前回までは属性に対しての解析だったので今度は画像を分類わけしてみることにした。
といっても、右も左もわからない状態がどうやって進んだのか?という参考になればという程度のメモである。
犬猫
試してみたのはこっちのコンペのデータ
https://www.kaggle.com/c/dogs-vs-cats
犬か猫かを分類しようぜというやつだ。
データ確認
DLしながらデータセットの中身を確認
The training archive contains 25,000 images of dogs and cats. Train your algorithm on these files and predict the labels for test1.zip (1 = dog, 0 = cat).
といっても、データを確認するも何もない。
画像を犬(1)か猫(0)に分類しろってだけな模様。
どこから手を付ければよい?
が、とっかかかりがさっぱりわからない。
画像を認識しようと思ったら、Kerasを使うのが一般的なのか?
とりあえずググってみた
いくつかググってみた現時点の自分にわかりやすかったのが以下
https://qiita.com/wtnb93/items/65633bcbe2942b440128
http://blog.asial.co.jp/1502
雰囲気としては、
対象となる画像のサイズを合わせ、
それをベクトルにして読み込む
といった感じか。
とりあえずやってみる
こんな感じでファイルを読み込んでデータセットを作成
def get_data_and_label(image_path):
labels = []
datas = []
files = []
for path in os.listdir(image_path):
if 'dog' in path:
labels.append(1)
else:
labels.append(0)
feature = data.imread(f'{image_path}/{path}')
feature = transform.resize(feature, (100, 100), mode='reflect')
datas.append(convert_image(feature))
files.append(path)
return datas, labels,files
RGBの画像を一次元にする処理はこんな感じ
def convert_image(img):
dim = img.shape[0] * img.shape[1] * img.shape[2]
img_vector = img.reshape(1, dim)
return img_vector[0]
あとは前回作成していた各モデルの生成処理に食わせてあげればなんとなくできそう。
いきなり全部やるのは無理な話だと思ったので100枚ずつでやってみた。
結果
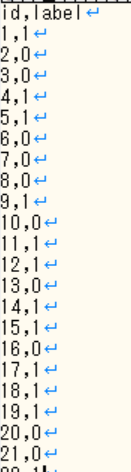
なんとなくできてる感はある。
※実際はファイルの番号(IDに対応)とデータのソート順が合ってなくてできてなかったのだが。。
本当はグリッドサーチだったりいくつかの手法で試してみたかったのだが、あほみたいに時間がかかりそうだったので、適当なパラメータでPerceptronとRandom Forestだけで試してみることにした。
あと、何回もモデル作成を試せないので以下を作って、一回作ったモデルを保存できるようにした。
def save_model(model):
from sklearn.externals import joblib
filename = 'finalized_model.sav'
joblib.dump(model, filename)
全部でやってみる
全部読み込ませてやってみたら、データ読み込みだけで20分ぐらい

これいつ終わるんだ・・・
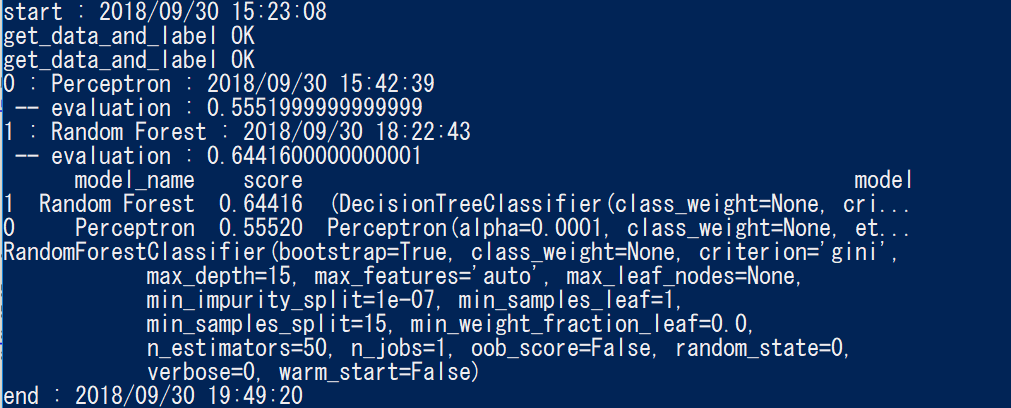
Random Forestは意外に早く終わった。
とりあえずできあがり?
で、できあがったのでSubmitしてみようかと思ったのだが、このコンペはオープンではなかったので投稿できなかった。
通りでサンプルと試しているのが全く見当たらないわけだ。
https://www.kaggle.com/c/digit-recognizer
こっちでやってみるべきだったのかもしれない。
なんとなくわかったこと
なんとなくのやり方はわかったような気がする。
・画像を読み込み一枚ずつ1次元のベクトルにする
・それに対するラベルをつける
・モデルを作成する
・推定させる
ただこれだと特徴量もくそもない気がするのだが、どうするんだろう?
単純にTrainデータを増やすのか?
あとから気が付いたが、せっかく作ったモデルで何もためしてないや。