AWS AppSync の実装フローを理解する
AWS AppSync はフルマネージドの GraphQL サーバです。
AppSync を使ったAPI実装のフローは独特なので AppSync 用の学習が必要です。
「AppSyncを採用した場合、実際どういう実装フローになるのかコードレベルで理解したい」という方が対象読者です。
実装フローに焦点を当てているので、AppSync 自体の特徴の説明などは省略します。
構造を理解する
AppSync のサービスそのものの構造は下記のような感じです。
- API
- has a Schema
- has many Resolvers
- has many Datasources
- has many Functions
- トップに API というリソースがあり、これは GraphQL のスキーマ定義と1対1で対応しています。
- 上記の中の Schema が GraphQL のスキーマ定義になります。
- スキーマには、複数のリゾルバーが紐づきます。
- GraphQL スキーマの任意のフィールドに対して任意のリゾルバを作成することができます。
- データソースは、AppSync が参照するデータの保存場所のことです。
- 基本的には DB のことなんですが、AWS の DB 系サービス以外の DB を使用する場合はデータソースに「HTTPエンドポイント」や「Lambda」を指定することになります。あくまでもデータの参照先というイメージですね。
- 「関数」という AppSync の概念があります。これは後述の「パイプラインリゾルバー」で使用される独立した処理のことです。
スキーマを記述する
まず何はともあれ GraphQL なのでスキーマを定義します。
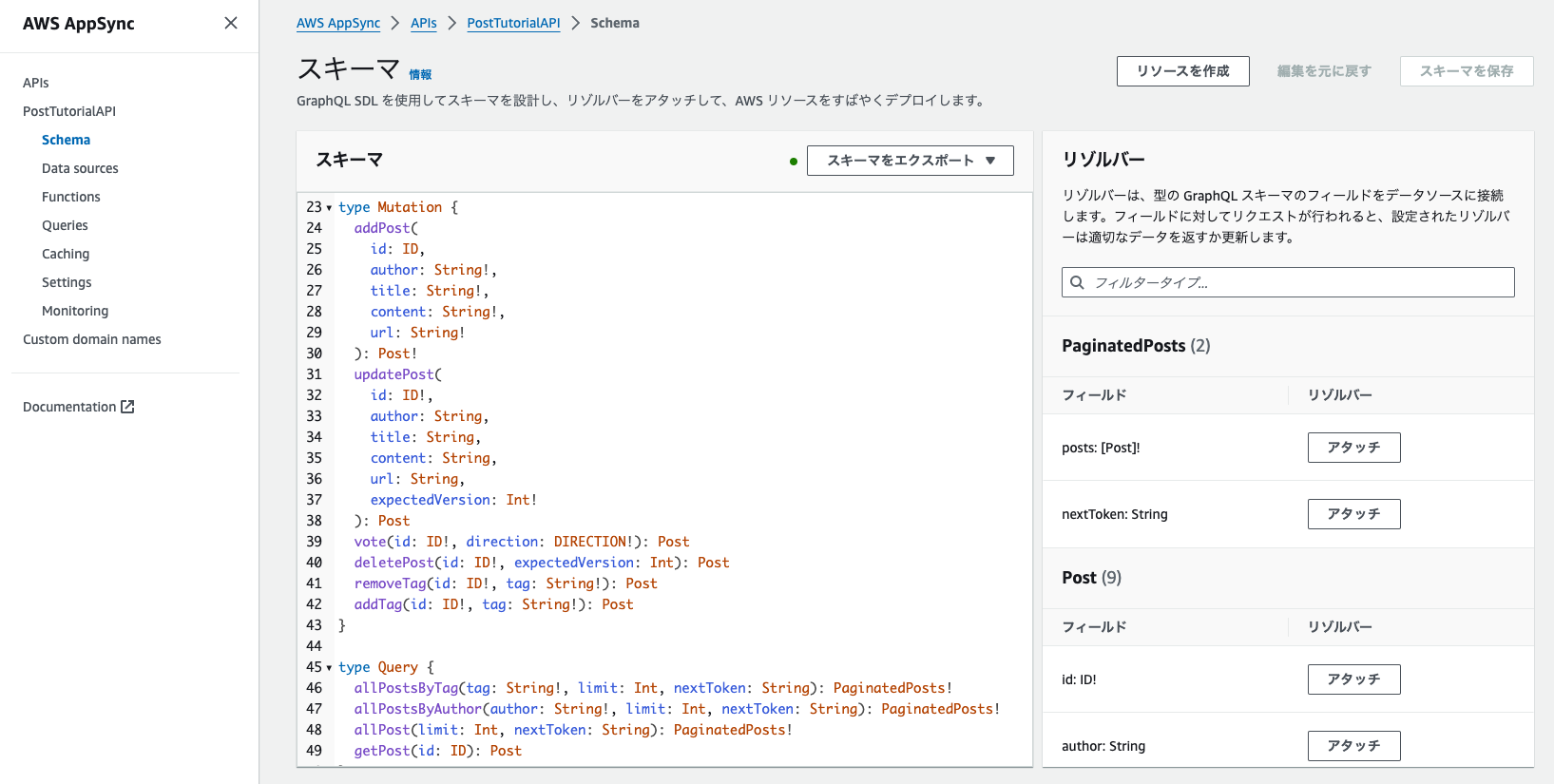
