はじめに
ファイルをバイナリコピーした際にコピーを実施した日時での更新日付になってしまうため、この情報を取り込む方法を記載します。
手順
やりたいことのイメージ

これら二つの課題を対策して、ファイル最終変更日時をテーブルに取り込みます。
本記事ではそれぞれの課題ごとにパイプラインを作っています。
準備
対象ファイルの状態
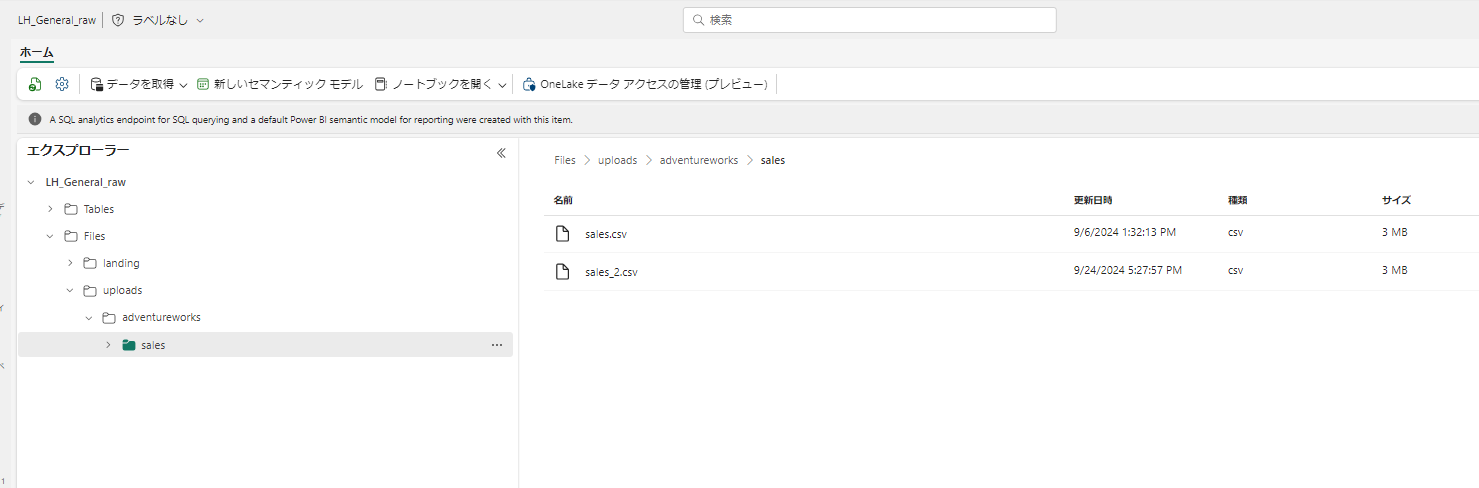
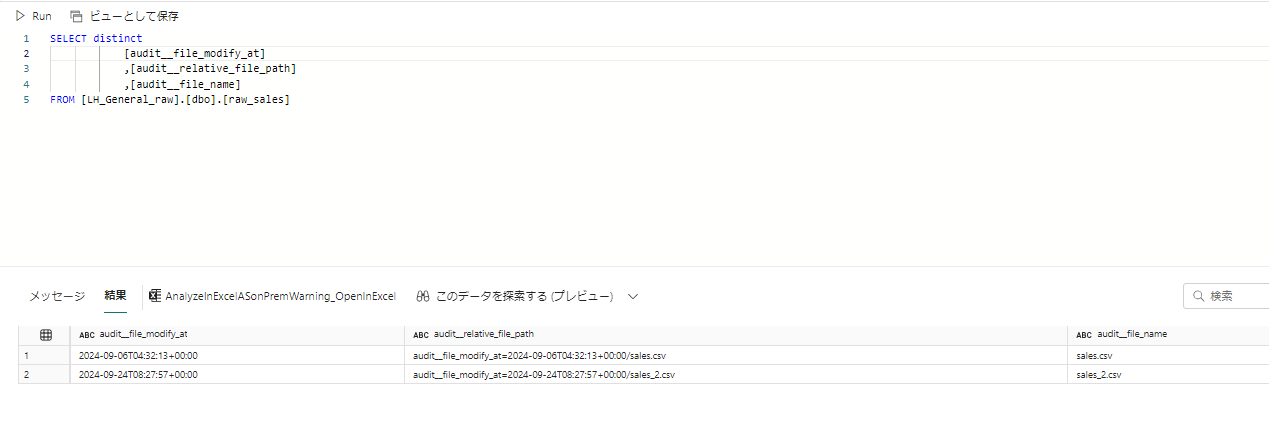
9/6 午後 1 時と、9/24 午後 5 時 27 分 の2ファイルがアップされています。
1. Hive パーティション形式で変更日時を表現して保存するパイプライン
課題①となる最終変更日時をファルダ構造に持たせることで Landing で最終変更日時を保持します。
