はじめに
Microsoft Fabric でデータを収集するためにどの機能をどのように使えばいいか解説します。
取り込み方式について
データの収集には Pull 方式か Push 方式があると考えられます。
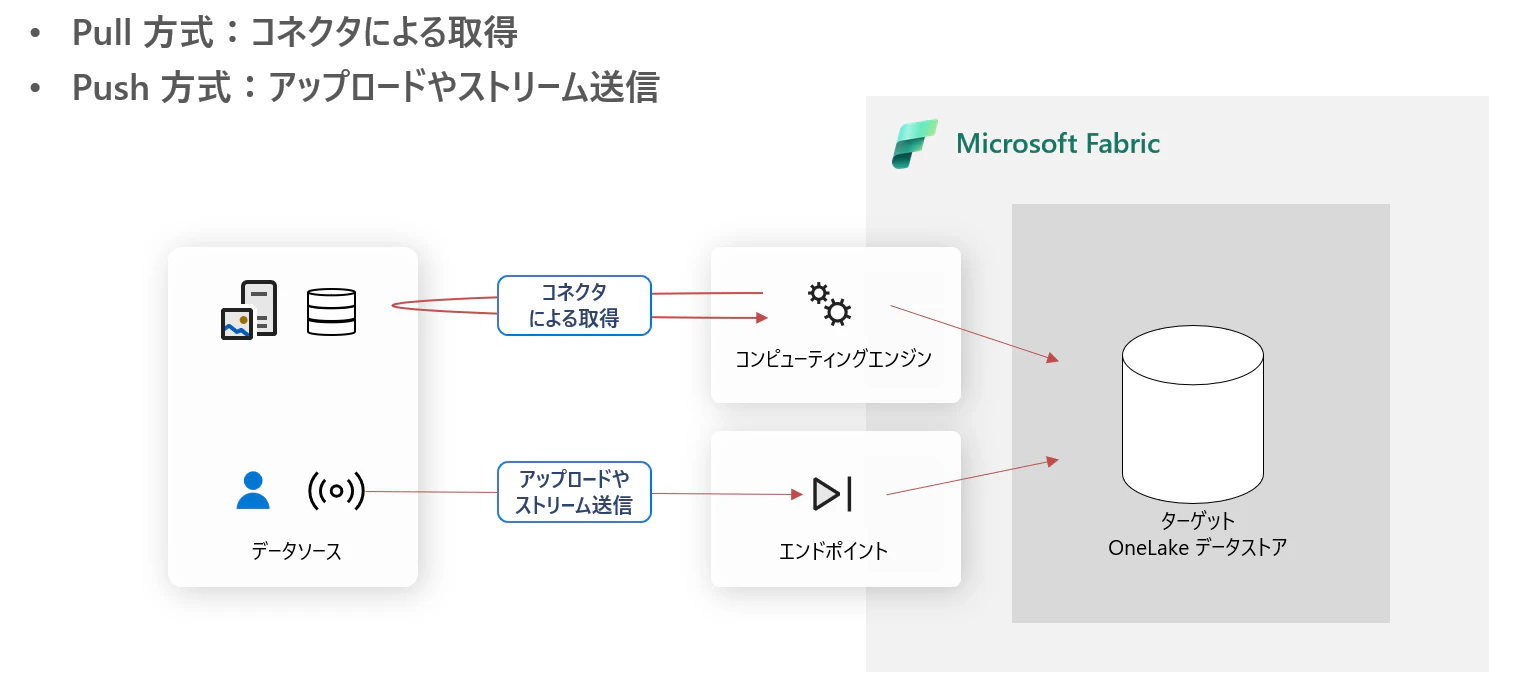
- Pull 方式: Fabric の収集機能が主体となり、データソースにデータを取りに行きます
- Push 方式: データソースのアップロード機能が主体となり、ターゲットとなるエンドポイントにデータを送信します。
本記事では Pull 方式について解説します。
データソースシステムへの接続について
通常、Fabric のようなクラウドサービスはインターネットのパブリックな空間上のデータには接続できても、社内システムなどが存在するプライベートネットワーク上に存在するデータソースには接続ができません。
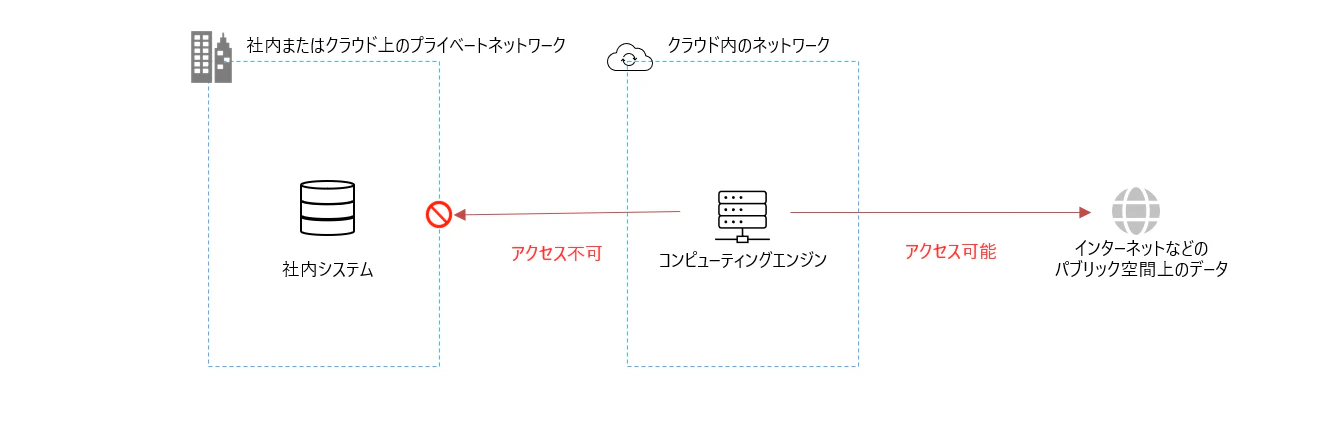
Microsoft の分析ソリューションでは、こうしたデータソースへの接続に関するセットアップが大きく3つの方式に分類されます。
データソースの種類に応じてこれらを選択することでプライベートネットワーク上のデータであっても、収集・分析を実現します。
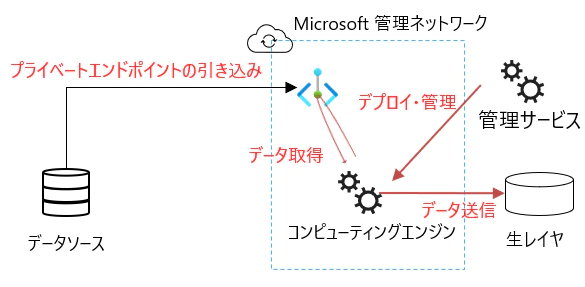
フルマネージド
