はじめに
初学者向けというかというと微妙ですが、データ量が増えた際に覚えておくとよいこととして紹介します。
Power BI ユーザー定義集計機能の仕組み
ニーズ
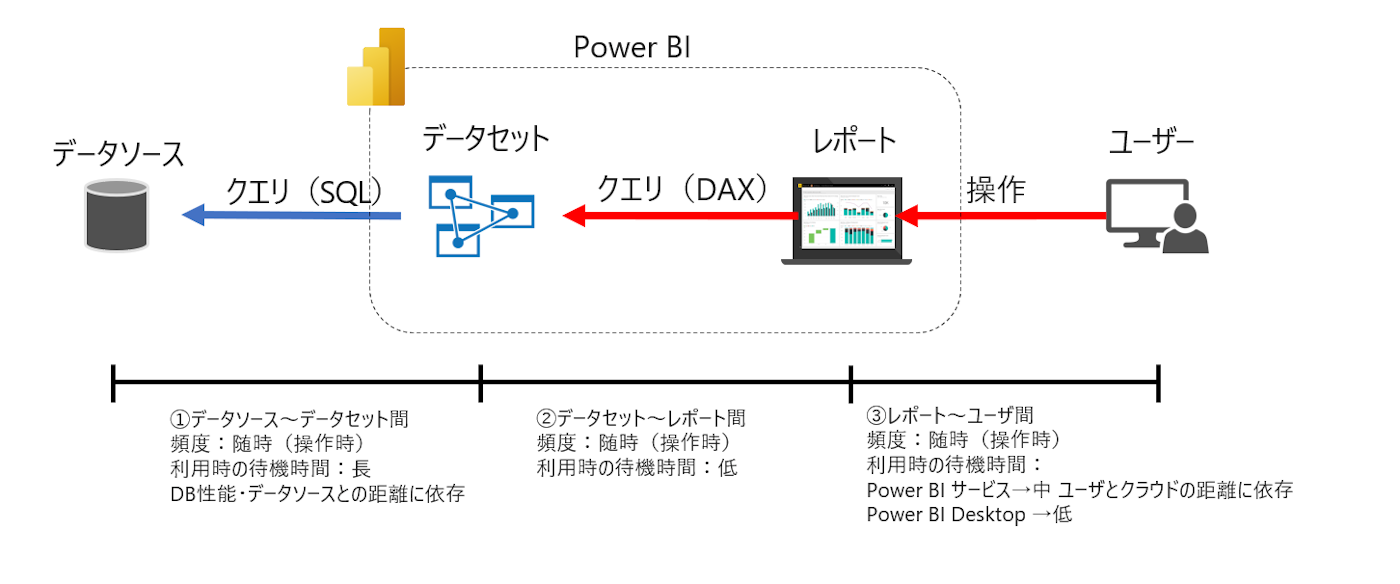
Power BIのデータセットにはいくつかの種類があり、改めてPower BI データセットのストレージモードについて整理するでも解説したように特徴と選定基準があります。
基本的にはレポートに一番近い場所でデータ処理させるImportが推奨なのですが、データ量が増えるとImportでは保持しきれなくなります。
そうしたときDirect Queryを選択しますが、Direct Queryは以下のイメージのように毎回クエリを発行し、データソースを処理させるため、待機時間が長くなっていきます。
一般的に集計されたテーブルの行数<<集計前のテーブルの行数なので、サイズの大きい集計前のテーブルはDirect Queryモード 