はじめに
過去にOpenMMLabが提供するMMDetectionやMMSegmentation、MMOCRを紹介させていただきましたが、今回は画像生成に対応するMMGerationについて紹介させていただきたいと思います。
今回は、チュートリアルをベースに学習済みモデルを使った利用方法について、みていきたいと思います。
なお、コードはこちらになります。

ボタンをクリックして、google colaboratoryでそのまま実行可能です。
MMGenerationとは
主にGANに特化した画像生成モデルを集めたツールセットで2022/7/22現在で16のモデルと、100個の事前学習済みのモデルが用意されています。
利用できるモデルはこちら
環境準備
必要なモジュールのインポート
import torch
import json
from skimage import measure
import numpy as np
import matplotlib.pyplot as plt
import cv2
print(torch.__version__)
device = "cuda" if torch.cuda.is_available() else "cpu"
print("device = ", device)
MMGenerationで使用するMMCVのインストール
# MMCVのインストール
!pip install -U openmim
!mim install mmcv-full
MMGenerationのインストール
!git clone https://github.com/open-mmlab/mmgeneration.git
%cd /content/mmgeneration
!pip install -v -e . # or "python setup.py develop"
これでMMGenerationの利用環境が整いました。
ランダムに人の顔の画像を生成
StyleGANを使って、ランダムに人の顔の画像を生成します。
方法は、モデルを指定するコンフィグファイルと学習済みモデルが保存されたパスを指定します。
import mmcv
from mmgen.apis import init_model, sample_unconditional_model
# Specify the path to model config and checkpoint file
config_file = 'configs/styleganv2/stylegan2_c2_ffhq_1024_b4x8.py'
# you can download this checkpoint in advance and use a local file path.
checkpoint_file = 'https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_1024_b4x8_20210407_150045-618c9024.pth'
# init a generatvie
model = init_model(config_file, checkpoint_file, device=device)
# sample images
fake_imgs = sample_unconditional_model(model, 4)
生成した画像の表示
images = []
plt.figure(figsize=(24,16))
m = fake_imgs.cpu().numpy().shape[0]
for i,image in enumerate(fake_imgs.cpu().numpy()):
image = image.transpose(1,2,0)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
images.append(image)
plt.subplot(1,m,i+1)
plt.imshow(image)
plt.show()
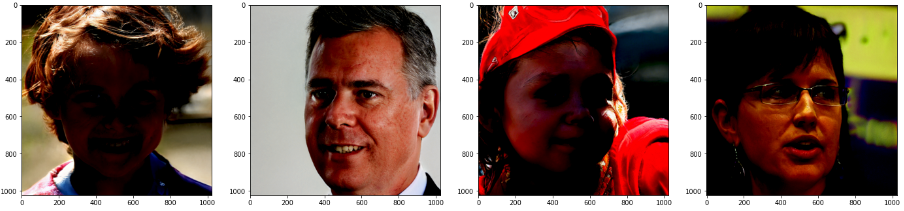
普通に写真だと言われてもわからないですね。
左から3番目が少し不自然かもしれませんが、そういう写真もあると思います。
やはり白人率が高いですね。(一番右は白人ではないかな?)
ラベル毎に画像生成
BigGANを使って、ラベルで指定した画像を合成してみます。
ラベルはImageNetのラベルになります。
こちらをアップロードしてますので、こちらを参照して色々な画像を作って遊んでみてください。
import mmcv
from mmgen.apis import init_model, sample_conditional_model
# Specify the path to model config and checkpoint file
config_file = 'configs/sagan/sagan_128_woReLUinplace_noaug_bigGAN_Glr-1e-4_Dlr-4e-4_ndisc1_imagenet1k_b32x8.py'
# you can download this checkpoint in advance and use a local file path.
checkpoint_file = 'https://download.openmmlab.com/mmgen/sagan/sagan_128_woReLUinplace_noaug_bigGAN_imagenet1k_b32x8_Glr1e-4_Dlr-4e-4_ndisc1_20210818_210232-3f5686af.pth'
# init a generatvie
model = init_model(config_file, checkpoint_file, device=device)
# sample images with random label
fake_imgs1 = sample_conditional_model(model, 4)
# sample images with the same label
fake_imgs2 = sample_conditional_model(model, 4, label=0)
# sample images with specific labels
fake_imgs3 = sample_conditional_model(model, 4, label=[0, 1, 2, 3])
ラベル0(コイ)の出力結果

