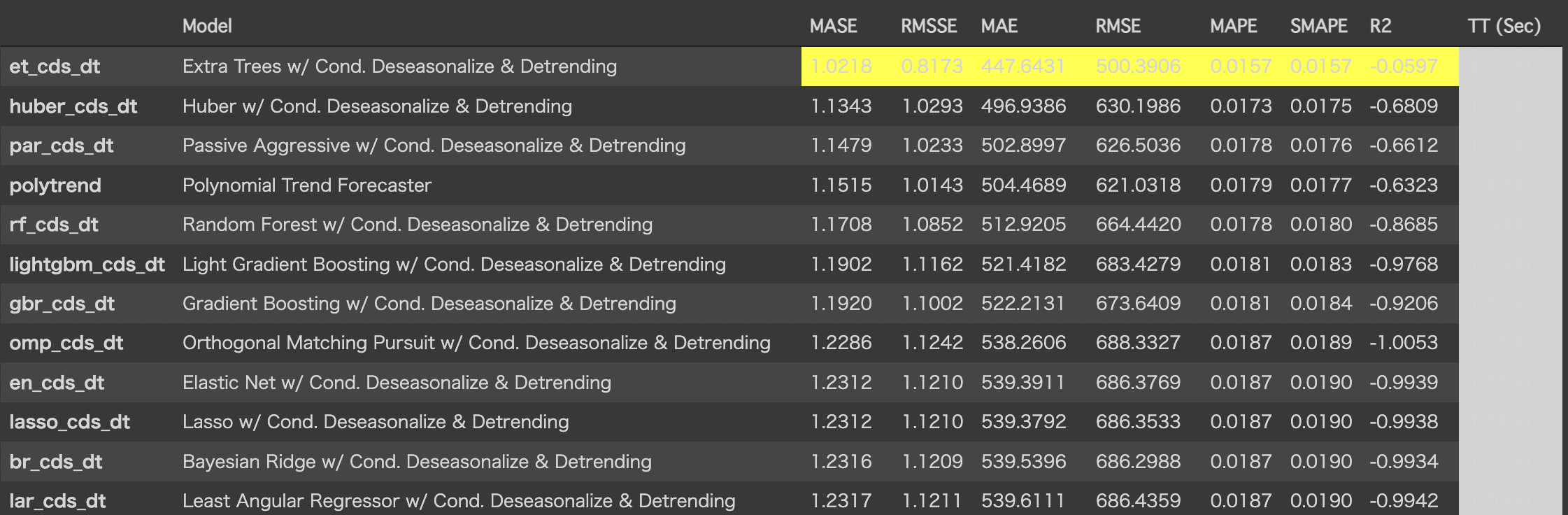
モデル比較の実施
# compare models
best = compare_models()
今回は、et_cds_dtのモデルが一番精度が高かったようなので採用
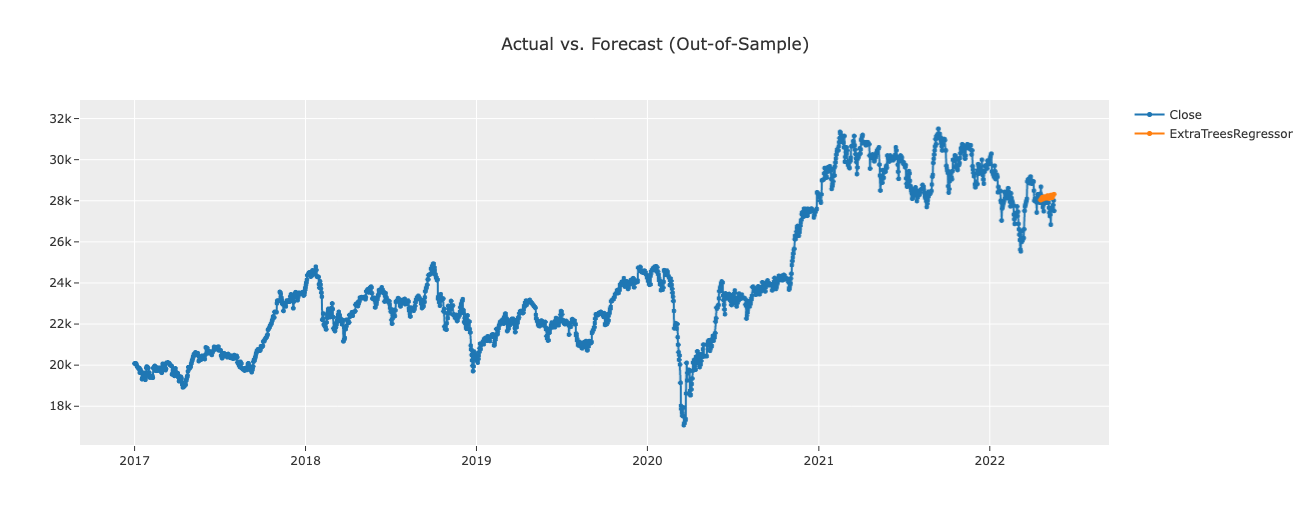
予測結果の出力
# forecast plot
plot_model(best, plot = 'forecast')
全然予測出来てないですね。。。。
考察
今回、取りあえずPycaret 3.0から時系列データに対応するということで、取りあえず使ってみました。
あまり、使い方がわかっていないことなどもありますが、特徴量が一つしか扱えず、周期性データも自分で入れたりする必要があるので、かなり周期性のハッキリしたしたデータでないと難しいような気がしました。
また、祝日や休日のカレンダーなんかも欲しい気がします。
通常のpycaretの回帰や分類分析は、「取りあえず、そのまま予測させてみよう。」という感じで使っているのですが、時系列データは今のところそんな感じではなさそうに思います。
ただ、メリットとしての色々なモデルを一気に分析させるというところはあるので、時系列分析で試す選択肢の一つには入れてもいいのかもしれません。
今回は、取りあえず使ってみたという所感となります。。。
また、pycaret 3.0の新機能などについても出来ればレポートしてみようかと思います。