本記事の目的
もともと本業でデータサイエンスやディープラーニングを扱っていたわけでもなく、ディープラーニング周りは「なんとなく知っている」という状態。ちゃんと勉強したいと思いながらもなかなか手が出ず、モデル実装の経験もない。
上記の状態から、この1年間くらいでやっと、初めてディープラーニング実装の経験をするところまでたどり着いた。とりあえずデータサイエンスの入口に立てた(かもしれない)ということで、整理のためここまで取り組んできたことをまとめてみた。
これから勉強を始める、誰かのために役立てば嬉しい。
<画像ディープラーニングの始め方>
◇ ステップ1. 画像系AIの全体像を把握する
◇ ステップ2. 画像分類を実装してみる
◇ ステップ3. 理論をフォローアップする
◇ ステップ4. 実装の経験を積む
ステップ1.画像系AIの全体像を把握する
とりあえず初心者向けの書籍や動画などを見て全体像を把握する。以下では書籍や教材の紹介ではなく「まずはこの辺りをつかんでおけば良いだろう」と思われる部分についてまとめてみた。
画像系のAI課題を整理すると、大体以下のようになると考えている。この辺りの全体像がつかめていると、世の中の画像系AIがどの部分の課題を解いているのかが整理できるのでだいぶ理解が楽になる気がする。
※ ①~⑤と数字が上がるにつれてAI課題としての難易度も上がっていくイメージ。
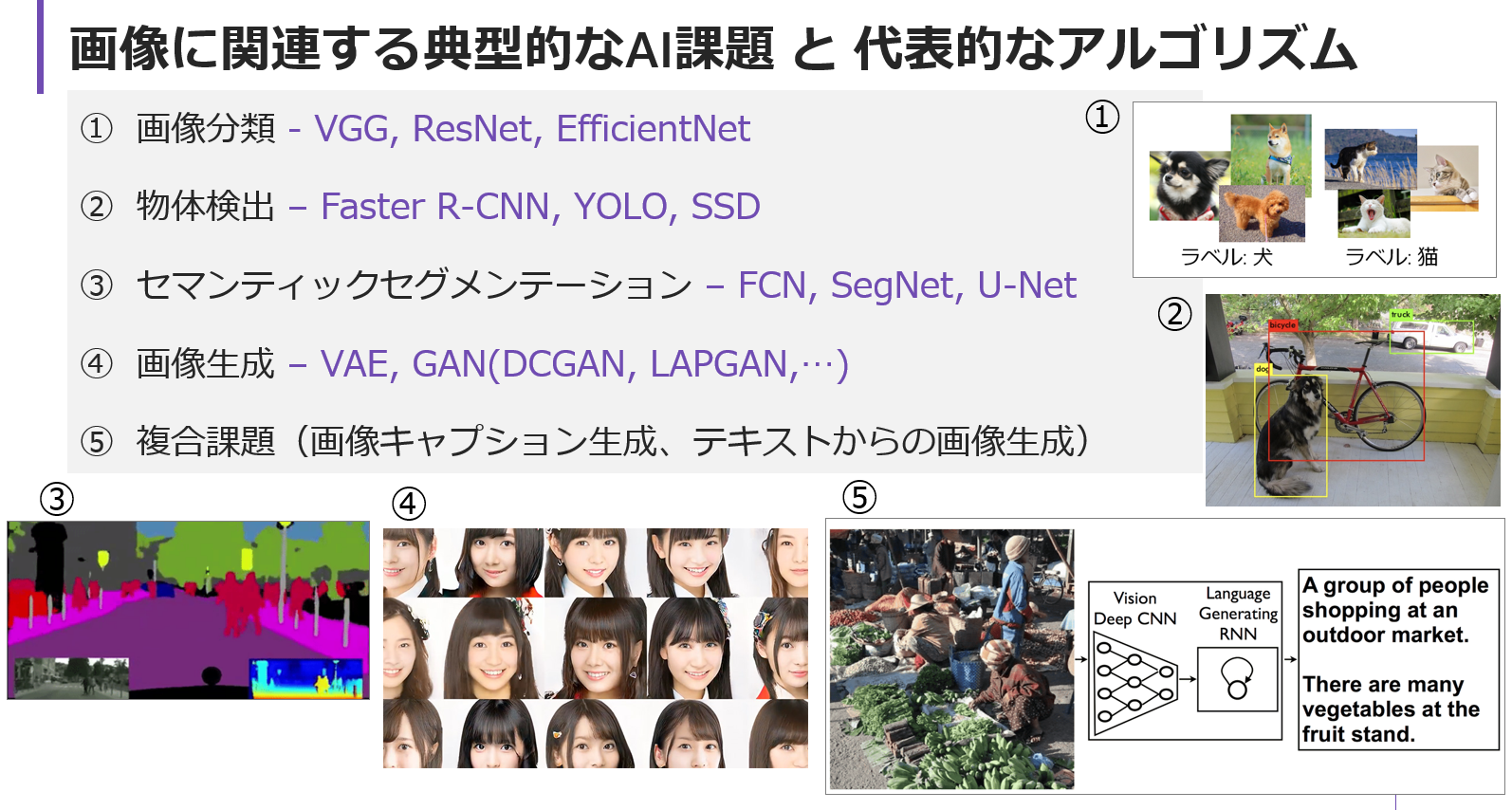
各①~⑤それぞれの問題については以下でざっとまとめてみた。
1. 画像分類(Image Classification)
1枚の画像が与えられたときに、1つのラベルを返す。
画像系AIの中では最も基本になるタスク。
【モデルの例】
VGG、ResNet、EfficientNetなど。
【学習に利用できるデータセットの例】
ImageNetが有名。画像とラベルがペアで与えられているデータセット。
http://image-net.org/index

【実用例】
様々な業界で実用例がある。農業や漁業といった第一次産業でも実用例が多く興味深い。
以下はきゅうりの画像から等級(ラベル)を求めるというAI課題に取り組んだもの。
元組み込みエンジニアの農家が挑む「きゅうり選別AI」 試作機3台、2年間の軌跡
https://www.itmedia.co.jp/enterprise/articles/1803/12/news035.html