Microsoft 管理するネットワーク上にコンピューティングエンジン(データにアクセスし、ターゲットに送信するエンジン)がセットアップされるパターンです。
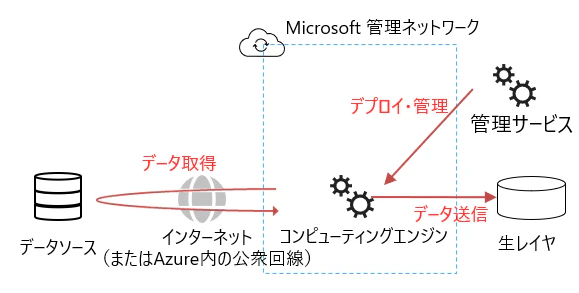
特徴は以下の通りです。
- セットアップが不要なサーバーレス環境
- インターネット上のデータにアクセスするのに適している
- Azure PaaS のデータストアに限り、このネットワークにプライベートエンドポイントを引き込むことで、接続可能(マネージドプライベートエンドポイント)
以下のようなサービスが該当します。
前述のマネージドプライベートエンドポイントと呼ばれる仕組みを使用すると Microsoft 管理テナント内にマネージド仮想ネットワークと呼ばれる仮想ネットワークが構成され、データソースとリンクされたプライベートエンドポイントを引き込むことでサーバーレス環境でありながらプライベート通信が可能です。
セルフホスティング
ご自身が所有するマシン内にランタイムをインストールすることで、データ収集用のコンピューティングエンジンとしての機能をセットアップする方式です。

特徴は以下の通りです。
- 社内ネットワーク上のサーバーや、ラップトップなどで構成可能
- Fabric / Azure Data Factory / Purview のセルフホステッド統合ランタイムでは Windows OSが要件
- 社内ネットワークのデータにアクセスするのに適している
- サーバー自体の管理運用や、高可用構成(必要な場合)をする必要がある