![]() これは実際のコンソール画面のスクショです。
これは実際のコンソール画面のスクショです。
左のメニューでスキーマを選択し、中央のエディタに記述します。
スキーマを記述すると右の欄にフィールドが一覧されるので、そこから任意のフィールドに対してリゾルバーを作成(アタッチ)することができます。
データソースを設定する
サービスの DB を何にするかを指定します。一つの API に複数のデータソースを登録できます。
AppSync 的には DynamoDB を標準的な AppSync のデータソースとして推していますが、基本的に AWS 内外問わずなんでも使うことが可能です。
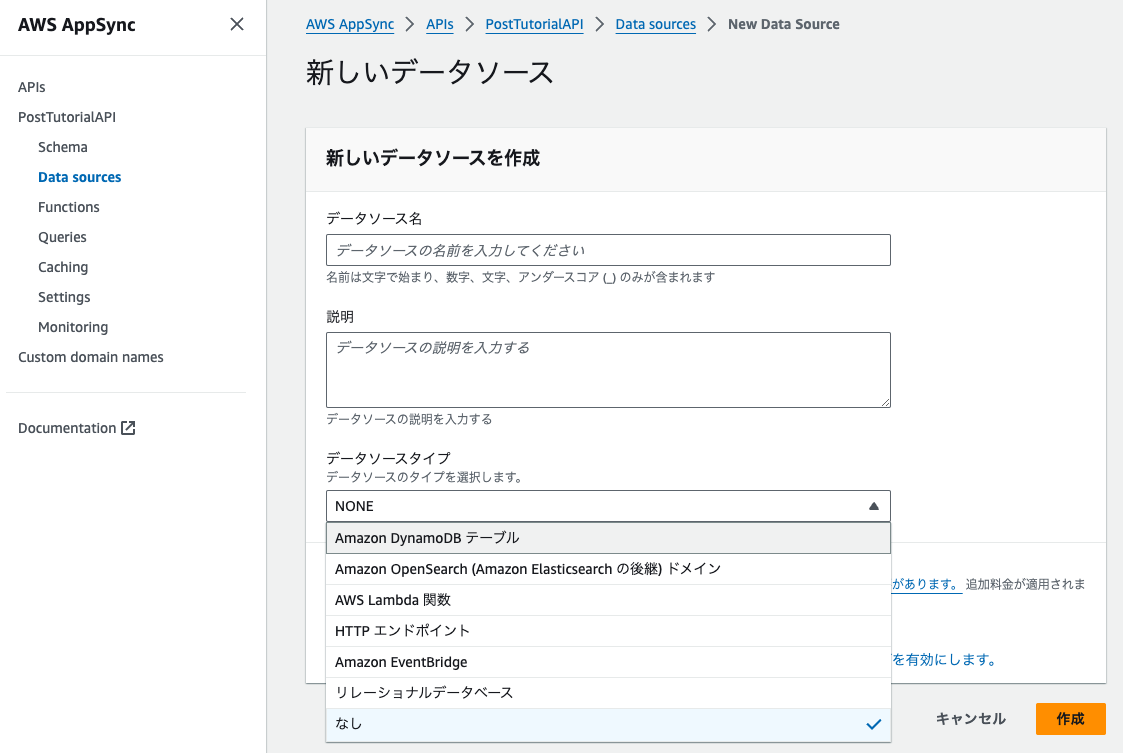
![]() これが実際に AppSync にデータソースを登録する画面です。
これが実際に AppSync にデータソースを登録する画面です。
リゾルバーを定義する
2種類のリゾルバー
AppSync には2種類のリゾルバーが存在し、作成する時にどちらにするかを選ぶことができます。
① ユニットリゾルバー
単一のデータソースから値を取得する処理を実装できます。
② パイプラインリゾルバー
- 複数のデータソースから値を取得する処理を実装できます。
- 「ある一つのデータソースに対する取得(変更)処理」を一つの「関数」として定義することができ、複数の関数を繋いで構成します。
一つのデータソースからの取得の処理などはユニットリゾルバーで実装できますが、複数のデータソースを跨ぐ処理はパイプラインリゾルバーで実装します。
この二つの違いの詳細は公式ドキュメントだと以下のページが分かりやすいです。
実装方法
VTL(マッピングテンプレート)
AppSync を調べていると「マッピングテンプレート」という言葉が出てくるのですが、自分の理解だと「VTLで記載されたリゾルバー」のことをマッピングテンプレートと呼んでいるようです。
