今回作るプログラム
英語の記事など、英語の文章を読み込み、名詞、形容詞、動詞などを抽出して、単語帳を自動作成するというプログラム。
英語学習をしている中で、単語リストを作るのがめんどくさかったw
参考記事
NLTKの使い方をいろいろ調べてみた
https://qiita.com/m__k/items/ffd3b7774f2fde1083fa
【Python】googletransを使って、日本語のデータを英語に変換(翻訳)してみる
https://96lovefootball.hatenablog.com/entry/2019/02/10/213000
具対的なフローを書くと。。。
1.インターネットから、対象の記事を、data.txtにコピペする
今回は、以下から取得
https://en.wikipedia.org/wiki/Coronavirus
Coronaviruses are a group of related RNA viruses that cause diseases in mammals and birds. In humans, these viruses cause respiratory tract infections that can range from mild to lethal. Mild illnesses include some cases of the common cold (which is caused also by certain other viruses, predominantly rhinoviruses), while more lethal varieties can cause SARS, MERS, and COVID-19. Symptoms in other species vary: in chickens, they cause an upper respiratory tract disease, while in cows and pigs they cause diarrhea. There are as yet no vaccines or antiviral drugs to prevent or treat human coronavirus infections.
Coronaviruses constitute the subfamily Orthocoronavirinae, in the family Coronaviridae, order Nidovirales, and realm Riboviria.[5][6] They are enveloped viruses with a positive-sense single-stranded RNA genome and a nucleocapsid of helical symmetry.[7] This is wrapped in a icosahedral protein shell.[8] The genome size of coronaviruses ranges from approximately 26 to 32 kilobases, one of the largest among RNA viruses.[9] They have characteristic club-shaped spikes that project from their surface, which in electron micrographs create an image reminiscent of the solar corona, from which their name derives.
2.ファイルを読み込む
data = open("./data.txt", "r")
lines = data.read()
3.上記で取得した文字列を、分かち書き
今回使用するライブラリ - nltk(word_tokenize)
まずは、インストール
pip install nltk
こちら、まず機能をダウンロードしないといけない
機能ごとにダウンロードできるが、自分はめんどくさいので、全てダウンロードしました〜
3Gくらいあるので、SSDの容量厳しい方はご注意を。。。
pythonのコンソールに入って、以下を実行
python3.7
nltk.download('all')
以下のコードで分かち書き
import nltk
Splittedarticle = nltk.word_tokenize(article)
4.分かち書きした文字列から、品詞を取得
今回使用するライブラリ - nltk(pos_tag)
pos = nltk.pos_tag(Splittedarticle)
5.取得した品詞から、名詞、動詞、形容詞のみを抽出
pos = nltk.pos_tag(Splittedarticle)
wordList = []
for p in pos:
if p[1] in wc and p[0] not in wordRemoved:
wordList.append(p[0])
wc, wordRemovedの定義は以下
こちらは、nltkの仕様上、wordRemovedは[]が単語として取得されてしまう?という問題があったため、追加。
覚えた単語、除きたい単語などあった場合にも使用できます
wcは、word class(品詞)の略で、nltkでは、品詞タグを指定して、対象の品詞を取得します。
wc = ['NN', 'JJ', 'VB']
wordRemoved = ['[', ']']
品詞タグは以下です。
| 品詞タグ | 品詞名(英語) | 品詞名(日本語) |
|---|---|---|
| CC | Coordinating conjunction | 調整接続詞 |
| CD | Cardinal number | 基数 |
| DT | Determiner | 限定詞 |