2. 物体検出(Object Detection)
【AIが答える質問】
「画像の中で、どの範囲に何が写っているか?」
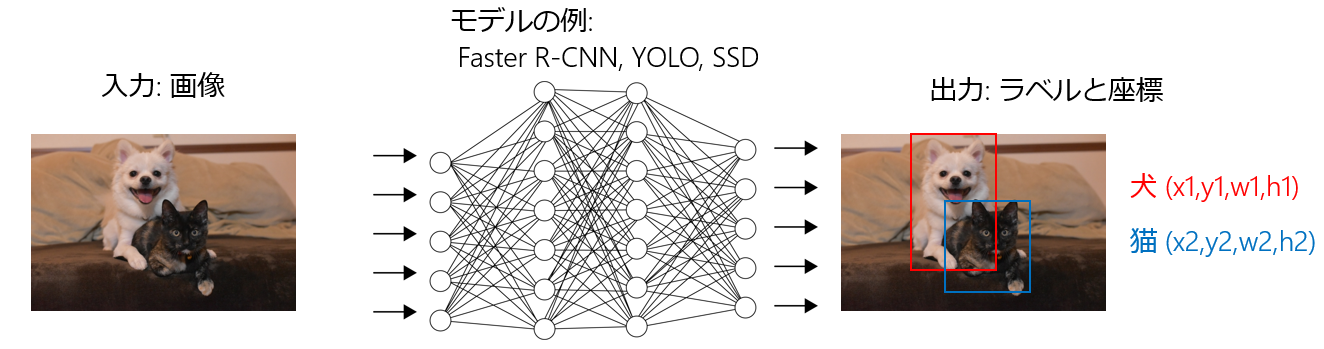
画像分類問題では、1枚の写真に複数の対象が写っていると認識できなかった。
物体検出であれば、画像内の複数の異なるオブジェクトを認識し、それぞれの位置座標も含めて予測できる。
【モデルの例】
Faster R-CNN, YOLO, SSDなど。
【学習に利用できるデータセットの例】
PASCAL VOCなど。画像に対して、物体の位置とラベルが付与されている。
http://host.robots.ox.ac.uk/pascal/VOC/

【実用例】
与えられた画像の中で、位置座標や大きさも含めて予測したい場合に使われる。
以下は東急電鉄の事例だが、「線路の領域に人が存在する」という状態を検知して通知を出すようになっている。
駅構内カメラを活用した「転落検知支援システム」の運用開始
https://www.tokyu.co.jp/image/news/pdf/20180808.pdf

3. セグメンテーション(Semantic Segmentation)
【AIが答える質問】
「画像の各ピクセルには、それぞれ何が写っているか」
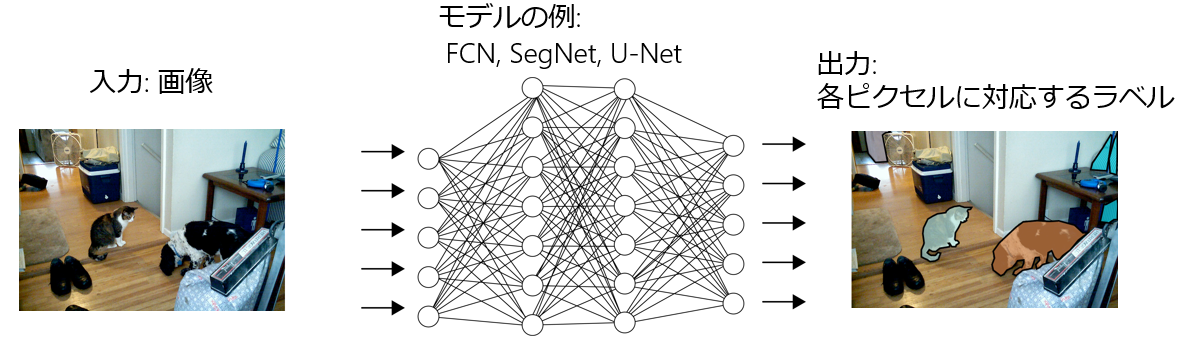
物体検出問題では、オブジェクトの位置はバウンディングボックスと呼ばれる矩形(長方形)で特定していた。一方で、画像の中の検出したいオブジェクトは実際には長方形とは限らず、様々な形をしている場合がある。セグメンテーションタスクでは、ピクセルの単位でラベル付けをすることによってオブジェクトの位置をより詳細に予測できる。
【モデルの例】
FCN, SegNet, U-NETなど。
【学習に利用できるデータセットの例】
MS COCOなど。
https://cocodataset.org

【実用例】
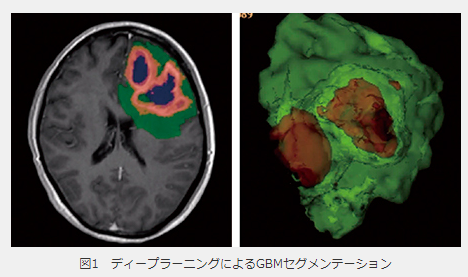
MRI画像から腫瘍の位置を特定するとき、切除すべき部位を特定するためには、腫瘍の正確な位置を知る必要がある。画像検出では矩形を使った大まかな位置までしか予測できないが、セマンティックセグメンテーションを適用すれば画像のピクセル単位で正確な位置を予測することができる。
