#目次
・藤崎モデルのパラメータ逆推定をやってみる
・パラメータ逆推定
・実装
- ①前処理
- ②アクセント成分の近似
- ③フレーズ成分の近似
- ④AbS最適化
- ⑤結果
- ⑥事後処理も
・おまけ
藤崎モデルのパラメータ逆推定をやってみる
\begin{align}
\log F_0[t] &= F_b + F_p[t] + F_a[t] \\
&= F_b + \sum_i Ap_iG_p(t - T_{0i}) + \sum_j Aa_j\{G_a(t - T_{1j}) - G_a(t - T_{2j})\} \\
G_p(t) &= \alpha^2 t \exp(-\alpha t) \hspace{10pt} (t \geqq 0,\hspace{5pt} else\ 0) \\
G_a(t) &= \rm{min}[1 - (1 + \beta t)\exp(-\beta t),\ \gamma] \hspace{10pt} (t \geqq 0,\hspace{5pt} else\ 0)
\end{align}
のように、基底成分$F_b$、フレーズ成分$F_p$、アクセント成分$F_a$の3つの和でモデル化可能。これが藤崎モデル(超ザックリ)。
フレーズ成分
こいつは発声してから緩やかに減衰していく成分。
$G_p(t)$はインパルス応答で、$T_{0i}$は$i$番目のフレーズ成分の生起時刻、$A_{pi}$は$i$番目のフレーズ成分の振幅を表す。
$\alpha$はフレーズ成分の固有各周波数で、話者や言語の違いによる差が小さいとされており$\alpha = 3\rm{rad/s}$で定義される。
アクセント成分
こいつは急峻な増減成分を担う。。
$G_a(t)$はステップ応答で、$T_{1j}$と$T_{2j}$、$A_{aj}$はそれぞれ$j$番目のアクセント成分の生起時刻、終わり時刻、振幅に対応する。
$\beta$はアクセント成分の固有各周波数でこちらも話者・言語によらず$\beta = 20\rm{rad/s}$に。
$\gamma$は同様に$\gamma = 0.9$で。
パラメータ逆推定
藤崎モデルがパラメータから音声の基本周波数を生成する順問題なので、音声の基本周波数からパラメータを逆推定する逆問題を解く。
これができると・・・
- 基本周波数を少数のパラメータで表現できる
- 基本周波数の加工・操作が容易になる
というメリットがある。
ただ、当然だけど逆問題は簡単じゃない。
しかも詳しく提案法が書かれてる論文を最近はあまり見かけないな〜という感じ(たぶん)。
今回は20年くらい前の論文だけど、この辺を再現できればな〜っていう感じ。
(A METHOD FOR AUTOMATIC EXTRACTION OF MODEL PARAMETERS
FROM FUNDAMENTAL FREQUENCY CONTOURS OF SPEECH)
大まかな流れ
※ 発話区間毎に
