はじめに
私は業務でよくColabを使っています。
思い返してみると、使い始めたばかりの時は、「どうやってスプレッドシートを読み込むんだ?!」と毎回悩んでいました。
そこで、同じ悩みを持つ方を1人でも減ったらいいなと思い、私が安定した方法を記載します。
なおサンプルコード・スプレッドシートを公開していますので、お好みに合わせてご覧ください。
場面設定
以下のような状況を仮定しています。
Google Drive上のスプレッドシート「ダイエット記録」をPythonで加工や可視化を行いたい。
そのために、まずスプレッドシートを読み込ませたい。
1. データの読み込み
早速コードをご紹介いたします
- よく使うライブラリをインポート
import pandas as pd pd.set_option('display.max_columns', None) import numpy as np import seaborn as sns sns.set() !pip install japanize-matplotlib import matplotlib.pyplot as plt import japanize_matplotlib japanize_matplotlib.japanize() - 認証する
# 認証のためのコード from google.colab import auth auth.authenticate_user() import gspread from google.auth import default creds, _ = default() gc = gspread.authorize(creds) - スプレッドシートのURLとシート名を指定する
## スプレッドシートを開く(シートURLから) url = "https://docs.google.com/spreadsheets/d/12GsIwLvAX8vGNA1m1XWM_YupRG2oGIJOhQ15KiDeocs/edit#gid=0" ss = gc.open_by_url(url) # シートを特定する(シート名で特定) st = ss.worksheet("シート1") # スプレッドシートのデータをPandasのDataframeに変換する。 rows = st.get_all_values() df = pd.DataFrame.from_records(rows[1:], columns=rows[0]) - 結果を確認する
df.head(10)
2. データ型の変更
- データ型を確認すると、すべてobject型になっています
df.info() - 必要に応じてデータ型を変更します
# floatに変更 num_cols = ['体重'] df[num_cols] = df[num_cols].astype(float) # datetimeに変更 datetime_cols = ['日付'] for col in datetime_cols: df[col] = pd.to_datetime(df[col], format='%Y/%m/%d', errors='coerce') - きちんと変更されたか、再度確認します
df.info()
3. 可視化
-
場面設定に基づいて、可視化してみます。
なお、最初にjapanize_matplotlibをインポートしているので日本語で表示できます。# 折れ線グラフの作成 plt.figure(figsize=(10, 5)) plt.plot(df['日付'], df['体重'], marker='o', linestyle='-', color='b') # グラフのタイトルとラベルを設定 plt.title('日付と体重の推移') plt.xlabel('日付') plt.ylabel('体重 (kg)') # グラフを表示 plt.grid(True) plt.show()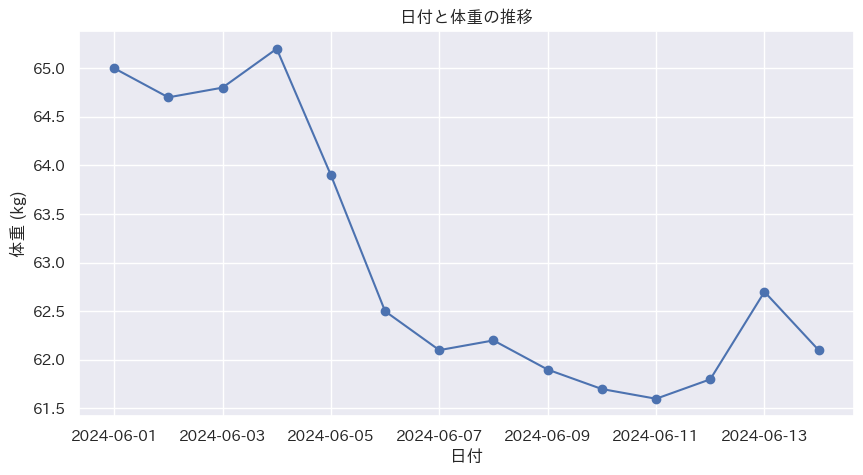
終わりに
最後までお読みいただきありがとうございました!