以下のようなサービスが該当します。
カスタマーネットワーク埋め込み
組織が所有する、Azure 上のネットワークの一部を管理サービスに委任し、Microsoft がそのネットワーク上にコンピューティングエンジンをデプロイ、ホストする方式です。
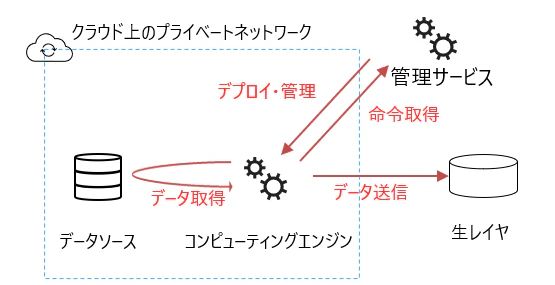
特徴は以下の通りです。
- Azure 仮想ネットワークでのみ構成可能
- 仮想ネットワーク内のデータにアクセスするのに適している
- デプロイされるコンピューティングエンジンの OSレベルの構成は原則不可(プロキシ設定、ドメイン参加など)
以下のようなサービスが該当します。
Fabric におけるデータ収集機能
Fabric では、 Pull 型のデータ収集を行うにあたり、以下の機能が存在します。
- データパイプラインのコピーアクティビティ/データフロー Gen2
- ショートカット
- ミラーリング
- Spark
- T-SQL のコピーコマンド
それぞれの機能について、データソースの場所によってどのような構成をすべきかを整理します。
データパイプラインのコピーアクティビティ/データフロー Gen2
コピーアクティビティはデータの移動・取り込みを実施し、データフロー Gen2 は移動・変換・取り込みを実施します。
前者では、ファイル内容を読み取らずにコピーする バイナリコピー が可能であることに対して、後者では、必ずデータを読み取って、テーブル形式に変換します。