① 前処理:抽出したF0のグロスエラーを直し、マイクロプロソディを除去し、無声区間を補間して、平滑化する。
② アクセント成分の近似
③ フレーズ成分の近似
④ Analysis-by-Synthesisで各パラメータの最適化
っていう感じ。
①前処理
世間の提案法とは違って
- F0抽出は、WORLDのHARVESTから抽出後、STONE MASKを適用して得たものとする
- マイクロプロソディはローパスフィルタによって除去する
ことにしてる。
WORLD信者なのでF0はWORLDで抽出したいし、そうすると抽出過程の情報を用いてマイクロプロソディとかを除去するという論文の手法を使えないからっていうだけの理由。
ちなみにWORLD信者なので(2回目)、抽出したF0は高精度だと信用しきってるため、「グロスエラー?何それ?」の如く
前処理から省いてまーす。
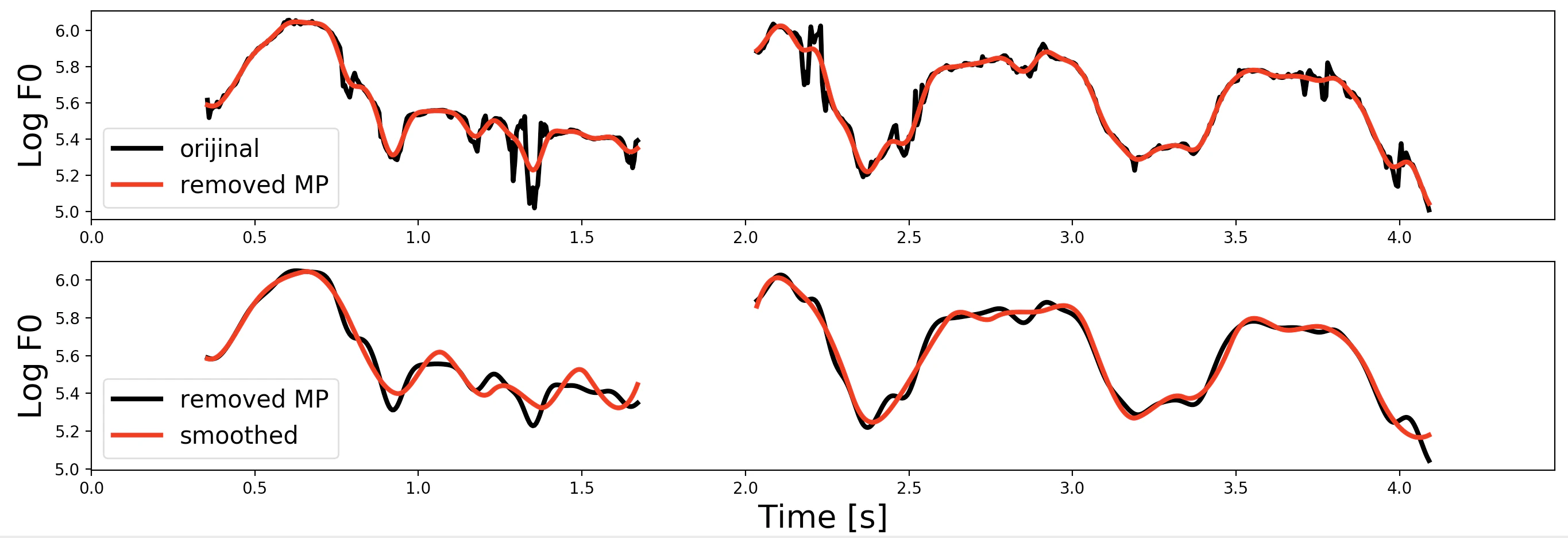
前処理[1] マイクロプロソディの除去
マイクロプロソディは急峻なF0変化のことで、F0軌跡の高周波成分に該当する。
なのでカットオフ周波数10Hzのローパスフィルタで除去する。
(「マイクロプロソディ ローパスフィルタ」でググればいくつか論文出てきます。はい。)
def remove_mp(f0, period, n_taps=51, cutoff=10):
padd1, padd2 = np.zeros(n_taps) + f0[0], np.zeros(n_taps) + f0[-1]
f0_ = np.hstack((np.hstack((padd1, f0)), padd2))
fil = sl.firwin(numtaps=n_taps, fs=int(1./period), cutoff=cutoff, pass_zero=True)
f0_ = sl.lfilter(fil, 1, f0_)
f0_ = f0_[int(n_taps/2)+n_taps:len(f0)+n_taps+int(n_taps/2)]
return f0_
periodはF0のサンプリング周期(WORLDのデフォルトは0.005)。
発散しないまでもフィルタに通すと両端が大振りになるので
最初にf0の両端を伸ばしておく。どれくらい伸ばすかはご自由に(?)
また、FIRフィルタはタップ数の半分だけ遅延するので
その遅延分を取り戻してあげる(最後の行)。
FIRフィルタじゃなくても自分でFFTしても良いかと。
FFTで振幅スペクトルと位相を求めて、10Hz以上の振幅を1e-20くらいにして
iFFTで戻すだけ。
タップ数やパディング数は実際にやってみて良さそうな数字にしてる。
「ローパスフィルタでマイクロプロソディを除去しましょう」っていう話は細かいフィルタ設計までは説明見当たらないので
自分でいじってみるしかなさそう。。。
前処理[2] 夢精区間の補間
F0は無声区間は0で不連続なのでそこの補間が必要だが、HARVESTはそもそも無声区間でも補間してあるのでここはスルー(ハッピー!!!)
