はじめに
Acrobat Services APIは、Adobeが提供するクラウドベースのPDFサービスです。このサービスを利用すると、様々なPDF関連作業を自動処理させる事が出来ます。その中でも、普段行う事が多いPDF変換の機能及び実装方法をこの記事では紹介していきたいと思います。
- PDF変換のニーズ: 文書の統一化、共有や配布時の互換性向上、情報漏洩防止等々
- 本記事の目的: Acrobat Services APIの基本及びPDF変換に関する機能紹介・実装方法
Acrobat Services APIとは?
Acrobat Services APIでは、ユーザ側にてAPIコールを行い、Adobeクラウド側で処理を実行します。ソースコードの内容に従って処理が自動的に実行されますので、手作業による変換処理の手間が省ける他、システムに組み込んで利用する事も出来ます。

-
特長
- 処理環境:Adobeのクラウド環境にて処理を実行
- 事前準備:必要なものは実行用スクリプトと対象ドキュメントのみ
- 処理品質:高速かつ信頼性の高い変換処理
- 対応形式:PDF、Word、Excel、PowerPoint、画像やテキスト等、様々な形式に対応
- 料金体系:1ヶ月に500回まで無償利用可能、それ以降は有償 (別途契約が必要)
PDF変換機能の紹介
Word・Excel・PowerPoint ⇒ PDF
一般的によく利用されるオフィス形式からPDFに変換するケースです。Acrobat Services APIはもちろん対応しています。参考例として、左が変換前のPowerPointのファイル、右がAPIにより変換を行った変換後のPDFファイルです。

PDF ⇒ Word・Excel・PowerPoint
PDFから逆にオフィス形式へと変換するケースです。こちらもAcrobat Services APIは対応しています。参考例として、左が変換前のPDFファイル、右がAPIにより変換を行った変換後のWordファイルです。

その他
今回の記事の対象ではありませんが、画像やテキストファイルにも対応しています。
-
他形式からPDFに変換
- Text ( rtf )
- Image ( jpeg, png )
- HTML ( html, htm )
-
PDFから他形式に変換
- Text ( txt, rtf )
- Image ( bmp, jpeg, gif, tiff, png )
実装編:PDF変換のソースコード作成
まずは、事前準備として実行環境の構築を行いましょう。と言いつつこちらの内容は別記事にて詳しく説明しておりますので、そちらをご参照下さい。なお、今回はPythonベースにて説明していきます。
-
環境構築 (事前準備)
- Acrobat DeveloperのWebサイトでのクレデンシャル作成
- SDKのインストール(pip install pdfservices-sdk)
- 認証情報を環境変数として宣言
<参考記事> Adobe Document Services APIを使ってみよう
- PDF Services APIのトライアル開始 ~ クレデンシャルの認証情報を環境変数として宣言
それでは、早速スクリプトの紹介をしていきたいと思います。以下は、実行スクリプトと同一のフォルダ内にあるドキュメントをPDFに変換するスクリプトのソースコードです。
<入力ファイル情報>
- 変換前入力ファイル:スクリプトと同じフォルダにあるドキュメントを参照
- 変換前ファイル名:*.docx/xlsx/pptx ⇒ ファイル名の指定無し (最初に見つかったファイル)
<出力ファイル情報>
- 変換後出力ファイル:スクリプトと同じフォルダに出力
- 変換後ファイル名:create_{time_stamp}.pdf ⇒ create_202505011834.pdf (例)
Word / Excel / PowerPoint ⇒ PDFに変換
import logging
import os
import glob
from datetime import datetime
from adobe.pdfservices.operation.auth.service_principal_credentials import ServicePrincipalCredentials
from adobe.pdfservices.operation.exception.exceptions import ServiceApiException, ServiceUsageException, SdkException
from adobe.pdfservices.operation.io.cloud_asset import CloudAsset
from adobe.pdfservices.operation.io.stream_asset import StreamAsset