深層学習を活用した脳腫瘍セグメンテーションへの取り組み
https://www.innervision.co.jp/sp/ad/suite/philips/technical_notes/190793
4. 画像生成(Image Generation)
【AIが答える質問】
「本物っぽいリアルな画像を作って」
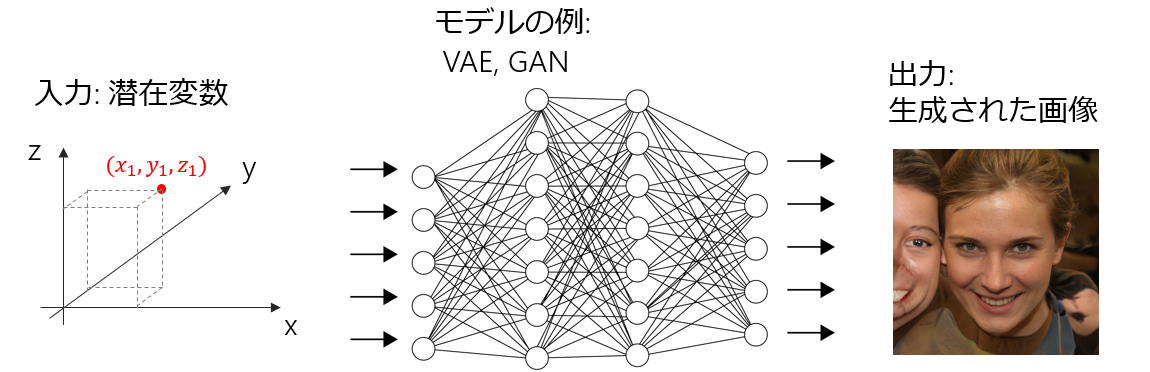
ここまでとはだいぶ毛色が異なるが、画像生成では与えた潜在変数(シード)から画像を生成する。上の図では理解がしやすいように潜在変数を3次元にしたが、実際にはもっと高次元の潜在変数を使う。これが高次元であるほど表現力が高まり、よりバリエーションに富んだ画像が生成できるようになる。
【モデルの例】
Variational AutoEncoder(VAE), Generative Adversarial Network(GAN)など。
(GANと一口に言ってもDCGAN, LAPGAN, infoGAN, ConditionalGANなど色々ある)
【学習に利用できるデータセットの例】
画像生成問題の場合には、教師データとしてラベルを付与したデータセットを準備する必要はない。GANについての詳しい説明はここでは省略するが、集めてきた画像(ラベル無し)が正解集合となり生成された画像が不正解集合となる。
【実用例】
画像生成モデルについては、やはりエンターテイメント系の事例がほとんど。
実在しないアイドル画像も瞬時に生成するAI「GAN」が賢すぎる!
https://gendai.ismedia.jp/articles/-/63615

「thispersondoesnotexist」というサイトでは、URLにアクセスする度にランダムに作られた潜在変数(シード)を基に、GANを使って顔写真が自動生成される。たまにバグったような顔写真もあるが、ほとんどは本物と見分けがつかないレベル。
https://thispersondoesnotexist.com/
5. マルチモーダル問題(Multimodal)
【AIが答える質問(画像キャプションの例)】
「画像に写っているものを日本語の文章で説明して」
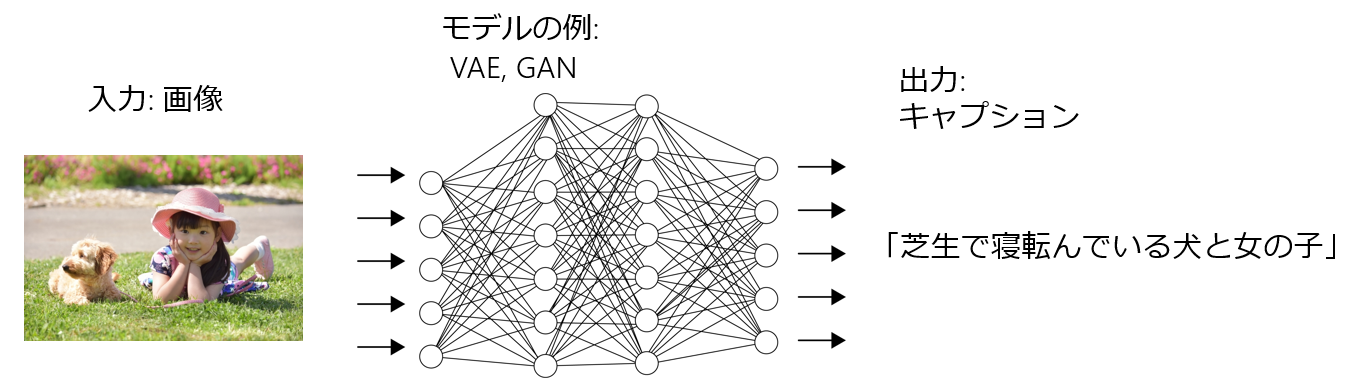
画像だけではなく自然言語処理も扱う複合問題。
【モデルの例】
Neural Image Caption(NIC)