前処理[3] 平滑化
分析区間毎に3次関数で平滑化する。このとき分析区間の繋ぎ目でも連続かつ微分可能なように平滑化する。
ここは初学習者でも論文の数式を見れば実装できるかと。英語も優しいし。
①前処理の結果
②アクセント成分の近似
先ほど、F0は区間毎に3次関数で近似した。区間の境目でも微分可能にしてあるので、この平滑化F0の"1次導関数の"極大値と極小値を求め(つまり変曲点ですね)、それぞれからアクセント指令を求める。
このとき、極大値が0.6未満、極小値の絶対値が0.4未満の極値は無視する。
参考文献ではそう書かれてないけど載せてる図は明らか閾値処理してるし和文の方にそう書いてあるので
1次導関数の極値を求める
def inflection_point(coef, ix1, ix2, timeaxis):
dy = coef[:,1] + 2*coef[:,2] * timeaxis + 3*coef[:,3] * (timeaxis**2)
dy_ = dy[ix1:ix2+1]
# inflection point
maxid = sl.argrelmax(dy_)[0]
minid = sl.argrelmin(dy_)[0]
ix_ = np.hstack((maxid, minid))
ix = np.sort(ix_)
label = np.ones(len(ix))
tmp = np.asarray([np.where(ix == i)[0] for i in minid]).reshape(len(minid))
label[tmp] = -1
candidate = ix+ix1
return dy, candidate, label.astype(int)
・coefは3次近似したときの係数で、T-by-4の次元のarray配列。
・ix1, ix2は発話区間のオンセットとオフセットインデックス
・timeaxisは時間軸の配列で、WORLDで得られるやつ
アクセント指令の時刻を求める
極値を順に見ていって、極大値をとる時刻$t_{1j}$から$1/\beta$だけ遡った時刻をオンセット($T_{1j}$と呼ぶ)、極小値をとる時刻$t_{2j}$から$1/\beta$だけ遡った時刻をオフセット($T_{2j}$と呼ぶ)として採用していく。
ただし極大値(または極小値)が連続する場合は最も大きい極大値(または最も小さい極小値)を採用する。
ほいでもし最初が極小値から始まる場合、その極小値をとる時刻から平均1モーラ長遡った時刻を仮想的にオンセットとする。
和文の論文から引用した。
ちなみに今回、最後が極大値なら発話区間のオフセットを仮想的にアクセント指令のオフセットとした。
アクセント指令の振幅を求める
まず結論
$j$番目のアクセント指令の振幅$A_{aj}$は
\begin{align}
A_{aj} &= 0.5(A_{a1j} + A_{a2j}) \\
A_{a1j} &= \frac{\rm{e}}{\beta}G_0(t_{1j}) \\
A_{a2j} &= \frac{\rm{e}}{\beta}\big|G_0(t_{2j})\big| \\
G_0(t) &= a_1 + 2a_2 t + 3a_3 t^2
\end{align}
ただし$G_0(t)$の $a_k$ は①前処理で対数F0を3次関数近似した際の近似係数で、
$t_{1j} = T_{1j} + 1/\beta$で、$t_{2j} = T_{2j} + 1/\beta$
解説
英文ではきちんと記述されてないので和文から数式を持ってくる。
$t_{1j} = T_{1j} + \frac{1}{\beta}$ は対数F0の変曲点を取る時刻であり、1次導関数における極大値を取る時刻になっている。
\begin{align}
\frac{\partial}{\partial t} \log F_0[t] &\simeq \frac{\partial}{\partial t} A_{a1j}\big(G_a(t - T_{1j}) - G_a(t - T_{2j})\big) \\
&= X[t] \\
X[t_{1j}] &= \frac{\beta}{\rm{e}}A_{a1j}
\end{align}
対数F0の$t = t_{1j}$における1次微分係数がこれ。
なぜかフレーズ成分の項を消し飛ばしてるけど。
一方で、①前処理で対数F0は3次関数近似してるから、その近似係数を用いて
\begin{align}
\Big(\frac{\partial}{\partial t} \log F_0[t]\Big)[t_{1j}] &= a_1 + 2a_2 t_{1j} + 3a_3 t_{1j}^2
\end{align}
と表せるから
\begin{align}
\frac{\beta}{\rm{e}}A_{a1j}
&= a_1 + 2a_2 t_{1j} + 3a_3 t_{1j}^2 \\
&= G_0(t_{1j}) \\
A_{a1j} &= \frac{\rm{e}}{\beta}G_0(t_{1j})
\end{align}
となる。
同様に$A_{a2j} = \frac{\rm{e}}{\beta}\big|G_0(t_{2j})\big|$
負にならないよう絶対値を取る
以上から、$j$番目のアクセント指令の振幅$A_{aj}$は $A_{aj} = 0.5(A_{a1j} + A_{a2j})$ とする。
③フレーズ成分の近似
アクセント成分を減算した残差成分を積分して、ある値を超え始めた時点にフレーズ指令を立てる
発話区間最初のフレーズ指令
さっき求めたアクセント指令パラメータで合成したアクセント成分$y_a(t)$を$\log F0$から引く(→残差成分$R_0(t)$をゲット)。
R_0(t) = \log {\rm F_0}(t) - y_a(t)
次に、区間 $[T_S, T_{21}]$ において$R_0(t)$の最大値$R_{0max}$を取る位置$T_{R_{0max}}$を求めてる!→第一フレーズ指令の位置$T_{01}$をゲット!