パイプラインの全体像

Get files
パラメータ化しているコピーのソースディレクトリ (source_dir) のファイル一覧を取得します
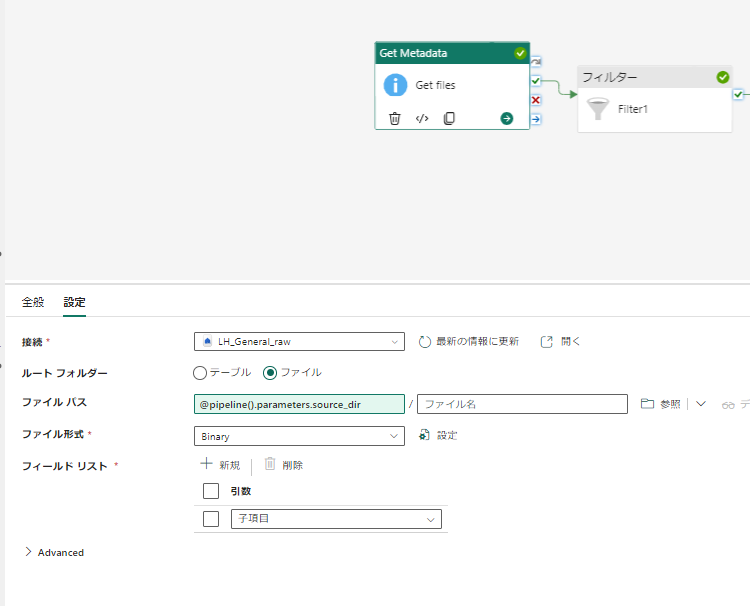
出力例は以下のようにファイルの配列です。

Filter
Get files では子フォルダまで取れる(存在している場合)のでファイルだけに絞り込みます。

出力例は以下のように絞られた配列です。

ForEach
対象ディレクトリ内のファイルごとに処理を実行します
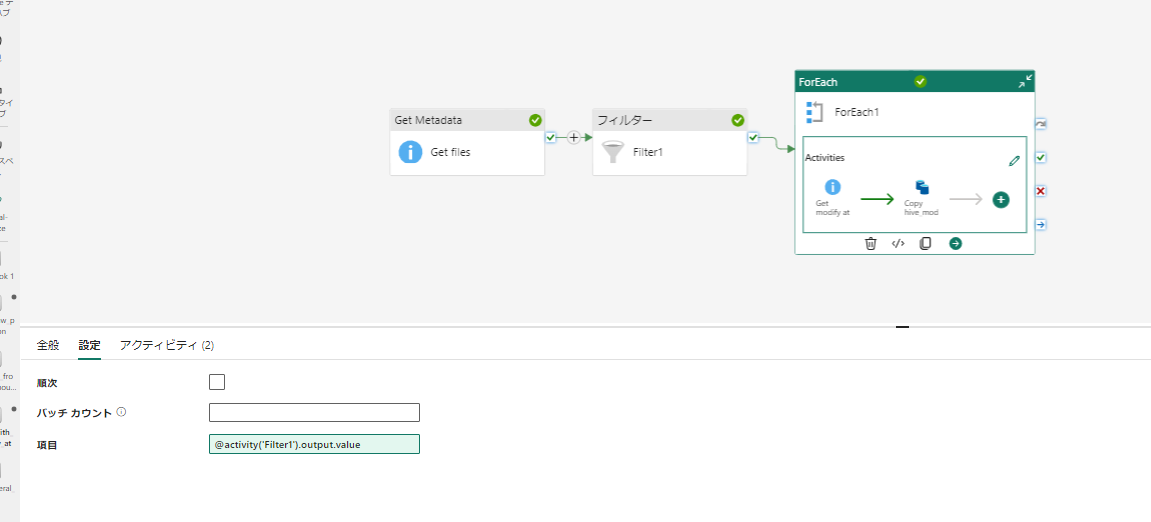
Get modify at
対象となったファイルの最終変更日時を取得します。
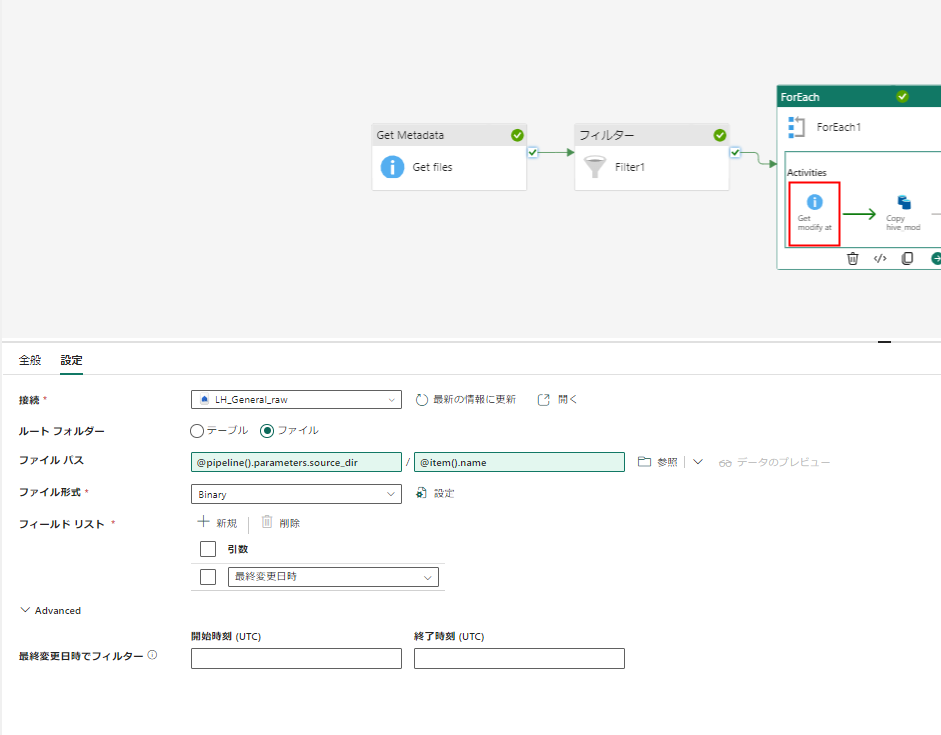
出力例は以下のように変更日時です。