from adobe.pdfservices.operation.pdf_services import PDFServices
from adobe.pdfservices.operation.pdf_services_media_type import PDFServicesMediaType
from adobe.pdfservices.operation.pdfjobs.jobs.create_pdf_job import CreatePDFJob
from adobe.pdfservices.operation.pdfjobs.result.create_pdf_result import CreatePDFResult
# Initialize the logger
logging.basicConfig(level=logging.INFO)
class CreatePDFFromOffice:
def __init__(self):
try:
# ドキュメントファイルを1つ探す(最初に見つかったもの)
office_files = glob.glob('*.docx') #Excelの場合はxlsx、PowerPointの場合はpptxに変更
if not office_files:
logging.error("DOCXファイルが見つかりません。") #Excelの場合はXLSX、PowerPointの場合はPPTXに変更
return
input_path = office_files[0] # 最初のファイルを使用
logging.info(f"変換対象ファイル: {input_path}")
with open(input_path, 'rb') as file:
input_stream = file.read()
# Initial setup, create credentials instance
credentials = ServicePrincipalCredentials(
client_id=os.getenv('PDF_SERVICES_CLIENT_ID'),
client_secret=os.getenv('PDF_SERVICES_CLIENT_SECRET')
)
# Creates a PDF Services instance
pdf_services = PDFServices(credentials=credentials)
# Creates an asset(s) from source file(s) and upload
input_asset = pdf_services.upload(input_stream=input_stream, mime_type=PDFServicesMediaType.DOCX)
#Excelの場合はXLSX、PowerPointの場合はPPTXに変更
# Creates a new job instance
create_pdf_job = CreatePDFJob(input_asset)
# Submit the job and gets the job result
location = pdf_services.submit(create_pdf_job)
pdf_services_response = pdf_services.get_job_result(location, CreatePDFResult)
# Get content from the resulting asset(s)
result_asset: CloudAsset = pdf_services_response.get_result().get_asset()
stream_asset: StreamAsset = pdf_services.get_content(result_asset)
# Creates an output stream and copy stream asset's content to it
output_file_path = self.create_output_file_path()
with open(output_file_path, "wb") as file:
file.write(stream_asset.get_input_stream())
except (ServiceApiException, ServiceUsageException, SdkException) as e:
logging.exception(f'Exception encountered while executing operation: {e}')
# Generates a string containing a directory structure and file name for the output file
@staticmethod
def create_output_file_path() -> str:
now = datetime.now()