、サイズの小さい集計結果はImportモードという形で、テーブルごとに異なるストレージモードを設定する複合モデルによる構成が考えられます。
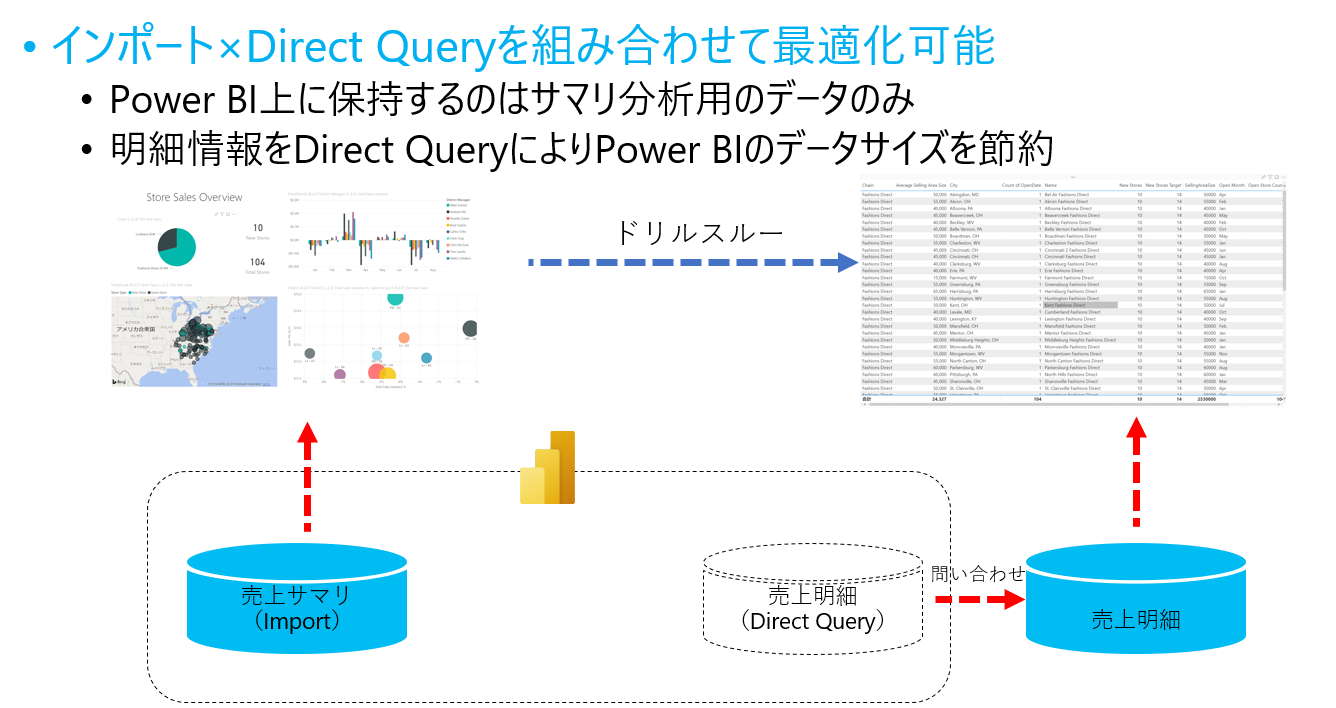
これでいいように思えますが、データモデルとしては問題があります。
集計保持目的で単純に複合モードを利用すると、売上サマリテーブルと売上明細テーブルがモデル上に二つ存在することになり、集計レポートのときは売上サマリテーブルの列をもってくる、明細レポートのときは明細テーブルの列をもってくる、というデータと本質的に関係のない利用上の注意が生まれてしまいます。
集計機能の仕組み
複合モードが利用されることは変わりません。
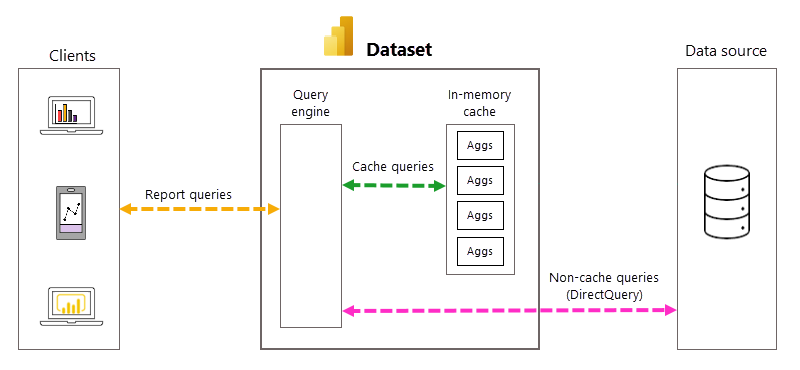
レポート作成者が同じ列を使用しても、レポート上で発生したクエリ「Report querys」の内容により「Query engine」がどのテーブルで解決するのかを以下のように判定してくれます。
