はじめに
Microsoftが公開している、Purview-Machine-Learning-Lineage-Solution-Acceleratorと、
私のほうで手順を簡易化した日本語版リポジトリをご紹介します。
注意:10分は環境構築、初期設定までとなっており、後続のカタログのスキャン、ML処理の実行は4,50分かかります。
Purview Machine Learning Lineage Solution Accelerator
GUIでセットアップできるPurviewのリネージサポート対象はData Factory , Synapse Pipeline と双方で提供されるDataflowが中心となっています。
このとき、機械学習、データエンジニアリングで使用される、Python、Sparkをコード実行した場合にリネージが途切れるということが起こります。
こうしたカスタムコードでのデータ処理においても、PurviewのApache Atlas エンドポイントを使用してAPIを通じたリネージ登録が可能です。
下記のリポジトリで提供されるソリューションを使用すると、PurviewのApache Atlas エンドポイントを使用してカスタムアセットを登録することができます。
Purview-Machine-Learning-Lineage-Solution-Accelerator
全体イメージ抜粋:
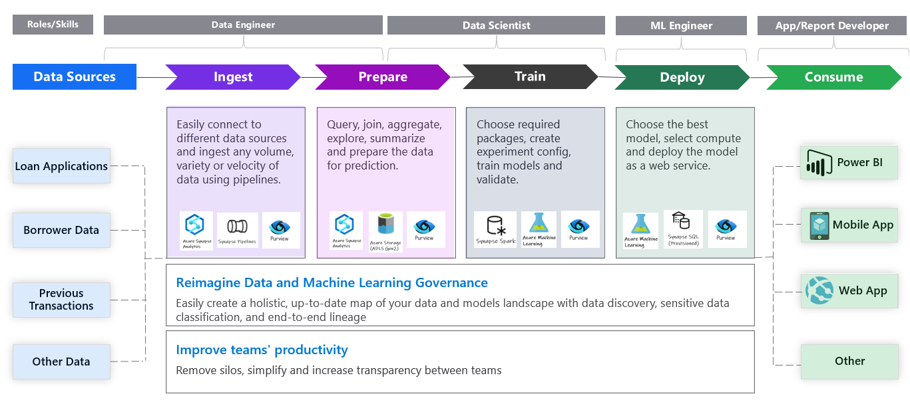
参考
Purview Machine Learning Lineage Solution Acceleratorで使用されている、Atlas エンドポイントをpythonから簡単に使用できるライブラリです。
Microsoftの方が公開されています。
日本語版手順のリポジトリ紹介
モチベーション
このソリューションアクセラレータ、ものすごく有用なんですが、手順が多いため(10stepくらい)、できる限りコード化して素早く環境をセットアップできないかと考えて、ちょうど勉強していたbicepを使いつつDataOps for the Modern Data Warehouseを参考にして日本語版を作成しました。
リポジトリ
以下の通りです。VSCodeのRemote Containerは本当に便利なのでこれを期に試してみてください。
リンク
また、なにかうまくいかない点などあったら指摘お願いします。
主な変更
- Step 2. Purview Security Access を自動化
- Step 3. Azure Machine Learning Security Accessを自動化
- Step 4. Synapse Security Accessを自動化
- Step 5. Upload CreditRisk Sample Datasetを自動化
- Step 6. Register and scan uploaded data in Purviewをスキャン登録まで自動化
- Step 7. Upload Assets and Run Noteboksを自動化(一部不具合のため現在別方法で手動手順化
更新予定
- variable.json内でService Principal Secretを記載させる仕組みをKey Vaultに保持に変更
- ワークスペースパッケージの不具合改善後の修正反映
- Spark3.xでの構成
pyapacheatlasのデバッグ方法参考
- help(対象)により、各種メソッドを確認できます。
- client.get_all_typedefs()によりPurviewとの疎通が確認できます