time_stamp = now.strftime("%Y%m%d%H%M")
return f"create_{time_stamp}.pdf"
if __name__ == "__main__":
CreatePDFFromOffice()
次に逆の変換の場合のスクリプトを紹介します。以下は、スクリプトを実行したフォルダ内にあるPDFを各ドキュメントに変換するスクリプトのソースコードです。
<入力ファイル情報>
- 変換前入力ファイル:スクリプトを同じフォルダにあるPDFを参照
- 変換前ファイル名:*.pdf ⇒ ファイル名の指定無し (最初に見つかったファイル)
<出力ファイル情報>
- 変換後出力ファイル:スクリプトと同じフォルダに出力
- 変換後ファイル名:create_{time_stamp}.docx/xlsx/pptx ⇒ create_202505011834.docx (例)
PDF ⇒ Word / Excel / PowerPoint に変換
import logging
import os
import glob
from datetime import datetime
from adobe.pdfservices.operation.auth.service_principal_credentials import ServicePrincipalCredentials
from adobe.pdfservices.operation.exception.exceptions import ServiceApiException, ServiceUsageException, SdkException
from adobe.pdfservices.operation.io.cloud_asset import CloudAsset
from adobe.pdfservices.operation.io.stream_asset import StreamAsset
from adobe.pdfservices.operation.pdf_services import PDFServices
from adobe.pdfservices.operation.pdf_services_media_type import PDFServicesMediaType
from adobe.pdfservices.operation.pdfjobs.jobs.export_pdf_job import ExportPDFJob
from adobe.pdfservices.operation.pdfjobs.params.export_pdf.export_pdf_params import ExportPDFParams
from adobe.pdfservices.operation.pdfjobs.params.export_pdf.export_pdf_target_format import ExportPDFTargetFormat
from adobe.pdfservices.operation.pdfjobs.result.export_pdf_result import ExportPDFResult
# Initialize the logger
logging.basicConfig(level=logging.INFO)
class ExportPDFToDOCUMENT:
def __init__(self):
try:
# PDFファイルを1つ探す(最初に見つかったもの)
office_files = glob.glob('*.pdf')
if not office_files:
logging.error("PDFファイルが見つかりません。")
return
input_path = office_files[0] # 最初のファイルを使用
logging.info(f"変換対象ファイル: {input_path}")
with open(input_path, 'rb') as file:
input_stream = file.read()
# Initial setup, create credentials instance
credentials = ServicePrincipalCredentials(
client_id=os.getenv("PDF_SERVICES_CLIENT_ID"),
client_secret=os.getenv("PDF_SERVICES_CLIENT_SECRET"),
)
# Creates a PDF Services instance
pdf_services = PDFServices(credentials=credentials)
# Creates an asset(s) from source file(s) and upload
input_asset = pdf_services.upload(input_stream=input_stream, mime_type=PDFServicesMediaType.PDF)