T_{01} = T_{R_{0max}} - \frac{1}{\alpha}
残差$R_0$は$y_p$に依存するんだから$y_p$が最大なら$R_0$も最大でしょ!ってことで・・・
$R_0[t]$の最大値は$R_0[t_{0max}]$だから
\begin{align}
R_0[t] &= y_p[t] + y_b \\
R_0[T_{R_{0max}}] &= y_p[T_{R_{0max}}] + y_b \\
R_0[T_{R_{0max}}] - y_b & = y_p[T_{R_{0max}}]
\end{align}
なので、$y_p[T_{0max}]$が区間$[T_S, T_{21}]$での$y_p$の最大値になるはず。
だから数式をごにょごにょして、第一フレーズ指令の振幅$A_{p1}$は
A_{p1} = \frac{\rm{e}}{\alpha} \big(R_{0max} - y_b\big)
になる。
以降のフレーズ指令
今、$i$個のフレーズ指令が見付かったとする。
現状求めた全てのフレーズ指令を用いて$y_p(t)$を求め、
R_i = \log {\rm F_0} - ya - yp
と、残差を求める。
$R_i$が大きかったらまだまだフレーズ指令が存在するということ。 なので、$R$を積分していって$\theta_1$を超えたら$\theta_2 ( < \theta_1)$ を超えた時点に指令を立てる( $T_{0i+1}$の誕生)。 もし$T_{0i+1}$がアクセント成分内だったら当該アクセント指令のオンセットと、一個前のアクセント指令のオフセットの間に立て直す。 >本当はもう少し細かい処理をするけど面倒で...ごめんなさい
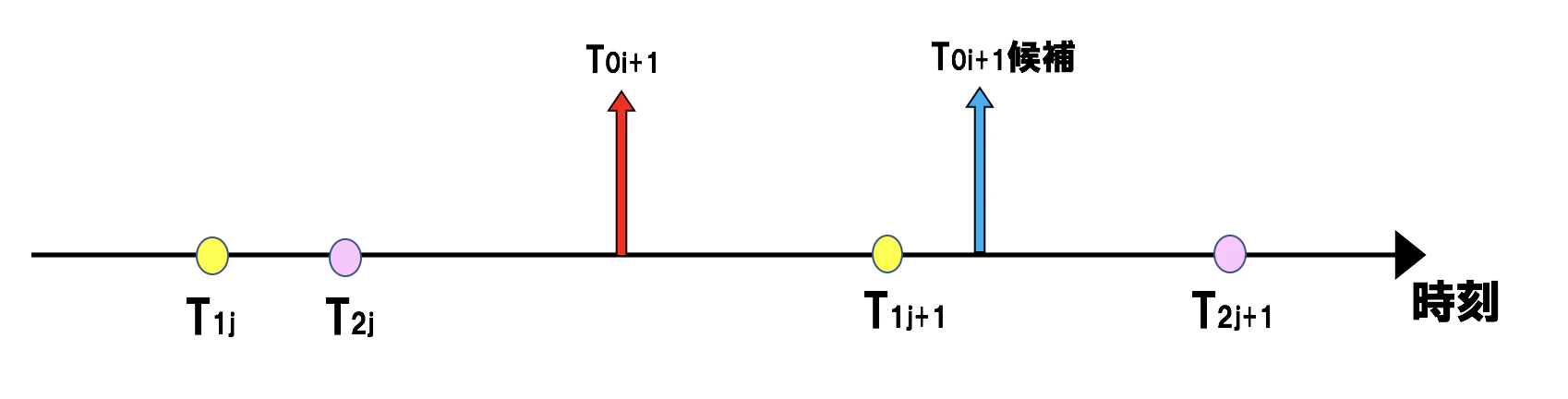
上図例のように、生起位置候補$T_{0i+1}$が $j+1$番目のアクセント指令内にあった場合(青矢印)、
``あらゆる指令は同居しない''というルールを破るので、移動させる(赤矢印)。
$T_{0i+1}$は先ほど同様、候補時刻から$1/\alpha$遡った時刻だと仮定して、 $R_{imax}$は$y_p(T_{0i+1}+1/\alpha)$の最大値と一致すると仮定すれば またまた数式をごにょごにょして