VTL(Apache Velocity Template Language)を使わない場合はマッピングテンプレートという単語は使わずに済む...はずです、多分。
JavaScript
VTL 以外だと JS を使うことができます。
ただし特殊なランタイムでかなり色々な制限があるので注意です。
今から始めるなら順当にこちらで良いでしょう。
Lambda
あるいは、データソースを Lambda にすればそういった AppSync 特有の言語や環境の制限なく一般的な Lambda 関数を実装する形で実装できます。
複雑なロジックを完全なコントロール下で実現したい場合は Lambdaにしてしまう方が長期的に見て楽な気がします。
実装内容
実際に JS でのリゾルバーの実装を紹介します。
データソースが DynamoDB でユニットリゾルバーの場合
DynamoDB のユニットリゾルバーのチュートリアルのコードです。
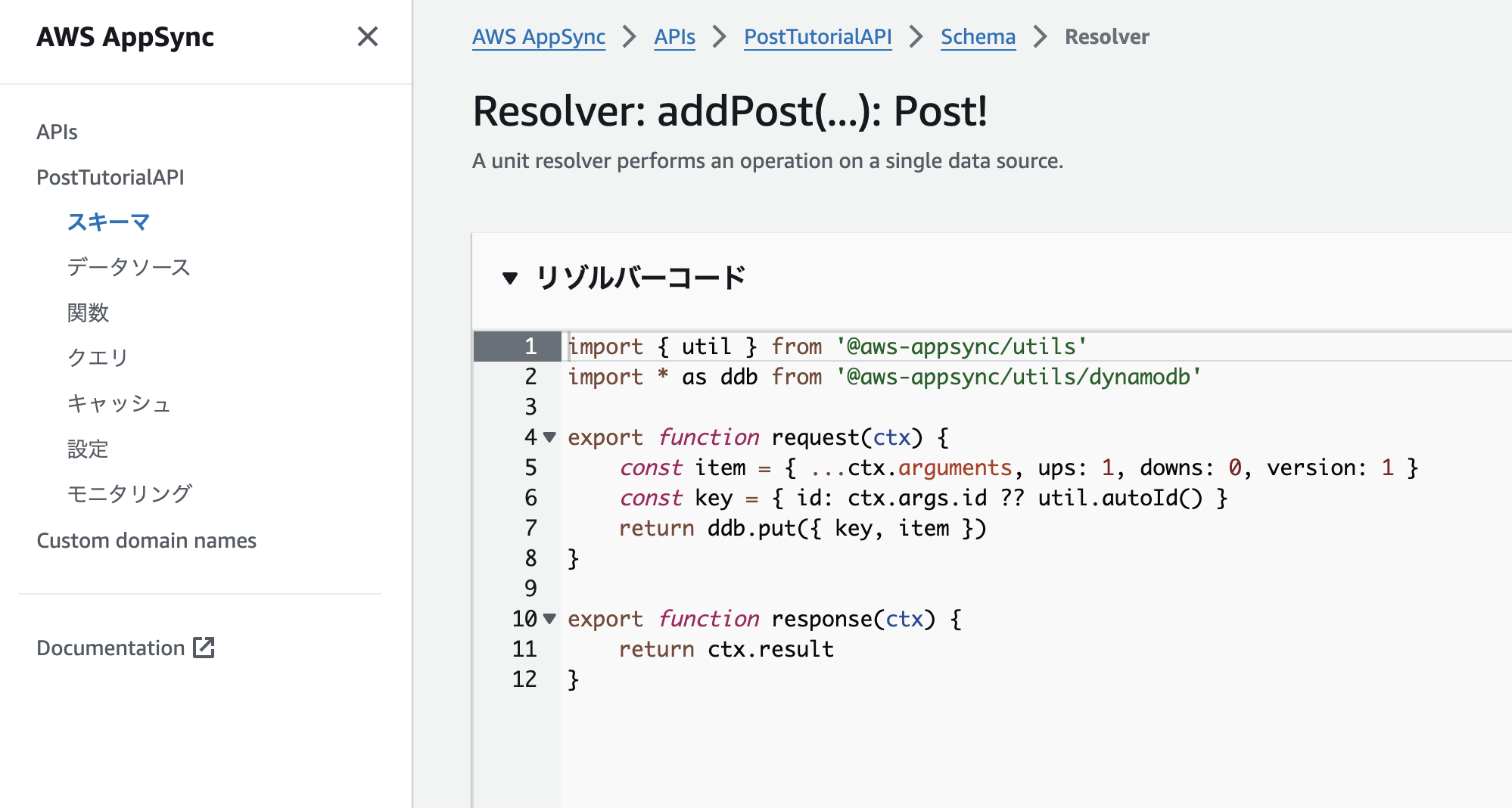
import { util } from '@aws-appsync/utils'
import * as ddb from '@aws-appsync/utils/dynamodb'
export function request(ctx) {
const item = { ...ctx.arguments, ups: 1, downs: 0, version: 1 }
const key = { id: ctx.args.id ?? util.autoId() }
return ddb.put({ key, item })
}
export function response(ctx) {