- 集計のための利用であれば、あらかじめメモリに保持したImportモードのテーブル「Cache queries」から取得します。
- 明細など、事前の集計で対応できない内容であれば「Non-cache queries」としてDirect Queryの処理として直接データソースにクエリを発行します。
Power BI Premiumの自動集計(Preview)
今回は紹介しませんが、今回紹介するユーザ側で集計の設定を行う方法とは別に、Premium機能として、AIがよく利用されるReportクエリを学習し、自動的にImport Mode用の集計テーブルを作成してくれる機能があります。
やっている内容は同じなので、裏側の基本的な仕組みを理解してもらえればと思います。
試してみよう
手順概要
- Viewの作成
- Power BI Desktopで接続、時間計測
- ユーザ定義集計の設定
- 結果確認
必要なもの
- Synapse Analytics リソース
- Power BI Desktop
手順
1. Viewの作成
Synapse Studioにログインし、以下のSQLを実行します。
CREATE DATABASE [agg_test];
GO
USE [agg_test];
GO
CREATE VIEW [v_nyc_raw] as
SELECT
YEAR(tpepPickupDateTime) AS intYEAR,
tpepPickupDateTime,
passengerCount
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=2018/puMonth=*/*.snappy.parquet',
FORMAT='PARQUET'
) WITH (
tpepPickupDateTime DATETIME2,
passengerCount INT
) AS nyc
where passengerCount <10 -- 外れ値除去
