経緯
機械学習プロフェッショナルシリーズの画像認識を読んでから実際にCNNのコードを書くと、特に説明がなかったのにも関わらず、すんなりと理解できたので、共有できればなと思ったからです。
そもそも画像認識とは
画像の中から、人や動物、文字や物体の形状を認識する技術です。
また、画像認識は物体認識とシーン認識に分けられ、物体認識はさらにインスタンス認識とクラス認識に分けられます。
画像認識
├─物体認識
│ ├─インスタンス認識
│ └─クラス認識
└─シーン認識
物体認識:入力画像に写る物体を認識し、適切なラベルをつけること。
シーン認識:複数の物体が写り、意味のなす状況を表現したもの。
インスタンス認識:レインボーブリッジの画像が入力されたとき、「橋」と出力するのではなく、「レインボーブリッジ」として出力するもの。
クラス認識:レインボーブリッジの画像が入力されたとき、「橋」と出力すること。入力画像の物体の属する概念を予測するもの。
画像認識のキーワード
画像認識にはいくつかの重要な処理があります。それを順に説明します。
局所特徴抽出
画像中の点やエッジなどの特徴の周りの画素値や微分値をベクトルにして抽出したもの。
統計的特徴抽出
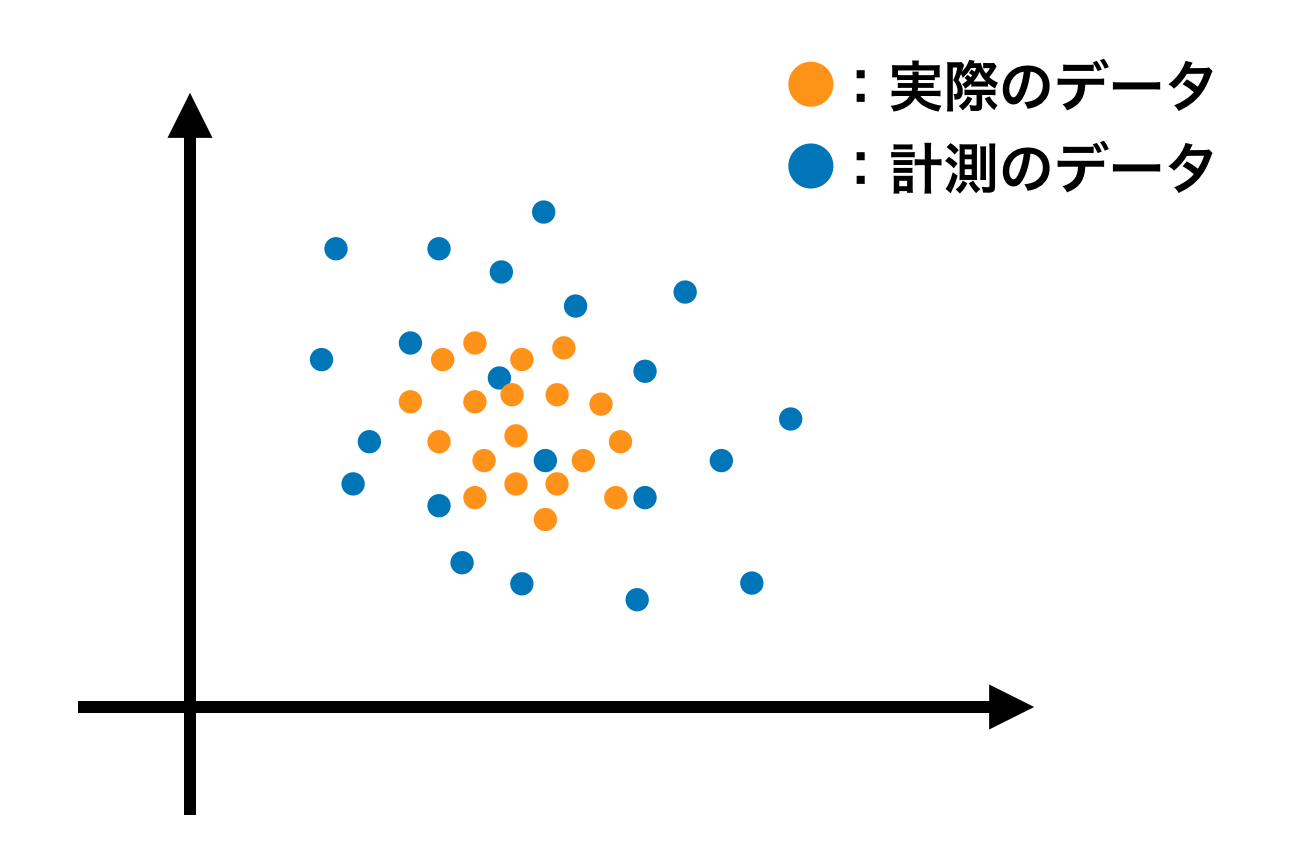
計測されたデータはノイズを含んでいたり外乱を受けたりするので、計測データは実際のデータの周りに分布してしまいます。そこで、計測したデータの確率統計的な構造に基づいてさらに特徴抽出を行うことで、ノイズや外乱の影響を受けにくい頑健な特徴に変換させること。
コーディング
画像中の局所特徴を認識に有効な次元数のベクトルに変換すること。
プーリング
画像中に存在する複数のコーディング後の特徴ベクトルを、1本のベクトルにまとめること。
深層学習
局所特徴抽出、統計的特徴抽出、コーディングやプーリングを多段に重ねた構造を深い構造という。この深い構造を入力から出力までで学習することを深層学習といいます。
メリット:
深層学習を利用することで、前述した局所特徴抽出やコーディング手法に詳しくなくても、入力データに対して望ましい出力を予測するシステムの構築が可能になる。
デメリット:
適切なネットワーク構造の設計やパラメータの学習が難しい。
必要とする訓練データ量が増え、計算コストが大きくなる。
計算途中がブラックボックス化することより、他人に説明することが難しい。
畳み込みニューラルネットワーク
あるユニットが隣の層の全てのユニットと結合しているネットワーク層を全結合層といいます。