注意点としては、コネクタの種類の違いです。Dataflow のほうがやや多い状況です。
公開データの場合
特別な構成は不要です。クラウド接続 と呼ばれるフルマネージドの仕組みにデータソースへの接続文字列、認証情報を保持して、データソースにアクセスします。
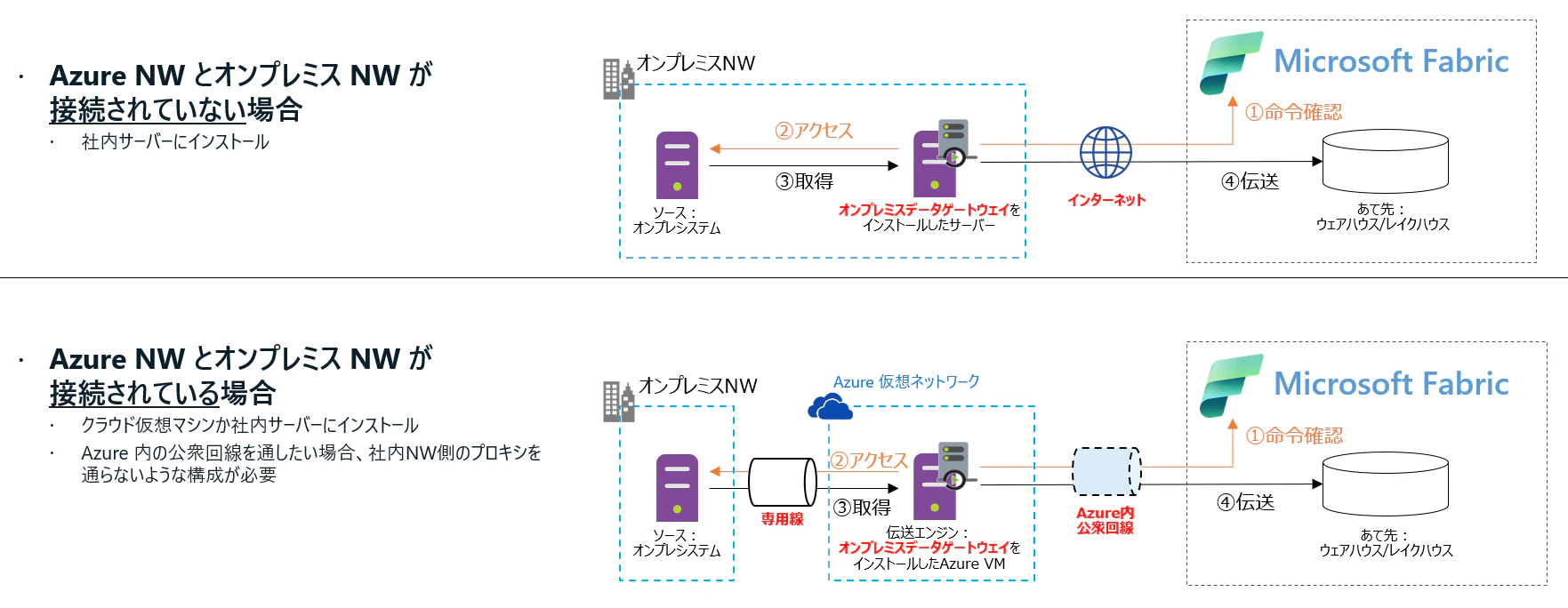
閉域データの場合
セルフホスティング方式 となる、Power BI / Fabric のオンプレミスデータゲートウェイ、または、カスタマーネットワーク埋め込み 方式となる、Fabric の仮想ネットワークデータゲートウェイを使用して接続が可能です。
データパイプラインは現在のところ仮想ネットワークデータゲートウェイがサポートされていないようです。(実際は動作し、どこかでサポートの案内を見た気がするので、間違ってたら教えてください。)
補足1)オンプレミスデータゲートウェイの通信調整について
よく、Fabric とオンプレミスデータゲートウェイが連動するにあたって、インターネットに受信ポートを開放しないといけないのではというお問い合わせがありますが、回答は No で、Fabric の命令を確認するにあたってゲートウェイ自身が取りに行くような送信方向のアクセスになるため、Fabric に対してアクセスできるネットワーク構成であれば、受信ポートは開放する必要はありません。