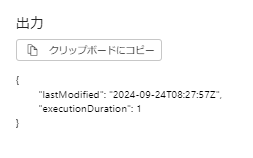
Copy hive mod
対象ファイルを 出力先パラメータ(target_dir) の配下に、hive パーティションで変更日時を表現したフォルダ構造でコピーします。

出力先の式
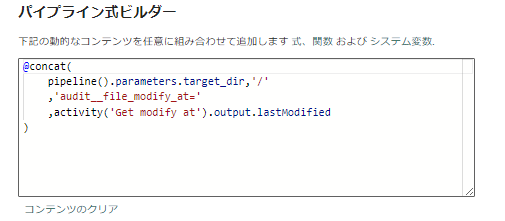
@concat(
pipeline().parameters.target_dir,'/'
,'audit__file_modify_at='
,activity('Get modify at').output.lastModified
)
実行確認
出力先パラメータ(target_dir) を、 landing/transactional/general_sample/sales/1.0/full/hive/audit__run_date=2024-09-24/audit__run_at_id=2024092423020936 という形で、ジョブの実行日付と実行日時は指定された状態で実行します。
実行結果は以下のようになり、<列名=値> の hive パーティション構造で出力されています。
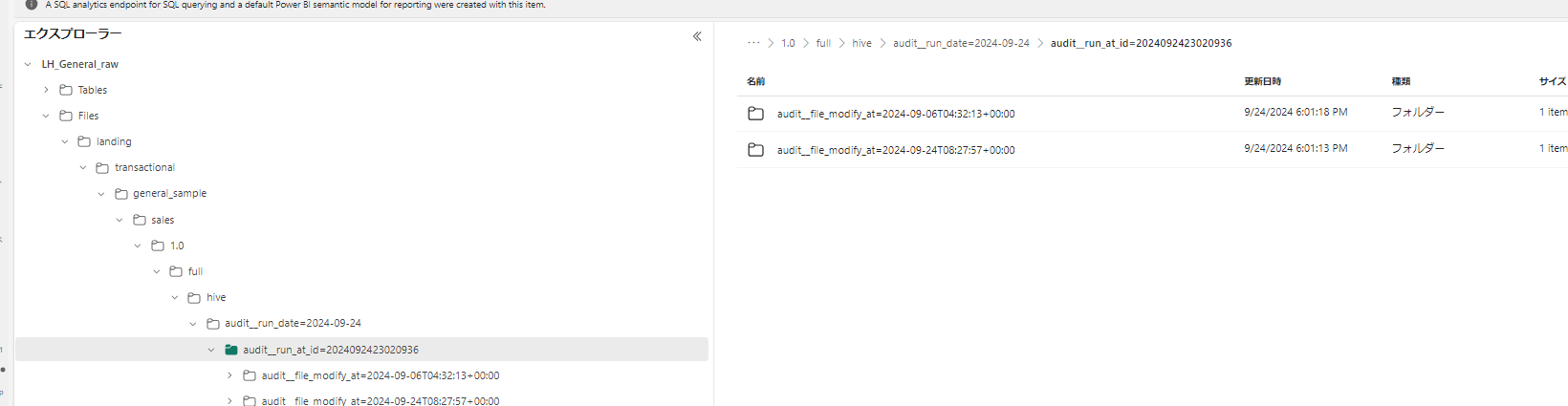


audit__run_at_id , audit__run_date はパラメータで指定されており、このパイプラインで生成した文字列ではありません。
ジョブの実行日時が入力されることを想定した列です。
2. Hive パーティションを検知して取り込むパイプライン
次は非常に簡単です。Hive パーティション形式でファイルが保存されているのでパーティション(フォルダ)の値を取り込み対象にすることができます。
