「智に働けば角が立つ。情に棹させば流される。意地を通せば窮屈だ。兎角に人の世は住みにくい。」何事もほどほど中くらいがいいということか?
SPI(Serial Peripheral Interfac) は高速とはよべないだろう。Wikipedia では比較的低速と表現されている。確かにマイコンの世界ではピンの外にクロックを出して、IC(ペリフェラル) と接続するという事が多いかもしれない。場合によっては、手はんだやブレッドボードを経由するのでそれほど速いスピードというわけにはいかないだろう。しかし、FPGA 内部で SPI を使えば 200MHz といった比較的早いスピードのクロックも考えることが出来る。ここでは SPI を中速ととらえておく。

SPI の I/F をもつペリフェラルの例
SPI の実際の動きについては巻末(じゃなくて下の方)の絵や他の文献に譲るとして、ソフトウェアの立場から SPI を考えてみる。SPI のクロックの SCLK は本当の規則正しいクロックでなくてもよい。ペリフェラルの中には最低クロックを取り決めしているものもあるが、大抵の場合 CPU から GPIO でつないで MISO や MOSI 等のデータ線と合わせて超低速でアクセスすることもできる。ソフトウェア的立場から理解したい人は、Polyphony で HDL を組む前に GPIO で直接プログラミングしてアクセスすることをお勧めする。
クロックの細かい制御が苦手な Polyphony でも、ソフトウェア的な要領でSPI をアクセスすることが出来る。そして、生成されるコードは Verilog-HDL なので意外と高速だ(中速だ)。
ソースを示そう。
import polyphony
from polyphony.io import Port
from polyphony.typing import bit, uint3, uint12, uint16
from polyphony.timing import clksleep, clkfence, wait_rising, wait_falling
CONVST_PULSE_CYCLE = 10
CONVERSION_CYCLE = 40
@polyphony.module
class AD7091R_SPIC:
def __init__(self):
self.sclk = Port(bit, 'out')
self.sdo = Port(bit, 'in')
self.sdi = Port(bit, 'out')
self.convst_n = Port(bit, 'out', init=1)
self.cs_n = Port(bit, 'out', init=1)