# Create parameters for the job
export_pdf_params = ExportPDFParams(target_format=ExportPDFTargetFormat.DOCX)
#Excelの場合はXLSX、PowerPointの場合はPPTXに変更
# Creates a new job instance
export_pdf_job = ExportPDFJob(input_asset=input_asset, export_pdf_params=export_pdf_params)
# Submit the job and gets the job result
location = pdf_services.submit(export_pdf_job)
pdf_services_response = pdf_services.get_job_result(location, ExportPDFResult)
# Get content from the resulting asset(s)
result_asset: CloudAsset = pdf_services_response.get_result().get_asset()
stream_asset: StreamAsset = pdf_services.get_content(result_asset)
# Creates an output stream and copy stream asset's content to it
output_file_path = self.create_output_file_path()
with open(output_file_path, "wb") as file:
file.write(stream_asset.get_input_stream())
except (ServiceApiException, ServiceUsageException, SdkException) as e:
logging.exception(f"Exception encountered while executing operation: {e}")
# Generates a string containing a directory structure and file name for the output file
@staticmethod
def create_output_file_path() -> str:
now = datetime.now()
time_stamp = now.strftime("%Y%m%d%H%M")
return f"create_{time_stamp}.docx" #Excelの場合はxlsx、PowerPointの場合はpptxに変更
if __name__ == "__main__":
ExportPDFToDOCUMENT()
よくあるエラーとトラブルシューティング
-
SDKがインストールされていない、SDKのバージョンが古い
⇒ SDKが古いと一部の機能が実装されておらず、importに失敗する事があります
⇒ v4.1.0(Python)が最新版です ※2025年5月現在
-
クレデンシャルの指定を間違えている
⇒ PDF_SERVICES_CLIENT_ID = クライアントIDの変数名
⇒ PDF_SERVICES_CLIENT_SECRET = クライアントシークレットの変数名
⇒ 上手く行かない場合、ソースコードに値を直接入力してみて下さい
※セキュリティ運用上は、ソースコードに認証情報を埋め込む事は推奨されません
-
MediaTypeの指定を間違えている (Word/Excel/PowerPoint ⇒ PDF)
⇒ input_assetの行で、入力元となるファイルの拡張子を指定する必要があります
-
ExportPDFTargetFormatの指定を間違えている (PDF ⇒ Word/Excel/PowerPoint)
⇒ export_pdf_paramsの行で、出力先となるファイルの拡張子を指定する必要があります
高度な活用事例
Microsoft Power Automateと連携した自動変換ワークフロー
Microsoft Power Automateを利用している方は、Adobeがサードパーティ製品として提供しているAdobe PDF Servicesを連携させて活用する事が出来ます。
利用開始方法
接続 ⇒ 新しい接続から「Adobe」で検索すると、Adobe PDF サービスが表示されるので、これを選択してクレデンシャル情報を入力すると利用を開始する事が出来ます。
- 認証タイプ:Oauth サーバー間の資格情報
- クライアント ID:Adobe Services APIのクライアントID