;
CREATE VIEW [v_nyc_agg] as
SELECT
intYEAR,
passengerCount,
COUNT(*) AS cnt
FROM
[v_nyc_raw]
GROUP BY
passengerCount,
intYEAR
;
概要は以下の通り。Microsoftの提供するNYCタクシーデータセットを参照しています。
- v_nyc_raw:rawデータ→未集計のレコードを表示するViewです。
- v_nyc_agg:aggregateデータ→v_nyc_rawを集計した結果を表示するViewです
2. Power BI Desktopで接続、時間計測
Power BIに接続します。「Direct Query」にしておきます。
先ほど作成したViewを取得します。
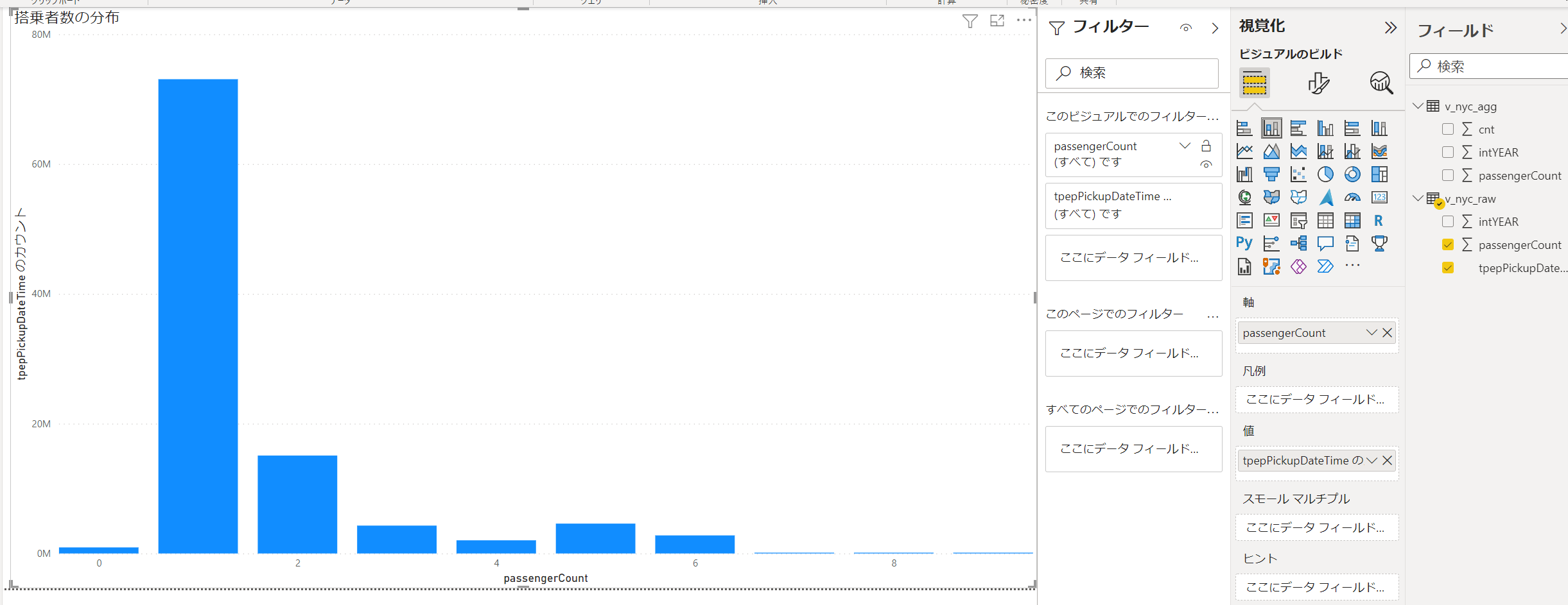
passengerCountを軸に、行カウントを値にして、分布図を作成します。