しかし、サイズの大きい画像に適用するとネットワークに含まれるパラメーター数が膨大となり、学習させるのが難しくなります。
そこで、画像特有の性質を利用します。
ある画素と近い画素どうしは強い関係を持ち、距離が離れると関係性は弱くなるという性質を利用して制約をかけます。そうするとことで、パラメーター数を大幅に減らし、学習をしやすくすることができます。
この、上層の近隣に存在するユニット群だけと結合している局所領域を局所的受容野といいます。
また、画像のどの領域でも有効な特徴は、重み共有を行う。重み共有によってさらにパラメータ数を減らすことができます。
画像の空間的特性を活かすためにユニットは平面状に並べられる。このようなユニット群を特徴マップと呼ぶ。この入力画像にカーネルを適用して特徴マップを得ることは、入力画像にカーネルを畳み込み演算することと等価になります。このような局所受容野と重み共有の特性を持つ層を畳み込み層といいます。
コードだと
・特徴抽出
model.add(Conv2D(16, (3, 3), padding='same', input_shape=(28, 28, 1))
Conv2Dのクラスでを使い画像から特長を抽出します。
16種類の3×3のカーネルを入力データにかけ、16枚の出力データを得る。
・活性化関数
model.add(Activation='relu')
正のところはそのまま出力して、負のところは0にして出力するRelu関数。
・プーリング層
model.add(MaxPooling2D(pool_size=(2, 2)))
2×2一番大きい値を取り出し、より特徴を際立たせることができます。
・過学習の対策
model.add(Dropout(0.5))
50%を捨ててデータの偏りをなくす。
・全結合層
model.add(Dense(512)
全結合をし、出力を512個にする。
model.add(Dense(3, activation=’softmax’)
最後の出力層で最終的な出力数を決める。(私の場合は、3つでした。)
ソフトマックス関数を使って、それぞれの出力の予測確率を合計すると1になるという風に変換をする。
(ex.クラスが3つの場合(0, 9, 1)で[0]の確率が0%、[1]は90%、[2]は10%となる。)
最後に
機械学習プロフェッショナルシリーズの画像認識は、画像認識で使われる有名なフィルターや分類器をほとんどのページを使って紹介しているます。画像認識やディープラーニングについて全く知らない方や、数学が苦手な方は読むのが難しいかなと思いました。
私も、たくさん勉強してからまた読みたいと思います。