Power BI から Fabric となり、ゲートウェイの通信要件で Dataflow Gen 2 を使うための 1433 (SQL Server) ポートの送信許可が必要になったので既存のゲートウェイをそのまま使う際には注意ください
ただし、ゲートウェイがFabric にデータを送信するにあたり、構成によっては、インターネットを経由してしまう場合がある点には注意が必要です。
補足2)仮想ネットワークデータゲートウェイの構成について
こちらの方式では仮想ネットワークデータゲートウェイを Microsoft Fabric に貸す方式となるので、サブネットの委任が必要となります
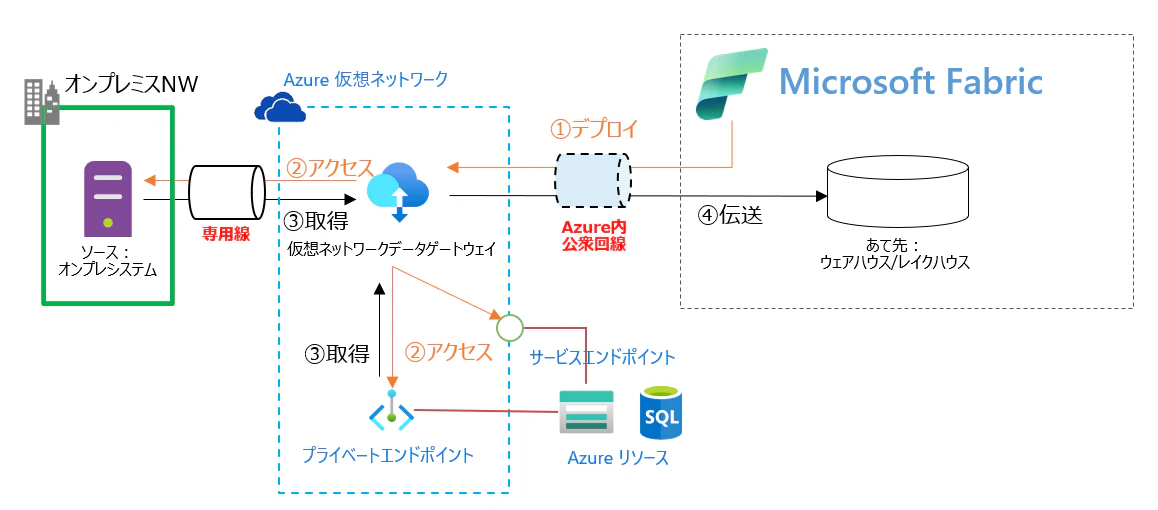
閉域の Azure Storage の場合
プライベートエンドポイントのみの設定では不可ですが、選択されたネットワークからのアクセスが許可(パブリックエンドポイントが使える)の状況下では、信頼されたワークスペース アクセス が利用可能です。
この方式では、データゲートウェイのセットアップは不要で、フルマネージドの構成方式で接続が可能です。

ショートカット
マルチクラウドのオブジェクトストレージを Fabric OneLake の一部としてリンクすることが出来る機能です。

参考:https://learn.microsoft.com/ja-jp/fabric/onelake/onelake-shortcuts
公開データの場合