上の人の顔の生成に比べるとやや不自然な画像が多くなります。やはり1000ラベルでの学習になるため、一ラベルの学習に比べると精度は落ちるようです。
また、釣ったコイ持っている写真が多いですね。
そういう学習データが多いのだと思います。
ラベル0-3の出力結果
- ラベル0: "tench, Tinca tinca"(コイ目コイ科に属する魚類の一種)
- ラベル1: "goldfish, Carassius auratus"(金魚)
-ラベル2: "great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias"(ホホジロザメ) - ラベル3: "tiger shark, Galeocerdo cuvieri"(イタチザメ)

左の二つはちょっとよくわかりませんね。。。
魚ばかりなので、もう少しやってみます。
ラベル100-103の出力結果
- ラベル100: "black swan, Cygnus atratus"(コクチョウ)
- ラベル101: "tusker"(キバを持った動物(猪など))
-ラベル102: "echidna, spiny anteater, anteater"(ハリモグラ) - ラベル103: "platypus, duckbill, duckbilled platypus, duck-billed platypus, Ornithorhynchus anatinus"(カモノハシ)
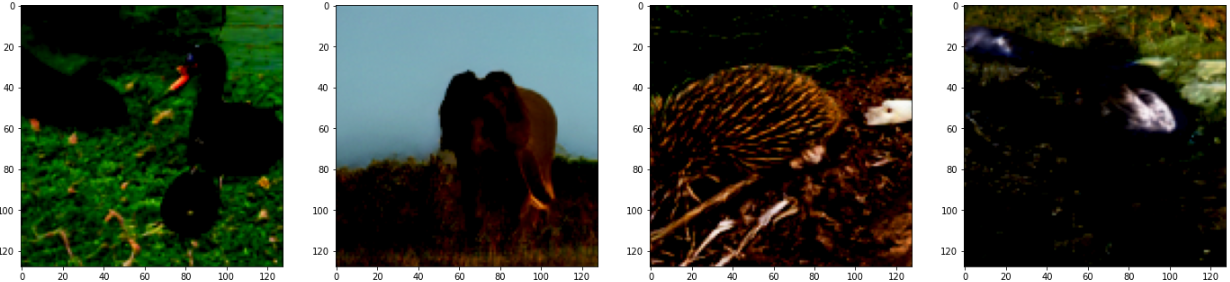
しかし、ImageNetのラベルってかなりマニアックですね。
私も50%ぐらいしか正解できないじゃないかと思います。。。
Image Translation
おそらく線画と写真を変換するのだと思うのですが、イマイチ使い方がわかりません。
サンプルコードを動かしてみましたので、取りあえず結果を掲載します。
(後で分かったら編集します。)
import mmcv
from mmgen.apis import init_model, sample_img2img_model
# Specify the path to model config and checkpoint file
config_file = 'configs/pix2pix/pix2pix_vanilla_unet_bn_wo_jitter_flip_edges2shoes_b1x4_190k.py'
# you can download this checkpoint in advance and use a local file path.
checkpoint_file = 'https://download.openmmlab.com/mmgen/pix2pix/refactor/pix2pix_vanilla_unet_bn_wo_jitter_flip_1x4_186840_edges2shoes_convert-bgr_20210902_170902-0c828552.pth'
# Specify the path to image you want to translate
image_path = 'tests/data/paired/test/33_AB.jpg'
# init a generatvie
model = init_model(config_file, checkpoint_file, device=device)
# translate a single image
translated_image = sample_img2img_model(model, image_path, target_domain='photo')
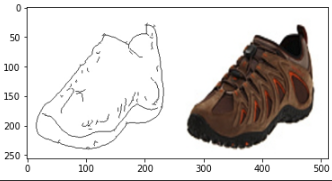
サンプル画像
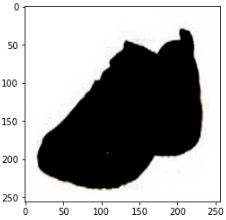
出力画像
Interolation
画像間を補完しながらモーフィング動画を作成していきます。
!python apps/interpolate_sample.py \
configs/styleganv2/stylegan2_c2_ffhq_256_b4x8_800k.py \
https://download.openmmlab.com/mmgen/stylegan2/stylegan2_c2_ffhq_256_b4x8_20210407_160709-7890ae1f.pth \
--export-video \
--samples-path ./work_dirs/interpolate_sample/ \
--endpoint 6 \
--interval 60 \
--space z \
--seed 12 \
--sample-cfg truncation=0.8
出力

今回は、MMGenerationを使ってみましたという内容になります。
今後、GANの学習方法やそれぞれのモデルの学習や使い方のサンプルコードなどもあげていこうと思っています。