画像を特徴ベクトルにEncodeするためのCNNと、キャプションをDecodeするためのLSTMからなる。PyTorchでの実装も公開されている。
https://github.com/yunjey/pytorch-tutorial/tree/master/tutorials/03-advanced/image_captioning
【学習に利用できるデータセットの例】
Flickr30k dataset。31,783枚の画像に対して5つずつキャプションが付与されている。
https://www.kaggle.com/hsankesara/flickr-image-dataset
日本語であればSTAIR Captions。164,062枚の画像に対して5つずつキャプションが付与されている。
STAIR Captions
http://captions.stair.center/explore/

【実用例】
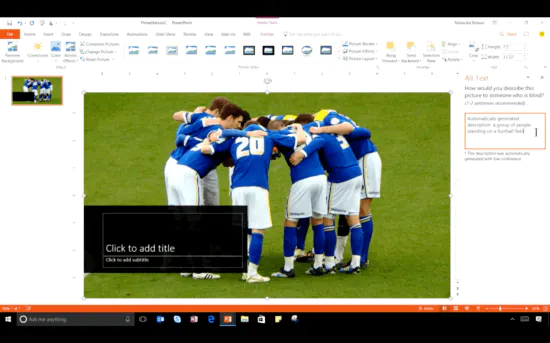
あまり知られていないが、写真に対する説明文を自動的に付与する機能をMicrosoftが実装済。WordやPower Point上ですぐに試すことができる。
ワードにAI 視覚障害者向け写真説明を自動生成(日経新聞)
https://www.nikkei.com/article/DGXMZO10423140Y6A201C1000000
ステップ2.画像分類を実装してみる
上記で整理した5つの課題の中でどこから着手するかだが、まずは画像分類問題から着手するのが良い。興味の強いところから勉強を始めても良いが、いきなり画像生成やマルチモーダル課題から始めてもおそらく挫折する。
画像分類問題を解いてみるとは言っても、はじめはどこから手を付けたらよいか右も左も分からない状態。なので、まずはハンズオンでの実装をしてみるのが始めやすい。Udemyのハンズオン講座が良かった。
Udemyのハンズオン講座の受講
ハンズオン講座を受講してとりあえず動くものを作ってみる。私が受講したのは以下のUdemyコース。
【Hands Onで学ぶ】PyTorchによる深層学習入門
https://www.udemy.com/course/hands-on-pytorch/
5時間のオンデマンドビデオだが、私にとってはかなり良い内容で、章によっては3周くらい繰り返して完全に内容を理解するようにした。良かったのは以下の点。