- クライアント シークレット:Adobe Services APIのクライアントシークレット

以下は、Power Automate上で用意されているテンプレート各種です。今回テーマとしてあげているPDF変換以外にも様々なテンプレートが提供されています。今回は細かくは触れませんが、Microsoft製品であるOutlookやSharePointとの連携を始め、数多く提供されているサードパーティ製品とも組み合わせてワークフローを作成出来るので、興味があれば触ってみて下さい。
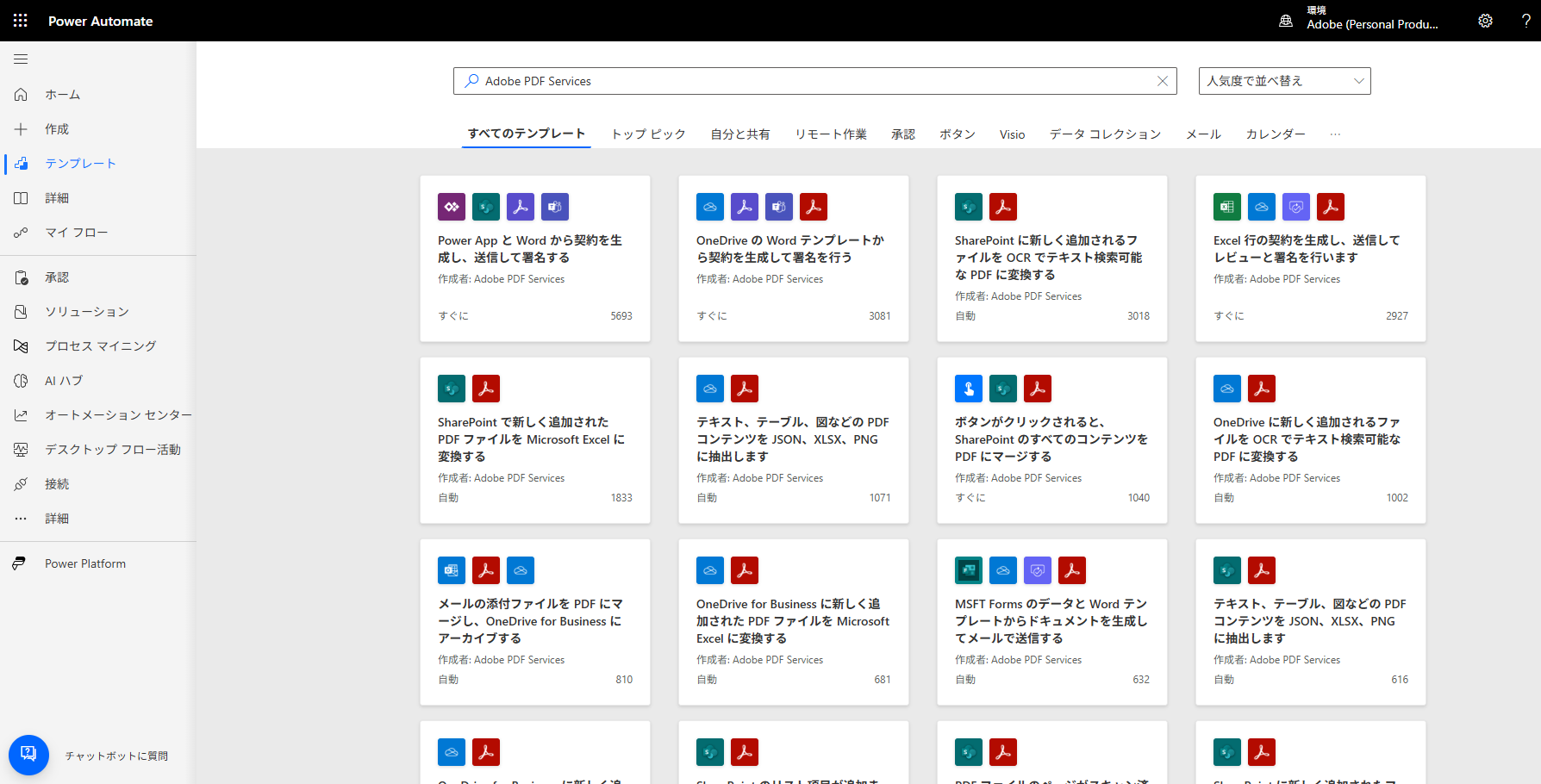
Watchdogによるフォルダ監視による自動検知及び自動変換
主にPythonの話になってしまうので詳細はここでは触れませんが、Watchdogというモジュールを利用する事で、指定したフォルダ内にファイルが追加されるとそれを自動的に検知し、スクリプトをキックするという処理が可能です。サンプルのソースコードを作成しておりますので、対象のドキュメントの拡張子、キックするスクリプト名、監視フォルダを指定の上で試してみて下さい。なお、WatchdogはPythonの標準モジュールに含まれておりませんので、利用する場合はpip install watchdogでインストールしてから実行して下さい。
指定フォルダにdocxが置かれたら、PDF変換スクリプトを自動実行
import time
import os
import threading
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class WatcherHandler(FileSystemEventHandler):
def __init__(self):
super().__init__()
self.processed_files = set()
self.lock = threading.Lock()
def on_created(self, event):
if not event.is_directory and event.src_path.endswith(".docx"): #監視する拡張子を指定
# ロックを使って多重処理防止
with self.lock:
if event.src_path in self.processed_files:
return # すでに処理済み
self.processed_files.add(event.src_path)
print(f"📄 新しいファイル検出: {event.src_path}")
script_path = os.path.join(os.path.dirname(__file__), "create_pdf_from_docx.py")
#自動実行するスクリプトを指定
threading.Thread(target=run_script, args=(script_path, event.src_path)).start()
def run_script(script_path, file_path):
cmd = f'python "{script_path}" "{file_path}"'
print(f"🚀 実行中: {cmd}")
os.system(cmd)
print(f"✅ 処理完了: {file_path}")
if __name__ == "__main__":
WATCH_FOLDER = "PDF変換フォルダ" #監視するフォルダを指定
os.makedirs(WATCH_FOLDER, exist_ok=True)
event_handler = WatcherHandler()
observer = Observer()
observer.schedule(event_handler, WATCH_FOLDER, recursive=False)
observer.start()
print(f"👀 フォルダ「{WATCH_FOLDER}」を監視中。新しい .docx ファイルが追加されると処理されます。")
try:
while observer.is_alive():
time.sleep(1)
except KeyboardInterrupt:
print("🛑 停止します...")
observer.stop()
observer.join()
最後に
今回は、PDF変換のAPIに関して紹介しました。個人で利用する事もシステムに組み込んで利用する事も出来ますので、皆さんの豊富なアイディアで上手に活用して頂けたらと思います。また、Acrobat Services API Use Casesのページや、Adobe Document Cloud 公式YouTubeにも活用のヒントがありますので、よろしければこちらもご参照下さい。
もし本格的に導入を検討したい方がおられましたら、以下のページからご相談頂く事が可能なので、是非ともお気軽にお問合せ下さい。