return ctx.result
}
request() は GraphQL が受け取ったリクエストを捌く処理で、response() は GraphQL が送信するレスポンスを用意する処理です。
リゾルバーは GraphQL と DB を繋ぐサーバアプリケーションの実装です。
DB <-> リゾルバー <-> GraphQL(AppSyncエンドポイント) <-> クライアント
このリゾルバーの左右の矢印が、以下のように関数に対応しています。
-
request()DB <- リゾルバー- DB への取得処理を返す。
-
response()リゾルバー -> GraphQL- DBからデータを受け取り GraphQL 用に整えて返す。
request 関数は、決まった形式のオブジェクトを返す必要があります。
形式は接続するデータソースによって異なるので、ドキュメントの参照が必要です。
例えば DynamoDB の場合は以下のページで確認できます。
DynamoDB への CRUD 命令を表現するのでたくさんの種類があります。
データソースが DynamoDB でパイプラインリゾルバーの場合
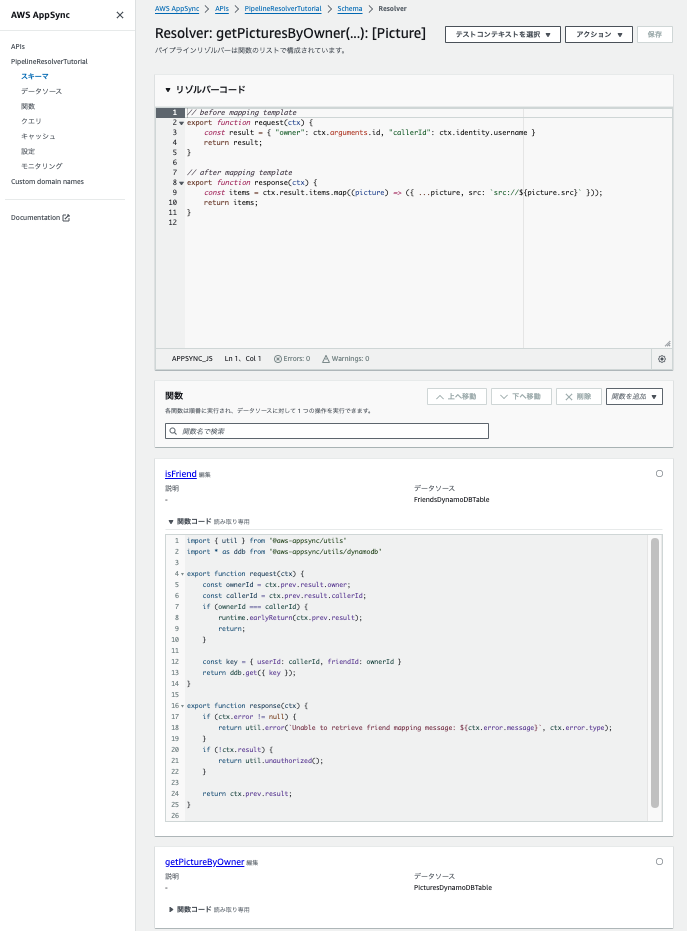
パイプラインリゾルバーの場合、ユニットリゾルバーと異なり、
- Before テンプレート
- 1個以上の関数
- After テンプレート
という要素で構成されます。
ここで言う「関数」というのは AppSync 用語で、パイプラインリゾルバーに含めることができる再利用可能な処理のパーツです。
実態はほぼユニットリゾルバーと同じで、 request と response のセットです。
![]() 上の例では、「リゾルバーコード」の下にある