self.dout = Port(uint12, 'out')
self.chout = Port(uint3, 'out')
self.din = Port(uint16, 'in')
self.data_ready = Port(bit, 'out')
self.append_worker(self.main)
def main(self):
while polyphony.is_worker_running():
self.convst_n.wr(1)
self.cs_n.wr(1)
self.data_ready.wr(0)
clkfence()
self.convst_n.wr(0)
clksleep(10)
self.convst_n.wr(1)
clksleep(40)
# starting ADC I/O
self.cs_n.wr(0)
sdo_tmp = 0
clksleep(1)
for i in range(16):
self.sclk.wr(0)
clkfence()
sdi_tmp = 1 if (self.din() & (1 << (15 - i))) else 0
self.sdi.wr(sdi_tmp)
clksleep(1)
self.sclk.wr(1)
clkfence()
sdo_d = self.sdo.rd()
sdo_tmp = sdo_tmp << 1 | sdo_d
#print('sdo read!', i, sdo_d)
self.sclk.wr(0)
self.dout.wr(sdo_tmp & 0x0fff)
self.chout.wr((sdo_tmp & 0x7000) >> 12)
self.cs_n.wr(1)
clkfence()
self.data_ready.wr(1)
@polyphony.testbench
@polyphony.rule(scheduling='parallel')
def test(spic):
datas = (0xdead, 0xbeef, 0xffff, 0x0000, 0x800)
for data in datas:
#print('!!', data)
wait_falling(spic.convst_n)
#print('convst_n fall', spic.convst_n())
wait_rising(spic.convst_n)
#print('convst_n rise', spic.convst_n())
wait_falling(spic.cs_n)
#print('cs_n fall', spic.cs_n())
spic.din.wr(0b1111000011110000)
for i in range(16):