時間計測していきます。
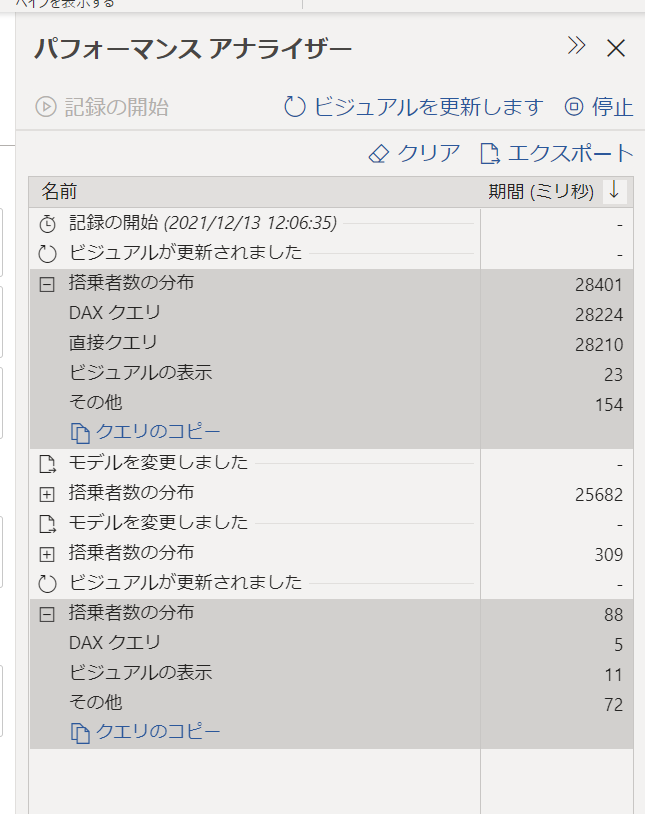
パフォーマンスアナライザーを利用すると、レポートのパフォーマンスを計測できます。
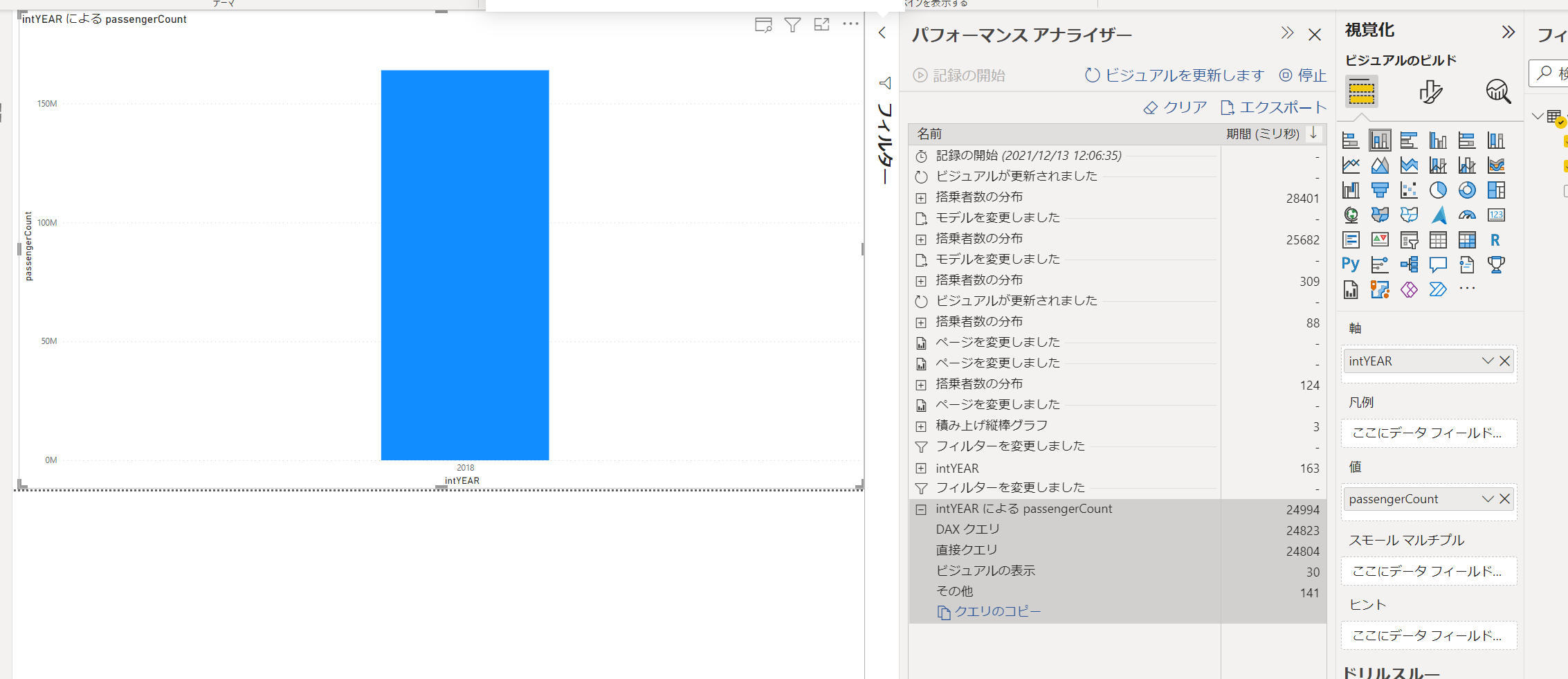
結果はこのようになりました。
DAXクエリの一環として直接クエリ(データソースへのクエリ)が発生し、その応答に28秒ほど消費しています。
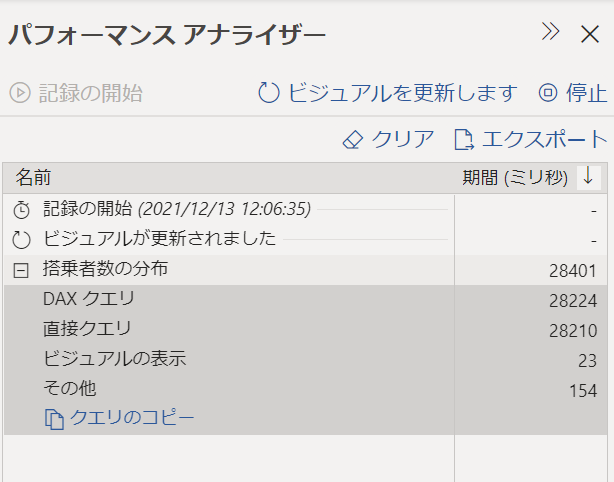
直接クエリにかかる時間は、「データソースのクエリ性能」「データソースとの物理的な距離」などによって変わります。
今回のレポートは集計クエリから出来上がるものなので、集計機能を利用してこのレポートパフォーマンスを向上させることができます。
3. ユーザ定義集計の設定
集計の定義はモデルビューから行います。
集計結果を表示するテーブルの「・・・」から「集計を管理」を選択します。