上の例では、「リゾルバーコード」の下にある isFriend と getPictureByOwner が関数です(isFriend の方だけコードが見えるように展開しています)。
イメージ的には Express のミドルウェアと同じ構造ですね。
形式が決まっている複数の処理を繋げることで最終的にレスポンスを返します。
関数のみだとそのリクエスト用の処理が存在しないので、関数の前後に Before テンプレートと After テンプレートがあり、そこでリクエスト固有の前処理と後処理を実装できます。
データソースを Lambda にする場合
続いて Lambda のチュートリアルのコードです。
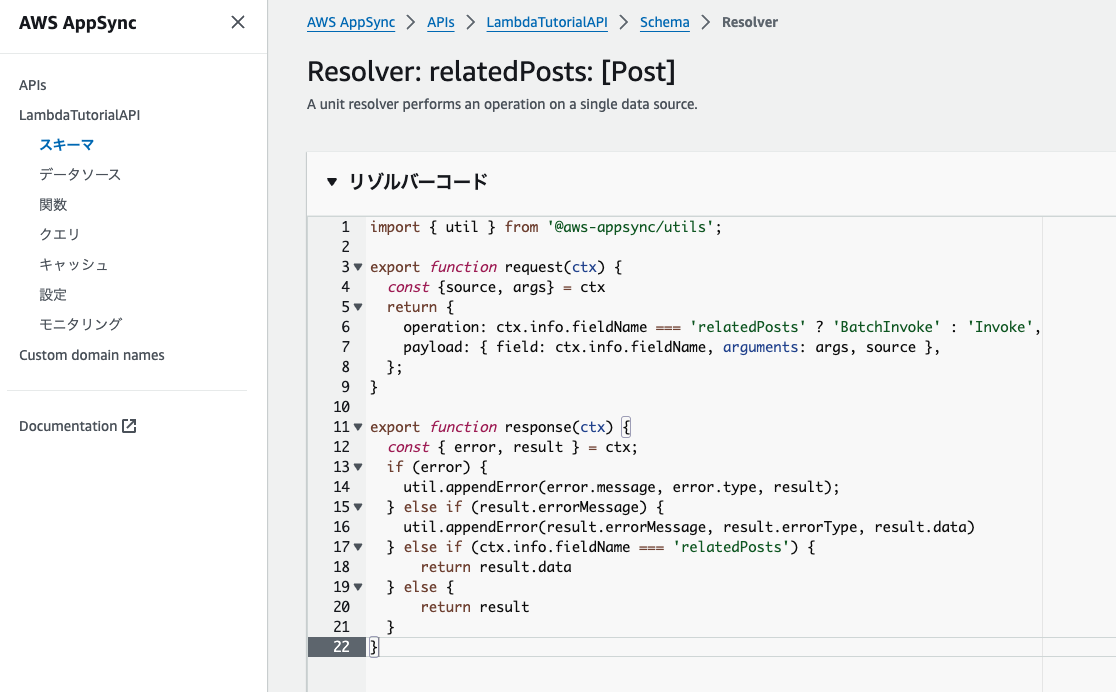
import { util } from '@aws-appsync/utils';
export function request(ctx) {
const {source, args} = ctx
return {
operation: ctx.info.fieldName === 'relatedPosts' ? 'BatchInvoke' : 'Invoke',
payload: { field: ctx.info.fieldName, arguments: args, source },
};
}
export function response(ctx) {
const { error, result } = ctx;
if (error) {
util.appendError(error.message, error.type, result);
} else if (result.errorMessage) {
util.appendError(result.errorMessage, result.errorType, result.data)
} else if (ctx.info.fieldName === 'relatedPosts') {
return result.data
} else {
return result
}
}
もちろん構造は DynamoDB の場合と同じです。request が返すオブジェクトが Lambda 用の形式に変わりました。
Lambda 用は以下のページで確認できます。
Lambda の場合は基本的に呼び出すだけなので Invoke か BatchInvoke の2種類だけです。
N+1 問題への対応
基本的にデータソースを Lambda にして BatchInvoke オペレーションを使用することで対応することになるようです。
最大バッチサイズを指定した上で BatchInvoke を使用すると、複数回の呼び出しを AppSync 側で一つにまとめて Lambda を呼び出してくれます。
import { util } from '@aws-appsync/utils';
export function request(ctx) {
const {source, args} = ctx
return {
operation: 'BatchInvoke',
payload: { field: ctx.info.fieldName, arguments: args, source },
};
}
export function response(ctx) {
const { error, result } = ctx;
if (error) {
util.appendError(error.message, error.type, result);
}
return result;
}
これだけ。これでこのリゾルバーをアタッチしたフィールドは複数回呼ばれる時にまとめられます。
おしまい
AppSync の実装フローでした。