databit = 1 if data & (1 << (15 - i)) else 0
#print('sdo write from test', i, databit)
spic.sdo.wr(databit)
wait_rising(spic.sclk)
wait_rising(spic.cs_n)
wait_rising(spic.data_ready)
clksleep(1)
#print(spic.dout())
assert spic.dout() == data & 0x0fff
assert spic.chout() == (data & 0x7000) >> 12
if __name__ == '__main__':
spic = AD7091R_SPIC()
test(spic)
wait_falling や wait_rising やあるいはこのソースにはないが wait_valueなどの関数を使って、クロックの変化をとらえることが出来る。シビアなクロック制御で無ければ Polyphony でも十分に IO 制御は出来る。なお、プログラムの中にある @polyphony.rule は Version 0.3.2 ではサポートされておらず無視されるだけである。
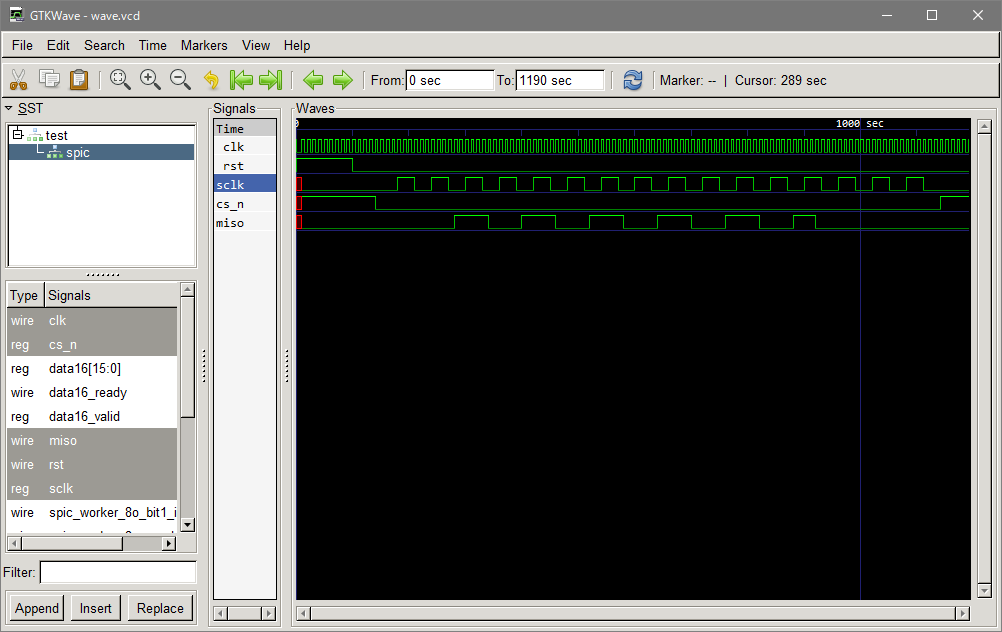
SPI の波形例
SPI のペリフェラルをアクセスするのは結構骨の折れる仕事だ。そのチップの(ペリフェラルの)仕様書を読んで、ちゃんとおもったように波形が出ているか確認しないといけない。
ここではおまけとして Polyphony でデバッグした時の波形を張り付けておく。
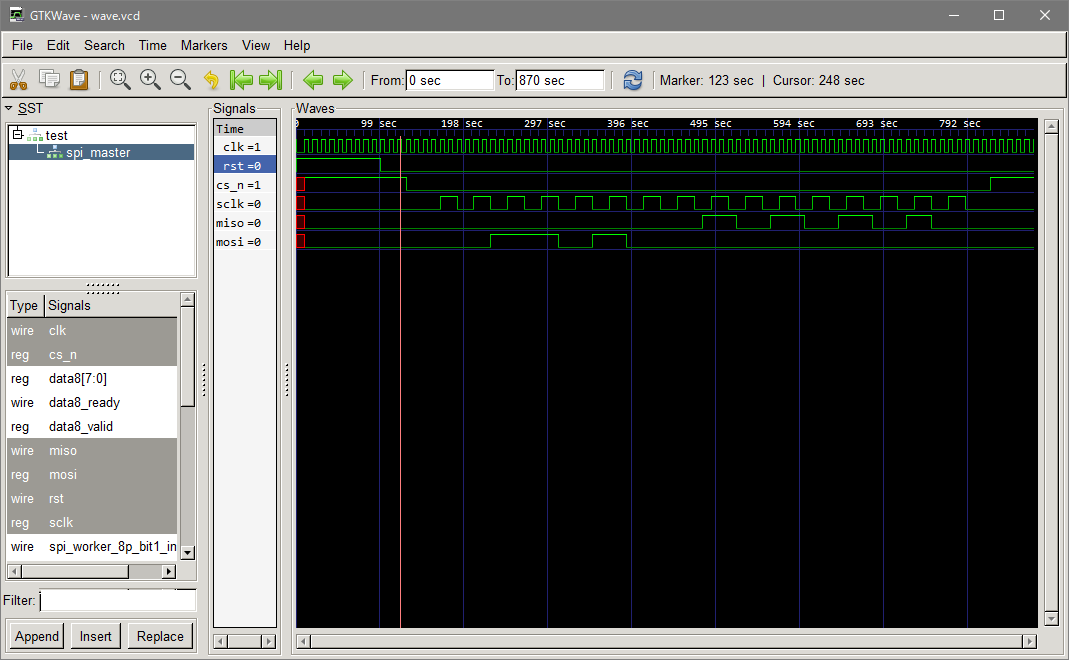
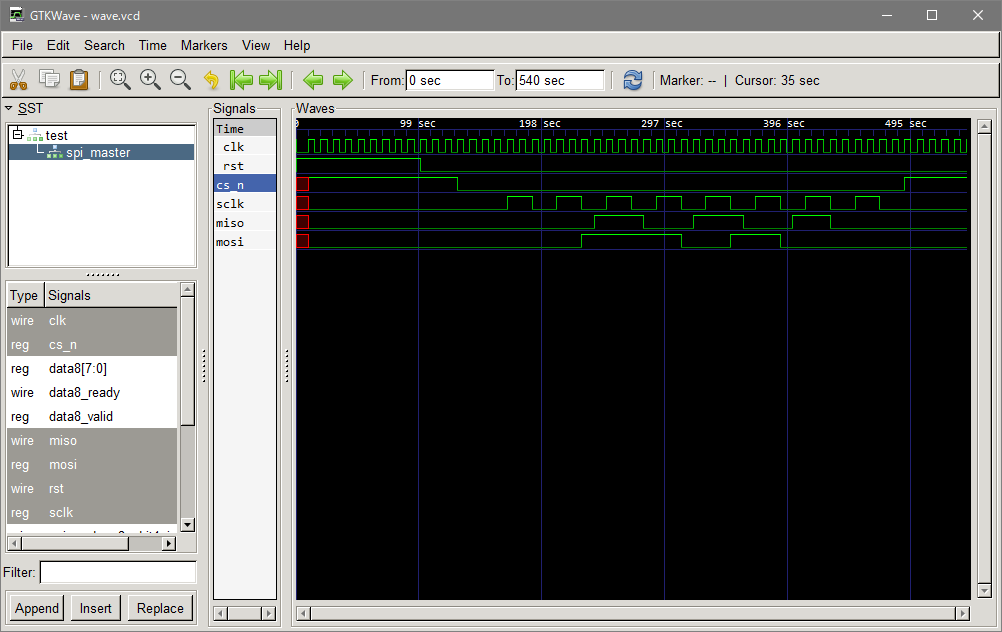
SPI の書き込み/読み込みはマスター側が CS をアサート(通常負論理なのでGNDに落とす) し、その間に SCLK をクロックとして供給しその立ち上がりで行う。Read/Write を表す信号線は無いため、常に書き込みと読み込みが同時に行わる。
コマンドを受け取って、レスポンスを返すタイプのものは、Master が書き込みを行い、続けて読み込むことになるだろう。書き込みと読み込みが必ず同時に行われるため、書き込み時には意味のない読み込みデータが読み込み時には意味のない書き込みデータが流れる。
チップによっては読み込みだけのもの書き込み/読み込みが同時で意味のあるものと、それぞれ規定されるチップの仕様によって千差万別である。
「SPI 書き込み、読み込み」「SPI 読み込みのみ」「SPI 同時に書き込み/読み込み」の例を掲げておく。何かの参考になれば。