ソース設定
lakehouse の ファイルをソースにして、ファイルパスを指定します。先ほどコピー先となったaudit__run_at_id=~のフォルダは以下のようになっているのでこれをソースにします。
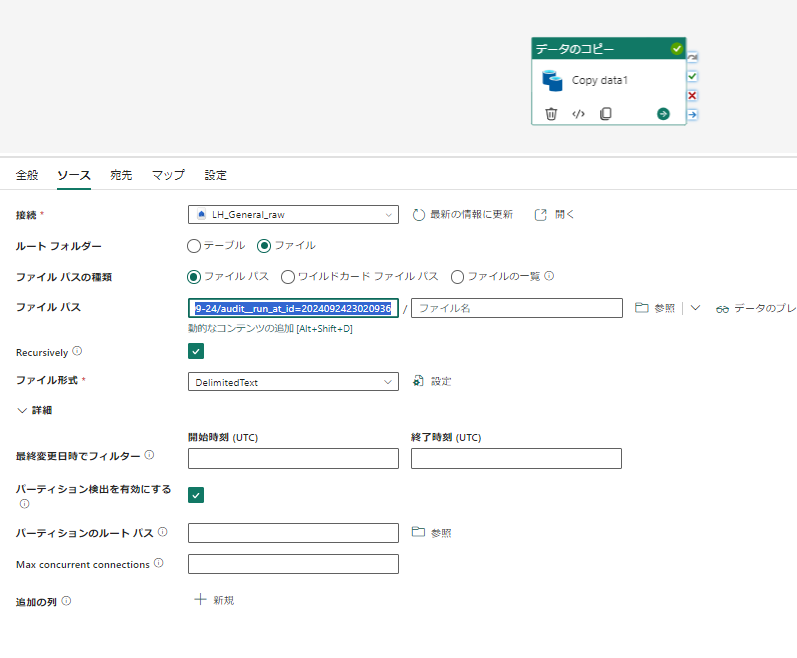

運用時にはこのパスはパラメータ化してすると汎用化されます
次にパーティション検出を有効にします。
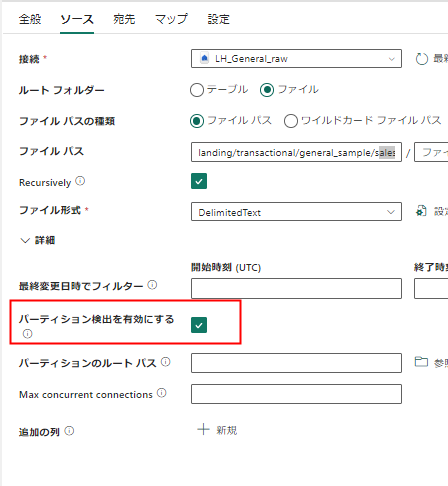
これにより、列名=値のフォルダ構造を利用した情報がレコードに付加されます。
プレビューを確認すると期待通りになっています。
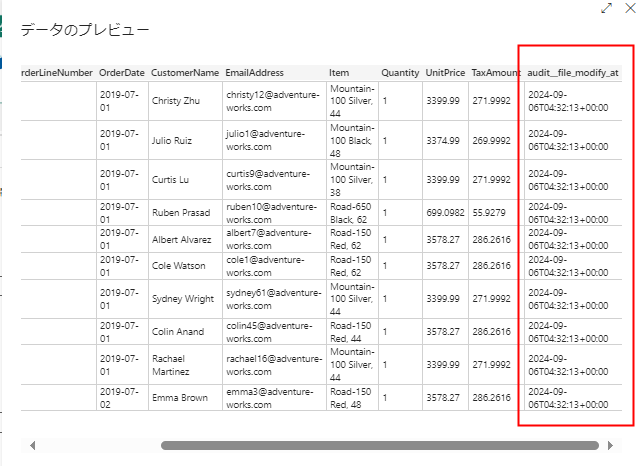