| EX | Existential there | 存在を表す there |
| FW | Foreign word | 外国語 |
| IN | Preposition or subordinating conjunction | 前置詞または従属接続詞 |
| JJ | Adjective | 形容詞 |
| JJR | Adjective, comparative | 形容詞 (比較級) |
| JJS | Adjective, superlative | 形容詞 (最上級) |
| LS | List item marker | - |
| MD | Modal | 法 |
| NN | Noun, singular or mass | 名詞 |
| NNS | Noun, plural | 名詞 (複数形) |
| NNP | Proper noun, singular | 固有名詞 |
| NNPS | Proper noun, plural | 固有名詞 (複数形) |
| PDT | Predeterminer | 前限定辞 |
| POS | Possessive ending | 所有格の終わり |
| PRP | Personal pronoun | 人称代名詞 (PP) |
| PRP$ | Possessive pronoun | 所有代名詞 (PP$) |
| RB | Adverb | 副詞 |
| RBR | Adverb, comparative | 副詞 (比較級) |
| RBS | Adverb, superlative | 副詞 (最上級) |
| RP | Particle | 不変化詞 |
| SYM | Symbol | 記号 |
| TO | to | 前置詞 to |
| UH | Interjection | 感嘆詞 |
| VB | Verb, base form | 動詞 (原形) |
| VBD | Verb, past tense | 動詞 (過去形) |
| VBG | Verb, gerund or present participle | 動詞 (動名詞または現在分詞) |
| VBN | Verb, past participle | 動詞 (過去分詞) |
| VBP | Verb, non-3rd person singular present | 動詞 (三人称単数以外の現在形) |
| VBZ | Verb, 3rd person singular present | 動詞 (三人称単数の現在形) |
| WDT | Wh-determiner | Wh 限定詞 |
| WP | Wh-pronoun | Wh 代名詞 |
| WP$ | Possessive wh-pronoun | 所有 Wh 代名詞 |
| WRB | Wh-adverb | Wh 副詞 |
6.取得したワードを、googletransを用いて、翻訳
今回使用するライブラリ - googletrans
まずは、インストール
pip install googletrans
変換元の言語はsrc、変換先の言語はdestで指定します
translator = Translator()
transToja = translator.translate(word, src='de', dest='ja')
7.作成したデータを、表形式でファイルに出力
今回使用するライブラリ - pandas
まずは、インストール
pip install pandas
col変数で、表のヘッダーを指定
pd.DataFrameの引数に、wordBook(上記で作成した2次元配列), columns=col(ヘッダー)を指定して、DataFrameを生成し、to_csvでcsv形式で表を出力
import pandas as pd
col = ['Japanese', 'English']
df = pd.DataFrame(wordBook, columns=col)
df.to_csv('./wordBook.csv')
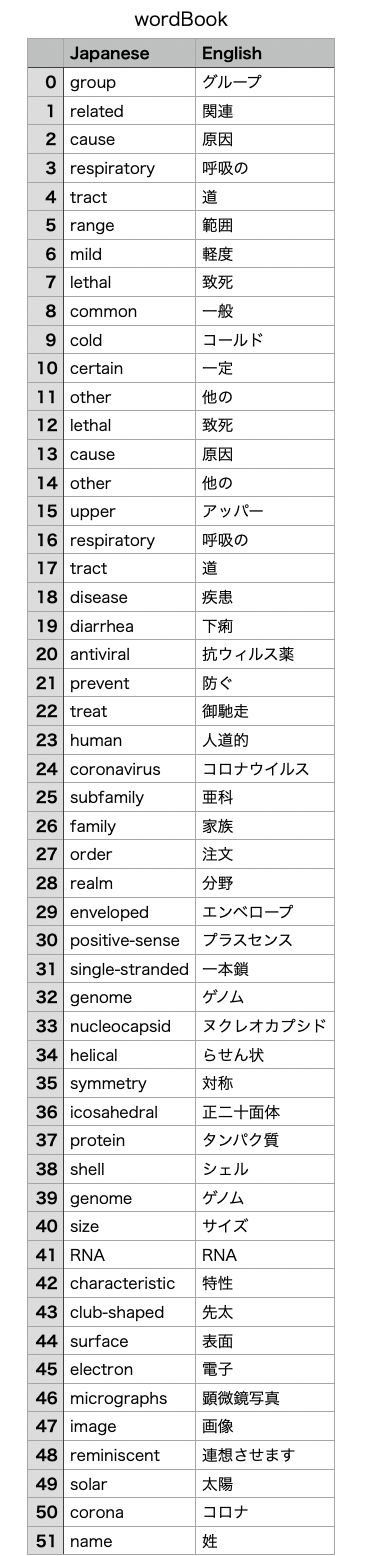
完成した単語帳
全体のソース
import nltk
from googletrans import Translator
import pandas as pd
def takeWordInWc(article):
SplittedArticled = nltk.word_tokenize(article)
pos = nltk.pos_tag(SplittedArticled)
wordList = []
for p in pos:
if p[1] in wc and p[0] not in wordRemoved:
wordList.append(p[0])
return wordList
def translate(wordList):
wordBook = []
for w in wordList:
translator = Translator()
transToja = translator.translate(w, src='de', dest='ja')
if transToja.text != 'None':
wordBook.append([w, transToja.text])
return wordBook
wc = ['NN', 'JJ', 'VB']
wordRemoved = ['[', ']']
data = open("./data.txt", "r")
lines = data.read()
wordList = takeWordInWc(lines)
wordBook = translate(wordList)
col = ['Japanese', 'English']
df = pd.DataFrame(wordBook, columns=col)
df.to_csv('./wordBook.csv')
data.close()