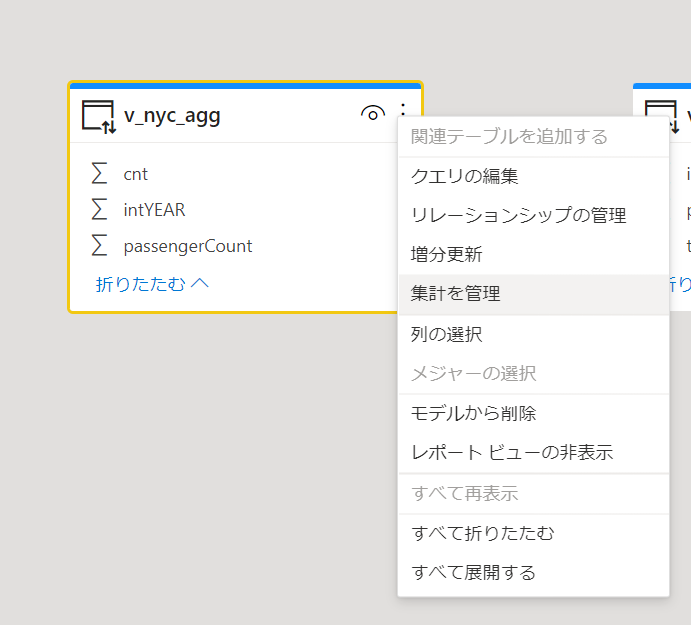
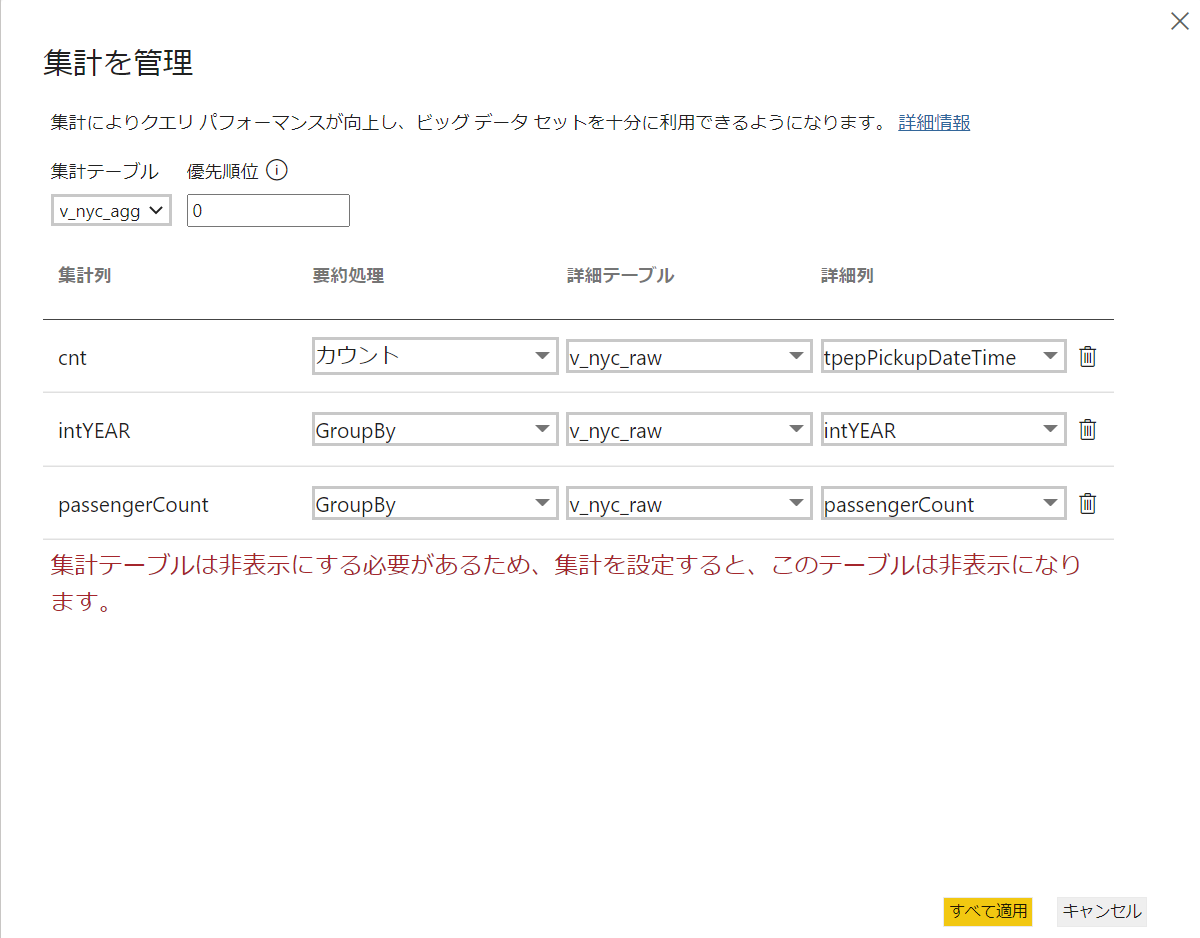
集計の管理設定画面に移り、v_nyc_aggテーブルの項目が何の集計結果なのかを指定していきます。
- 要約処理:集計項目 or group by項目なのかを選択します。
- 詳細テーブル:基テーブル選択します。
- 詳細列:基となっている列を選択します。
※詳細列の設定された列と処理の内容でレポート設定したときにのみ集計機能が動作します。逆に言うと、行カウントなど、どの列を選んでも結果が同じとなる集計であっても、ここに指定しなかった列でカウントを設定すると、集計は効きません。今回行カウントの項目を用意しませんでしたが、行カウントが必要となる際は行カウント用の項目を準備してください。
なお、集計テーブルはデータソース側で作成しても、Power Queryで作成してもよいです。