A_{pi+1} = \frac{\rm{e}}{\alpha} \big(R_{imax} - y_b\big)
はい。「[以降のフレーズ指令](#以降のフレーズ指令)」を繰り返す。 >和文では$i+1$番目のフレーズ指令を求めたら、その都度最適化して微調整してるけど面倒なので今回はしてません >積分の閾値は$\theta_1 = 7.0, \theta_2 = 3.0$にしてます。 閾値は記載ないのでやってみて良さげなもので。
④AbS最適化
求めた全ての指令を時系列順に1個ずつ最適化する。Analysis-by-Synthesisで、F0を再合成し、3次関数近似したF0との最少二乗誤差を最小化させる。
ただし、$k$番目のある指令$q_k$の最適化は
q_k^{\rm{new}} = \rm{argmin}_{q_k} \Big(\log {\rm F_0}(t) - \big\{y_a(t) + y_p(t) + y_b\big\}\Big)^2 \hspace{10pt} (t = [t_1, t_2])
$t_1$は指令の生起位置、$t_2$は指令の影響が無視できる時刻として、この区間内の誤差が小さくなればOK。
t2を探す:アクセント指令の場合
$t$が発散すると$y_a$は0に収束するので、"$y_a$の影響が無視できる時刻"を考えるのが面倒なので、
次の指令のオンセットの手前にしてみた。とりあえず。はい。
もし発話内最後の指令なら次の指令は存在しないので発話自体のオフセットにしておく。
あと!もう一つ!
アクセント指令を更新した時に隣の指令に侵食すると良くないので、
どんなに更新しても現段階の両隣の指令に侵食しないように!
→「もし更新して隣の指令と重なるor跨ぐなら、更新しない」
t2を探す:フレーズ指令の場合
本当はこれもちゃんと考えないといけないけどさっきと同じ理由でサボった。
さっきと同じで。はい。すみません。
最適化する
最適化は「山登り法」で行った。
勾配法でも良かったけど指令の時刻を1インデックス分増やす・減らす・留めるの3パターンしか無いんだから計算時間もかからないし山登り法の法が確実じゃないですか。
ただ、振幅については実数値だから大人しく勾配法を使った。
エポック数は20でいい感じになったよ〜
⑤結果
推定結果。アクセント指令が「ほんまに?」っていう感じもするけど
音源的にはフレーズ成分は2発しかなさそうな感じなので・・・まぁ・・・