1. 画像AIのモデルをとりあえず動かしてみる経験ができる
本記事で紹介した5つの画像AI課題のうちの1つ、画像分類問題をResNetで実装できる。ハンズオン形式で一つずつ進めていくので、時間をかければ確実にモデルが実装できる。ついていけなければ、巻き戻して何度でも見ればよい。一度モデルが構築できさえすれば、後は部分的にいじったりしながら理解を深めていけば良いため、「一旦動くものを作るところまでを何とかたどり着く」というのがとても大事。
2. Google Colaboratoryで完結するため、環境構築で躓かない
Google ColaboratoryはGoogleがWebベースで提供している開発環境で、GPUも含め無償で利用できる。ローカル環境の環境設定が不要なので、講師と同じ環境がすぐにできる。ローカル環境の構築などで躓くとかなりモチベーションが下がるため、はじめての実装はGoogle Colaboratoryを前提にしているハンズオン講座が良い。
3. 質問に対して講師からすぐに回答がある
Udemyでは講師に対して質問できる掲示板のようなものが用意されており、受講生は講師に対して質問できる。私自身、一部講義内容で理解できない部分があったため質問したが、数時間で回答が返ってきたのは驚いた。その後何度かやり取りをさせていただき、疑問を解決できた。
宣伝のようになってしまったが、別に講師の方が知り合いとかではない。念のため。上記に当てはまるようなハンズオン講座であれば、もちろん他のものでも良いし、書籍でも同様のコンセプト(Google Colaboratory前提で画像AIのハンズオン)のものはあると思う。
ステップ3.理論をフォローアップする
本業で取り組んでいるわけではない分、社内外を問わず勉強できる機会を見つけて取り組んだ。書籍などの教材も良質なものが多いので独学も無理ではないが、一人で続けるのはモチベーションの維持が難しい。勉強会などで仲間を作って頑張るか、資格なりプログラムなりなんでも良いので勉強することが習慣化できる仕組みに乗っかってしまうのが良い。
勉強会(技術書輪読会)の開催
まずは社内で機械学習/ディープラーニングに興味のある人を集めて勉強会を主催した。形式としては技術書の輪読会で、毎回発表担当を決めて順番に発表して議論した。書籍代を会社に出してもらったり上長に認知してもらったりすることで、**モチベーションが下がっても続けられる(続けなくてはいけない)**ようにした。