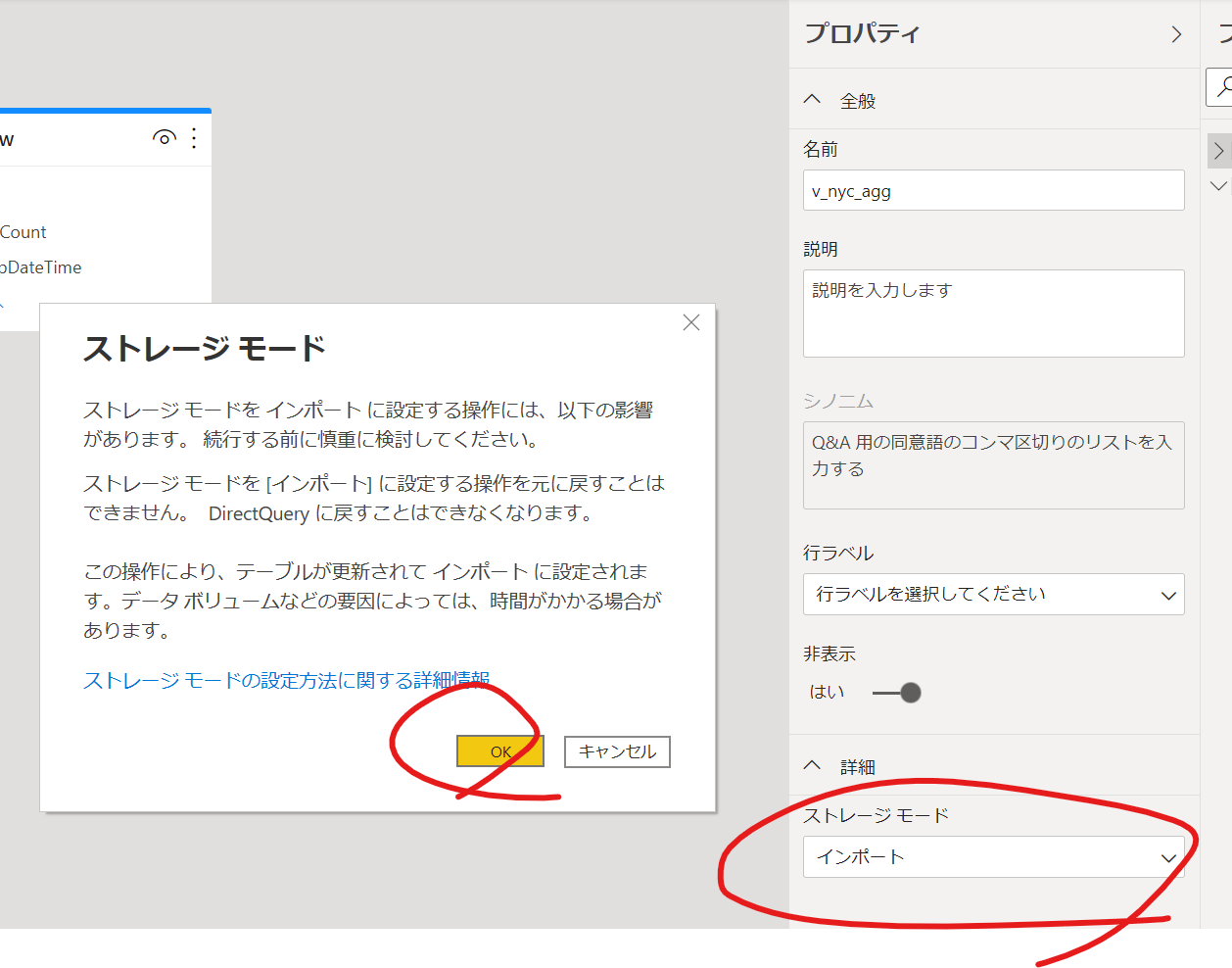
集計テーブルは非表示設定となります。集計テーブルはインポートにしておきます。
これにより、集計テーブルで保持している結果はデータソースシステムではなく、メモリ上に展開されているPower BI のデータセットから直接応答されます。
4. 結果確認
確認していきます。レポート側の設定は変えません。
基テーブルとして指定されている、「v_nyc_raw」の項目を使用するだけで、集計の管理で設定した集計内容であれば、自動的に集計テーブルの情報で応答されます。
集計適用前は28秒でしたが、集計を適用したあとの一番下の結果はDAXクエリと表示処理その他のみが発生しており、0.1秒以内にレポートを表示しています。
おまけ
集計の管理で設定した内容以外でレポートを作ると、集計テーブルで解決せずにデータソースに直接クエリします。
集計で保持していないpassenger_countのSUMを取っており、24秒を消費しています。