概要
Azure Data FactoryからAzure SQL Databaseへデータを書き込む際には、事前にファイル分割の実施することで、処理時間が短くなることが検証の結果からわかりました。
コピーアクティビティではデータ統合ユニット(DIU)の設定値を増やすことで性能を向上させることができるのですが、DIUの上限は、ファイル数に比例するという仕様が要因となります。
- 単一ファイルからコピーする:2-4
- 複数のファイルからコピーする:ファイルの数とサイズに応じて 2 〜 256。
例えば、4 つの大きなファイルを含むフォルダーからデータをコピーする場合、最大の有効な DIU は 16 です。
下記のようにDIUを設定しても、
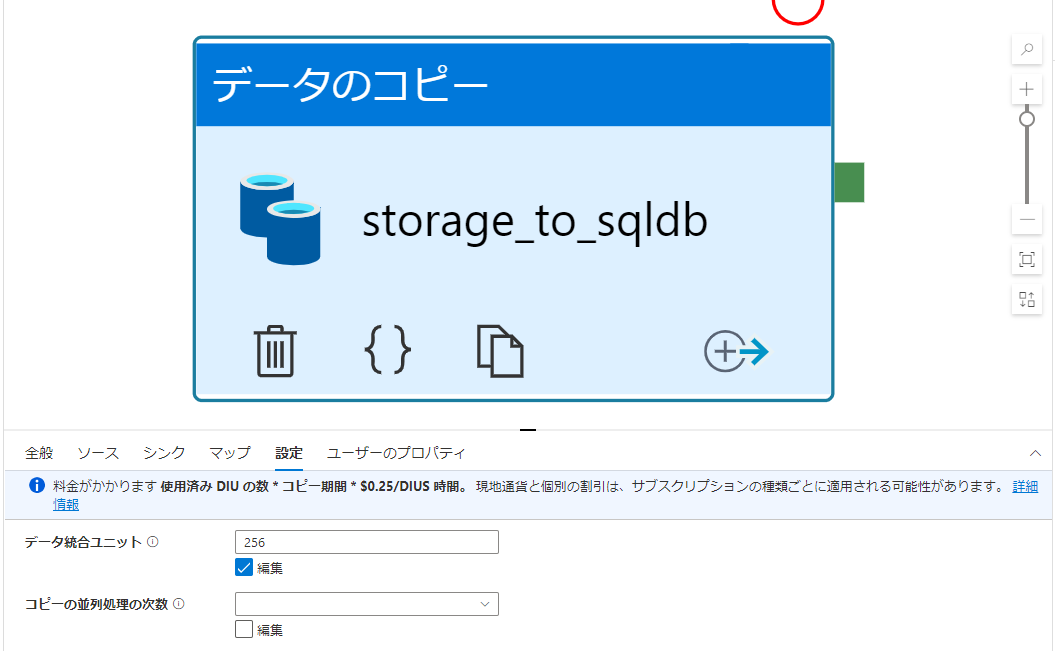
実行時に使用済みのDIUの数値が設定値(256)より低い値(4)となっておりました。

同じ設定でファイルを分割すると、下記のように設定値である256が使用済みDIUとなっておりました。

今回はAzure Synapse Analytics Spark poolでファイルを分割しましたが、単一ファイルの分割に要した時間の増分を考慮しても、分割したファイルをコピーアクティビティで取り込む方が約3分の2の時間で完了しました。3GBのファイルでの実行であったため、大きなファイルサイズの場合には、より改善の効果を望めるかもしれません。
検証内容概要
Azure Synapse Analytics Spark poolにて、TPC-HのLINEITEMのテキストファイルに対して、下記の実行によりファイルを分割
私の環境で実行したところ、60個のファイルに分割されました。repartition関数によりファイル数を指定することも可能です。
from pyspark.sql import SparkSession
from pyspark.sql.types import *
blob_account_name = 'accoun_name' # replace with your blob name
blob_container_name = 'adf' # replace with your container name
blob_relative_path = '/' # replace with your relative folder path
linked_service_name = 'AzureBlobStorage1' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasbs_path)
filepath = wasbs_path + '/10/*'
output_path = wasbs_path + '/spark_10/'
schema = """
L_ORDERKEY INTEGER ,
L_PARTKEY INTEGER ,
L_SUPPKEY INTEGER ,
L_LINENUMBER INTEGER ,
L_QUANTITY DECIMAL(15,2) ,
L_EXTENDEDPRICE DECIMAL(15,2) ,
L_DISCOUNT DECIMAL(15,2) ,
L_TAX DECIMAL(15,2) ,
L_RETURNFLAG STRING ,
L_LINESTATUS STRING ,
L_SHIPDATE DATE ,
L_COMMITDATE DATE ,
L_RECEIPTDATE DATE ,
L_SHIPINSTRUCT STRING ,
L_SHIPMODE STRING ,
L_COMMENT STRING
"""
df = (spark
.read
.format("csv")
.schema(schema)
.option("sep", "|")
.load(filepath)
)
(df.write
.format("csv")
.mode('overwrite')
.option("sep", "|")
.save(output_path)
)
Azure Data Factoryにて、コピーアクティビティのタスクを作成
Azure Data Factoryにて、コピーアクティビティの設定タブにて、データ統合ユニット(DIU)の値を操作
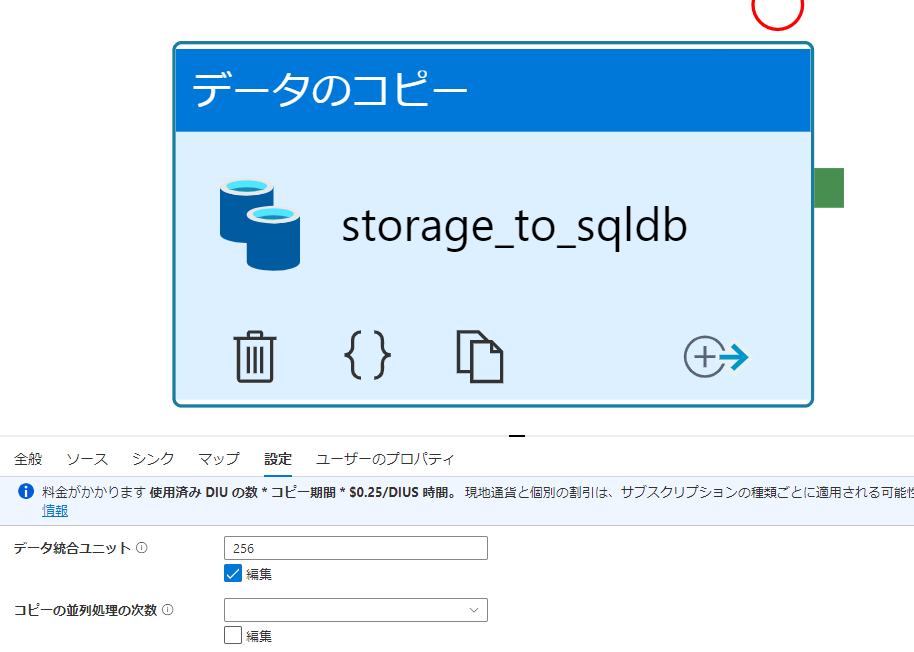
DIUを指定しない場合に、使用済みDIUの値が大きくならないことがあるため、注意してください。