理論面については特に、学んだことを説明する過程で理解不足な点に気づいたりする。発表する人が一番勉強になるのは間違いない。勉強会の参加者に詳しい人がいないために、誰も答えを持っておらずに全員で考え込んでしまうこともあったが、まぁそれはそれで良かったと思う。アウトプット大事。
社内での開催が難しい場合はconnpassなどを使って勉強会を主催/参加しても良いと思う。ただその場合は気合をしっかり入れないとモチベーションが保てない。私は挫折した。
https://connpass.com/dashboard/
ディープラーニング協会(JDLA)のE資格取得
2020年1月に実施されたE資格を受験。資格試験は良い目標になるし、カリキュラムができているので勉強が進めやすかった。受験に向けてJDLAの認定講座を提供している「SkillUpAI」の講座を受講したが、これも講師のレベルが高く良かった。
合格した後はCDLE(Community of Deep Learning Evangelists)という、G検定またはE資格の合格者だけが参加できる勉強会にも何度か参加した。自社内に一緒に勉強できる仲間がいない場合など、うまく活用すると良いかもしれない。
ちなみにE資格の出題範囲はディープラーニングだけではなく数学や(従来の)機械学習まで含むため、結果的に広範囲の勉強をすることになった。E資格の出題範囲(シラバス)は次の通り。
一般社団法人 日本ディープラーニング協会 E資格とは
https://www.jdla.org/certificate/engineer/
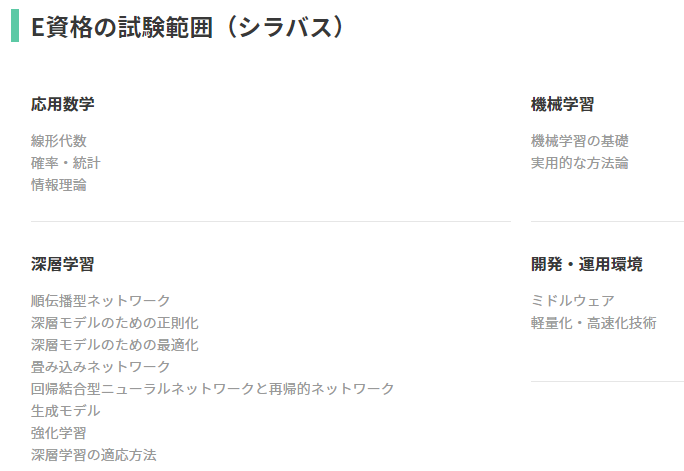
ディープラーニングについてはSkillUpAIの講座でカバー、機械学習については以下の書籍で一通り学習した。
Python機械学習プログラミング 達人データサイエンティストによる理論と実践
https://book.impress.co.jp/books/1120101017
※ 当時はまだ第二版だった
ステップ4. 実装の経験を積む
ここまでで準備は整ったので、あとは実践の経験を積んでいく。実務で取り組める課題があれば理想だが、タイムリーに筋のよい問題を見つけることは難しいし、何より必要なデータが揃っていることは少ない。