audit__run_date もパーティション形式なので取得可能ですが、日々のバッチ処理で今回の処理日時外のファイルまで読み取られてしまうので外しています。
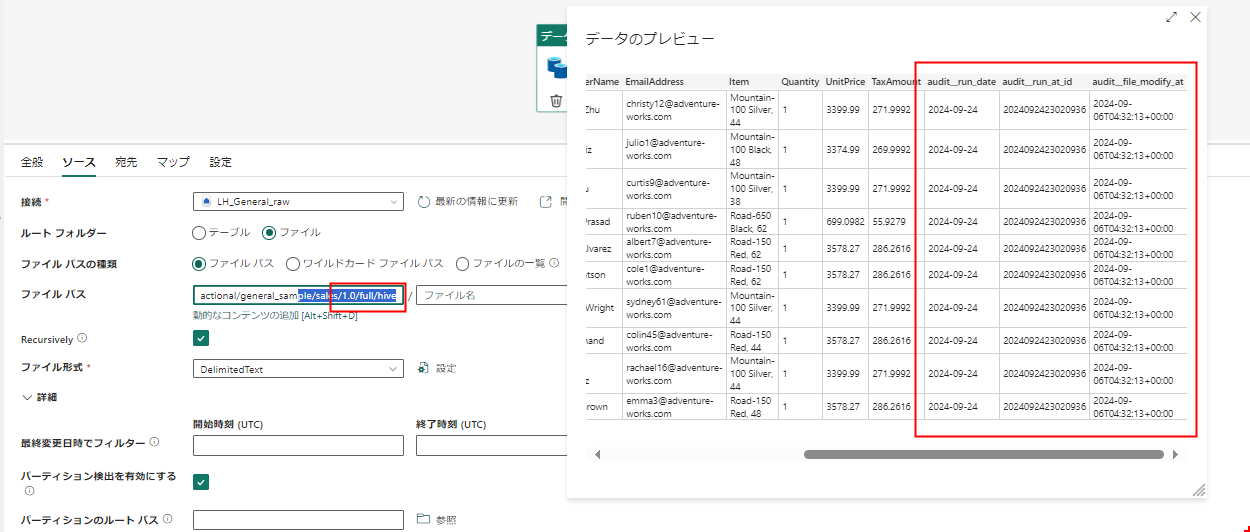
ついでに、ファイル名などの情報もレコードにしてしまいます。
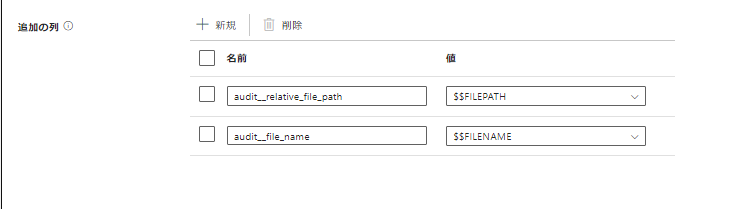
このあたりの仕様は コピー中に列を追加する を参照
あて先の指定
今回はテーブルを上書きするように構成します。

マッピング
今回はマッピング指定なしで実施します。ソースで読み取られた列がすべてそのまま反映されます。
型変換や、列名のマッピングを必要とする場合にはマッピングをします。


3. 結果確認
実行結果を確認します。
プレビュー
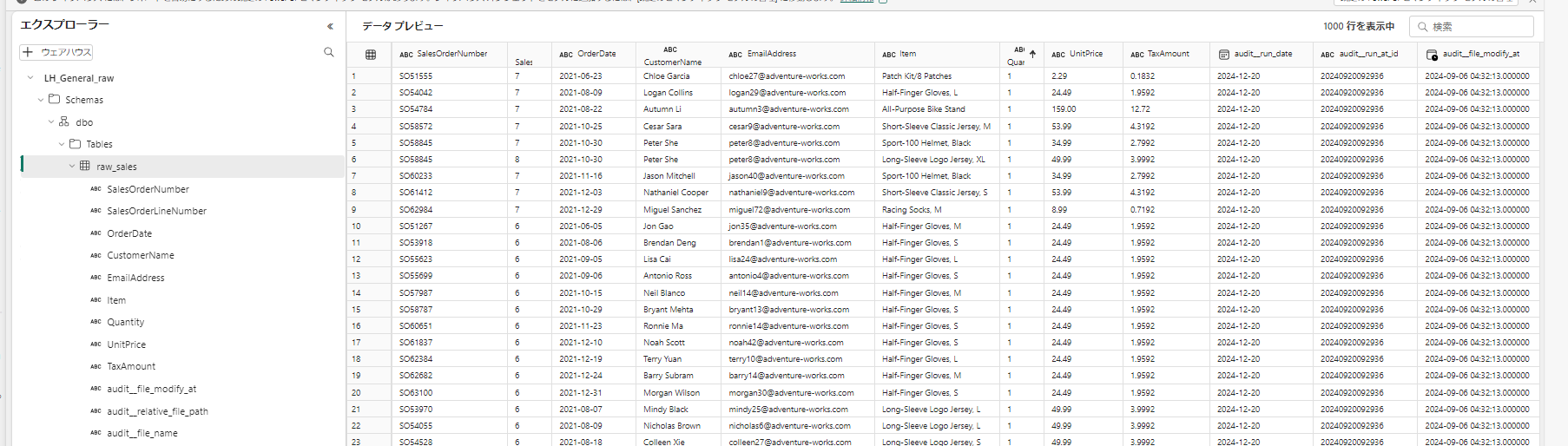
ファイル名と最終変更日時の組み合わせ