特別な構成は不要です。クラウド接続 と呼ばれるフルマネージドの仕組みにデータソースへの接続文字列、認証情報を保持して、データソースにアクセスします。
閉域データの場合(S3, GCS)
VPC 上の S3 、GCS が相手の場合、オンプレミスデータゲートウェイを使用して、セルフホスティングの方式で接続可能です。
閉域の Azure Data Lake Storage の場合
パイプラインと同様、信頼されたワークスペース アクセス が利用可能です。
ミラーリング
ソースシステムのデータベースをニアリアルタイムで Fabric 上の ミラーリングデータベースに レプリケーション する仕組みです。
参考:https://learn.microsoft.com/ja-jp/fabric/database/mirrored-database/overview
こちらは現在のところ、フルマネージド方式 のみが利用可能で、プライベートな空間のデータについてはオンプレミスデータゲートウェイなどを使用した接続が利用可能です。(一部を除く)
Spark
Fabric Runtime では Spark が動作するため、Spark のネイティブコネクタが利用可能です。
参考:https://spark.apache.org/docs/latest/sql-data-sources.html
公開データの場合
データパイプラインのようにクラウド接続を通してではなく、Spark のスクリプト内で接続文字列を構成します。
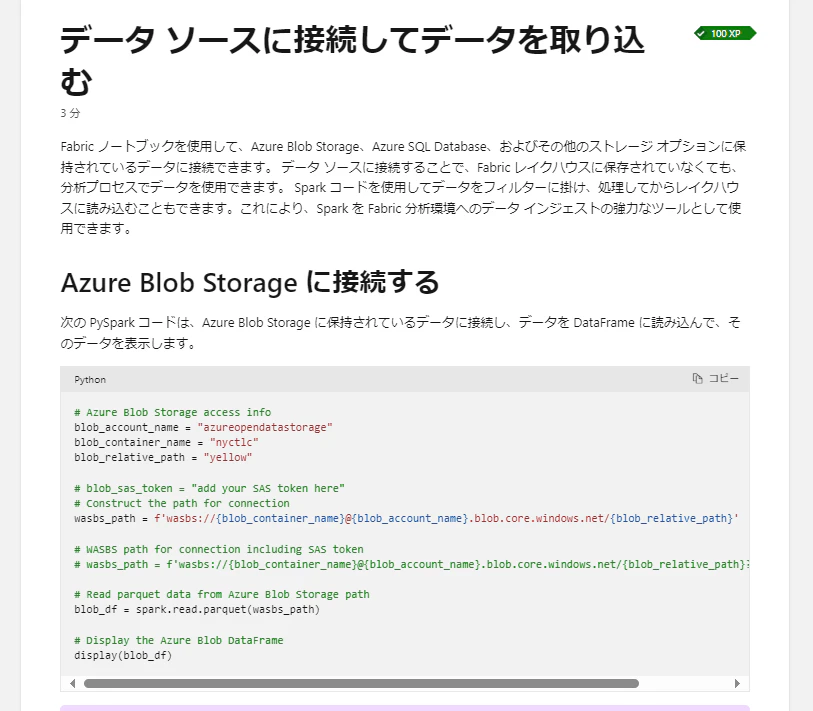