実務を考えればモデル開発の前工程/後工程が重要であることは間違いないが、(実装ができる)AIエンジニアとしての学習効率の観点で言えば、下図の濃い紫部分のスプリントを回すのが現実的。コンペ等、既にAI課題として定式化された練習問題を解くことで経験を積む。
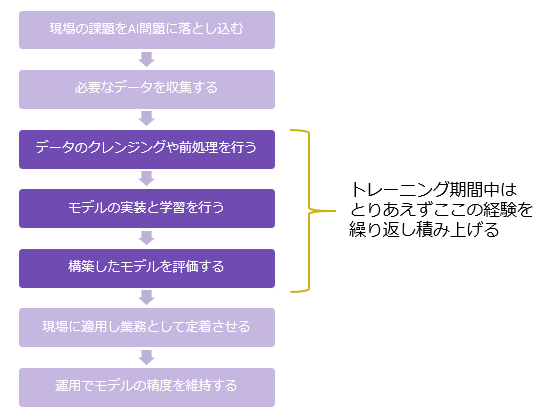
データ分析コンペに参加
データ分析コンペはKaggleやSignateが有名だが、試しにSignateの課題に取り組んでみた。構造化データ(テーブル形式)が多い印象だったが、画像系のコンペも多かった。
SignateにはBegineer限定コンペというのがあり、取り組みやすい課題が用意されている。Beginner限定コンペはベテランは参加できないため、初心者でも高い順位が狙いやすくモチベーションが上がる。
最近開催されているSignateの画像系のコンペ
・ひろしまQuest2020:画像データを使ったレモンの外観分類 -> 画像分類
https://signate.jp/competitions/362
・漁業×AIチャレンジ: 魚群検知アルゴリズムの作成 -> 物体検出
https://signate.jp/competitions/403
・オフロード画像のセグメンテーションチャレンジ -> セグメンテーション
https://signate.jp/competitions/101
公開済みAIモデルソースコードの実行
データ分析コンペに取り組む際のモデルの実装は、いきなりフルスクラッチで開発するのはハードルが高い。したがって既存のソースコードをベースに改変する形で進めることになると思う。
公開済みのAIモデルのソースコードの見つけ方としては「paperwithcode」というサイトが使い易かった。paperwithcodeでは、課題ごとにState-of-the-Art(最先端)のモデルが紹介されており、そのモデルに対応する論文やGitHub上の公開ソースコードへのリンクも貼られている。
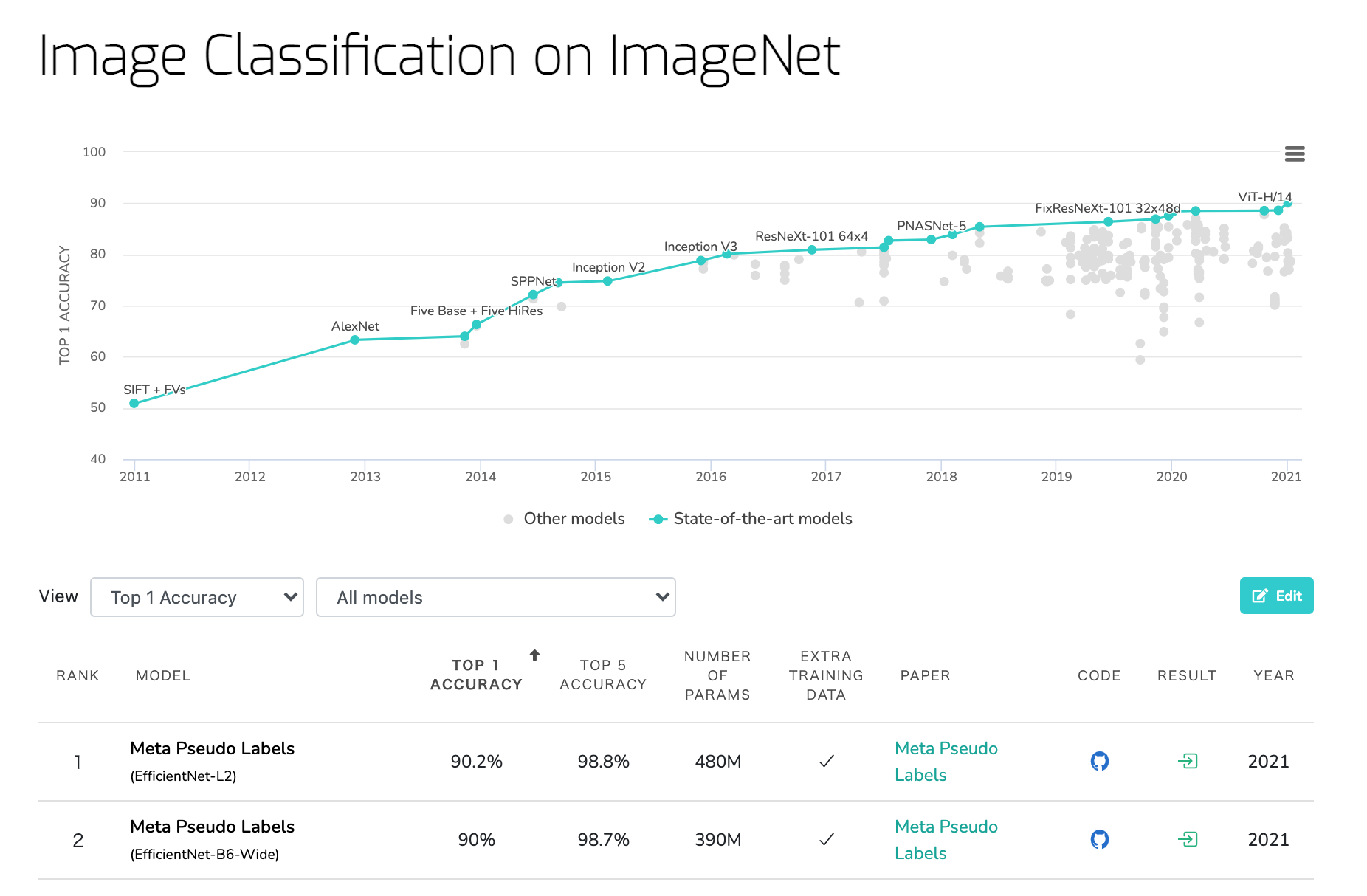
例えばImageNetのデータセットを使った画像分類の問題であれば、現在のSoTA(State-of-the-Art)のモデルはEfficientNet-L2を使ったものであるということが分かる。ここのリンクから論文をみたり、GitHubからそのソースコードを入手して動かしてみたりすることで相当力がつくはず。
Image Classification on ImageNet(paperwithcode)