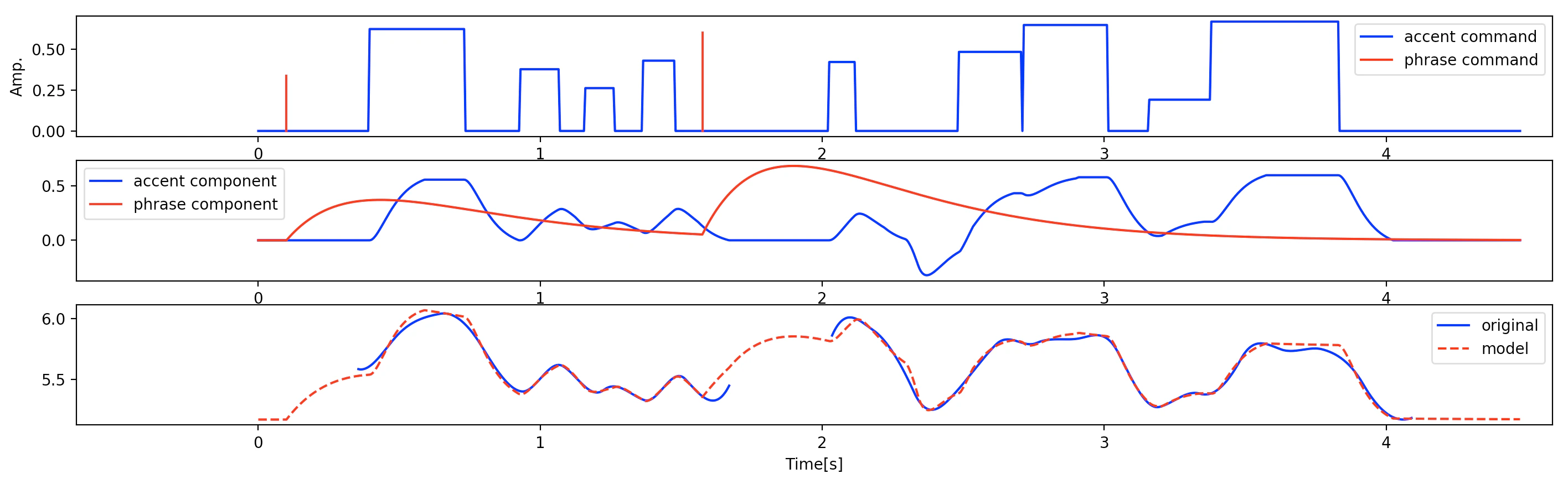
ちなみに最適化せず、初期推定のままだとこんな感じ。

⑥事後処理も
オリジナルのlogF0と3次近似したlogF0の残差を求めておいて、
再構築したlogF0にその残差を加えてあげましょう。
zansa = numpy.log(f0_orijinal) - f0_approximated
f0_recon = f0_recon + zansa
f0_recon_ = numpy.exp(f0_recon)
本当はこのままやるとlog(0)の警告、log(0)が生んだ-infの演算による警告が出るので
ちゃんと0の取り扱いには配慮しましょう。
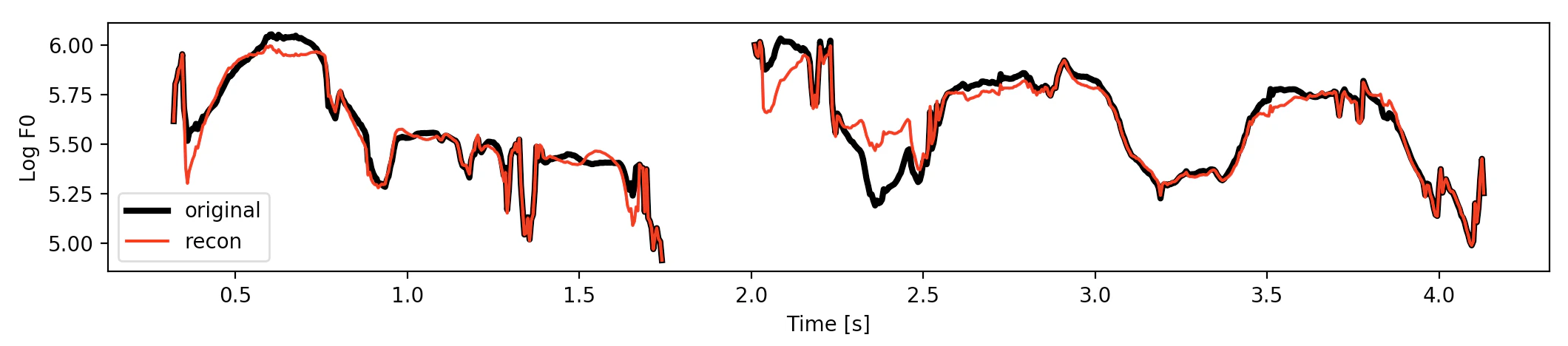
オリジナルのF0(黒)と再合成したF0(赤)が概形一致してる。
各発話区間の頭とケツがピッタリ合うのは
おまけに書きまーす
おまけ
WORLDの基本周波数推定アルゴリズムを使ってF0を抽出してます。
アルゴリズムは
- DIO
- HARVEST
の2つあります。
HARVESTはDIOと違い連続値でF0を得られますが、
その推定されたF0は、候補生達の中から信頼度が高いためF0として選ばれてます。
HARVESTは頭とケツのF0よりちょい前後の候補生達も、「滑らかに接続できそうやん!」ってなれば
もれなく敗者復活でF0として選択するアルゴリズムになってます(多分そんな感じだったかと)。
今回、3次近似するときにそれが邪魔な場合があるので
F0の有声区間についてのみDIOのものを使いました。
なので今回の藤崎モデルパラメータ推定はF0よりも少し狭い範囲での物語になります。
再構築するときは残差を用いて微細変動を復元してるため、
その都合で推定時に無視した区間のF0が元のF0と完全一致します。
これが良いのか悪いのかは知りませんが、
その端っこのF0の挙動によって3次近似の概形が変わるのと、
そうすると先々のパラメータ推定にも影響してくるわけで
僕のチープな肌感だとHARVESTのF0延長する仕様は邪魔だと思ったのでこうしました。
おしまい
間違いや改善点などご指摘いただけると幸いです。
個人的に、DeepLearningよりこういうアルゴリズムというか処理の方が好きなので
もっともっと勉強していきたい所存です。