初めに
gaccoにて、統計学入門を受講して、e-statの紹介の講義を受講してみました。
試しに、e-statAPIを使ってみましたので、
簡単に使い方を説明したいと思います。
E-statのページ
こちらのページでそのままデータを分析することもできますが、応用して使える様に
なるためにAPIを利用してJupyter Notebook上で分析できる様になりたいと思います。
詳細は、詳しい使い方は以下のページを参照して頂き、ここではとりあえず動かしてみてみるという内容を記載します。
ユーザー登録
APIを利用するには、まずユーザー登録が必要です。
eStats APIのページにアクセスして、ユーザー登録を行った後、マイページから「API機能(アプリケーションID発行)」を選択して、アプリケーションIDを発行します。
上記については、他の解説ページと内容が異なっており(e-stat内の説明ページも誤っていました。)、最近ページ構成が変わったのではないかと思います。
APIの使い方については、API仕様を参照してください。
ここでは、家計調査を利用して、各家計のさつまいもの消費に関するデータの確認した内容について記載します。
Pythonコード
import urllib
import requests
import csv
import pandas as pd
import matplotlib.pyplot as put
appID = ***** #取得したアプリケーションIDを記載
CSVファイルとして、ターゲットデータをダウンロードする。
# csv生成
def get_csv(params_dict):
base_url = "https://api.e-stat.go.jp/rest"
params_str = urllib.parse.urlencode(params_dict)
version = "3.0"
url = (
f"{base_url}/{version}"
f"/app/getSimpleStatsData?{params_str}"
)
r = requests.get(url)
with open(target_file, 'w', encoding='utf-8') as f:
f.write(r.content.decode('utf-8'))
# 家計データのターゲットコードを取得する(今回はさつまいも)
params_dict = {
"cdCat01":"010512010", #さつまいもを表すコード(コードはe-statの統計ページで確認してください)
"appId": appID,
"lang": "J",
"statsDataId": "0003348239", # 家計調査を表すコード、こちらも実際のe-statの統計ページを確認してください。
"metaGetFlg": "Y",
"cntGetFlg": "N", # Yにすると件数のみ、Nにすると統計データ
"explanationGetFlg": "N",
"annotationGetFlg":"Y",
"sectionHeaderFlg":2 # 説明ようのヘッダーを除外する場合は2
}
get_csv(params_dict)
df = pd.read_csv(target_file)
CSVファイルをデータフレームにまとめて格納する(都道府県ごとのデータに分割する)
df_all = pd.DataFrame()
i = 0
for name, group in df[df['世帯区分(年次-二人以上の世帯)'] == '二人以上の世帯(2000年~)'].groupby('地域区分'):
if i ==0:
df_all = group[['品目分類(2020年改定)','時間軸(年次)','value']].rename(columns={'value':name}).reset_index(drop=True)
else:
tmp_df = group[['value']].rename(columns={'value':name}).reset_index(drop=True)
df_all = pd.concat([df_all,tmp_df],axis=1)
i += 1
fig = plt.figure(figsize=(8,12))
ax1 = fig.add_subplot(2,1,1)
plt.ylim(0,1600)
plt.xticks(rotation=90)
ax1.plot(df_all['時間軸(年次)'].dropna(),df_all['01100 札幌市'].dropna(),label='Sapporo')
ax1.plot(df_all['時間軸(年次)'].dropna(),df_all['02201 青森市'].dropna(),label='Aomori')
ax1.plot(df_all['時間軸(年次)'].dropna(),df_all['03201 盛岡市'].dropna(),label='Moriokai')
ax2 = fig.add_subplot(2,1,2)
ax2.plot(df_all['時間軸(年次)'].dropna(),df_all['全国'][:14],label='all')
ax2.plot(df_all['時間軸(年次)'].dropna(),df_all['13100 東京都区部'][:14],label='Tokyo')
ax2.plot(df_all['時間軸(年次)'].dropna(),df_all['27100 大阪市'][:14],label='Osaka')
plt.ylim(0,1600)
ax1.legend()
plt.xticks(rotation=90)
ax2.legend()
fig.show()
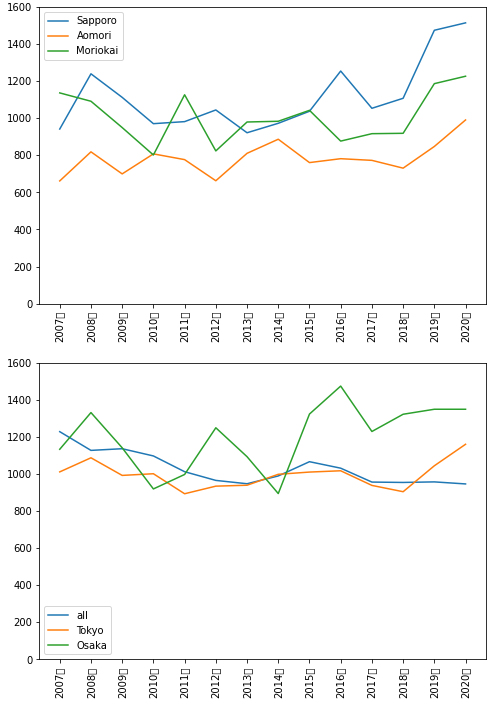
考察
別の課題でちょっと調べてみたのですが、北国(北海道、青森、岩手)などので2019年からさつまいも
の消費が増えているっぽい(東京も少し同じ傾向があるかもしれません。)ことがわかりました。
このくらいの分析であれば、API使わない方が早いと思いますが、他のデータと組み合わせたりといったことなると、APIの利用が推奨されるかと思います。
本来であれば、CSVよりJSONのAPIを利用した方が汎用性がありそうですが、今回は手早く結果をみてみたかったのでCSVをダウンロードしてみてみました。