https://paperswithcode.com/sota/image-classification-on-imagenet
AI Quest(経済産業省主催のAI人材育成プログラム)に参加
経済産業省が「課題解決型AI人材育成」というコンセプトで実施している無償のプログラム「AI Quest」に参加。プログラムの一部がコンペ形式になっていたり、他の参加者と議論できる場が用意されていたりと工夫されていた。
プログラムの特徴としては、上の図でいう薄紫の部分(モデル開発の前後)にも重点を置いた内容。例えば、経営層に向けたAIプロジェクトの提案プレゼンの演習などもプログラムに含まれる。KaggleやSignateといったデータ分析コンペと比較して、より実務を意識した内容になっている。
今後毎年実施される見込み。
AI Quest 課題解決型AI人材育成 - Signate
https://lp.signate.jp/ai-quest/
まとめ
何を学ぶときも共通するが、トップダウン的な学び方とボトムアップ的な学び方を組み合わせることになると思う。
まずは「トップダウン的に」全体像をつかむ
「AIを学ぼう」と思うとどこから手をつけて良いか分からなかったり、学ぶべきことが膨大すぎて心が折れる。AIという広い領域の中で迷子にならないように、初めは全体像をつかむところから始めて、少しずつディテールに落としていった方が良い。
いきなり統計学の勉強を始めて楽しさを見いだせる人もいるが、私はそういうタイプではなかった。自分の現在地が分かるように、初めに地図を手に入れる(全体像を理解する)方がいい。
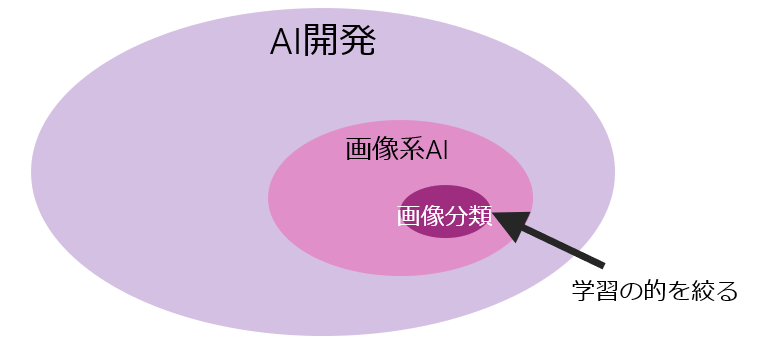
次に範囲を絞って「ボトムアップ的に」学ぶ
逆に学習を進めるときは全てをカバーしようとするのではなく、範囲をできるだけ絞る。特定の問題(例えばAI開発でも画像系AIでもなく「画像分類」)に限定して解けるようにしばらく頑張ってみる。
特定の問題を解けるようになれば、ちょっとでもAIエンジニアになったような気分を味わえるし、次の問題にも自然と手が伸びるようになるはず。小さな成功体験が大事。
おわりに
偉そうに色々と書き連ねましたが、私自身ど素人です。今後も色々な学習の機会を見つけて、地道にできることを増やしていきたいと思っています。記事内容の訂正やアドバイスなど、ありましたらよろしくお願いします。