引用:https://learn.microsoft.com/ja-jp/training/modules/use-apache-spark-work-files-lakehouse/3b-connect
閉域データの場合
Azure PaaS が相手先であれば、マネージド仮想ネットワークを通じて、Spark コネクタによるプライベート接続を構成可能です。

T-SQL のコピーコマンド
ウェアハウスの COPY コマンドを使用することで、 Azure Storage のデータを取得することが可能です。
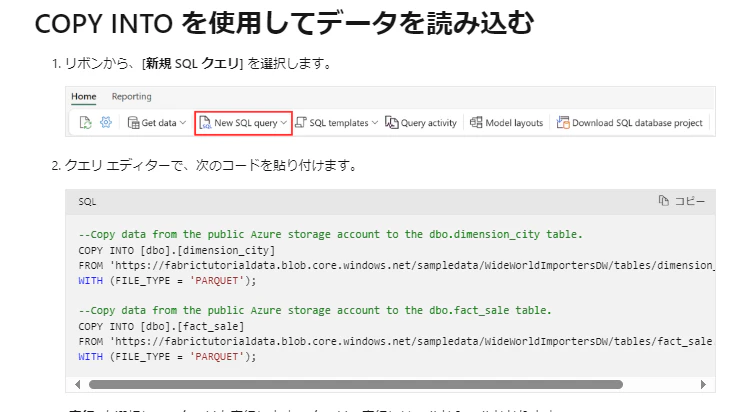
引用;https://learn.microsoft.com/ja-jp/fabric/data-warehouse/tutorial-load-data
閉域の Azure Data Lake Storage の場合
パイプラインと同様、信頼されたワークスペース アクセス が利用可能です。
まとめ
クラウドからオンプレミスまで様々なデータを様々な機能で取得できる Fabric ですが、広い選択肢それぞれの特性を把握して、効率よくデータ収集を構成することで、快適にデータを活用できるかと思います。
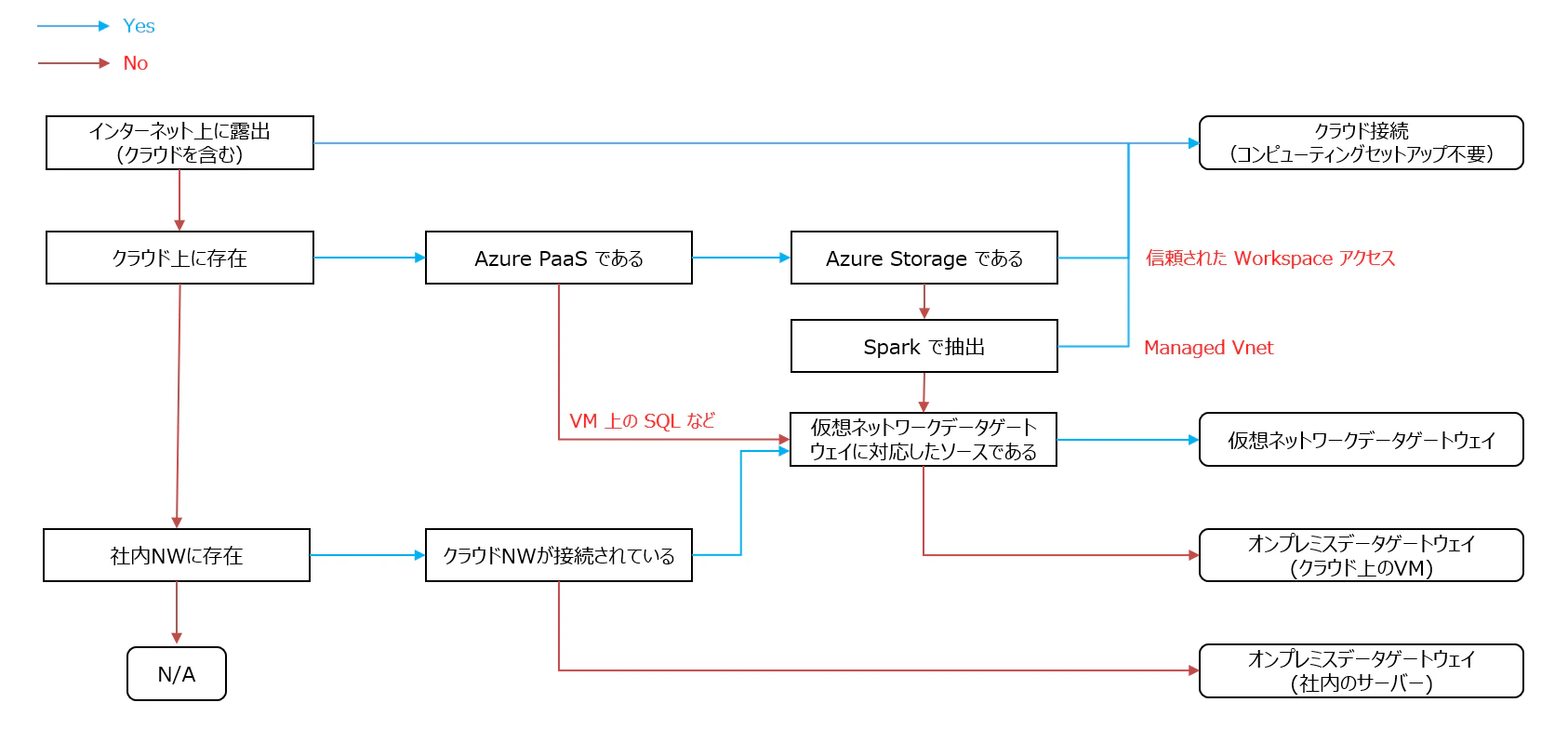
最後に今回の内容からデータ収集の構成についてチートシート化しましたので、ご活用ください。