pandas 基本機能
基礎項目に加え、データサイエンス・機械学習、Kaggle等でよく使う機能をまとめました。
Pandasは、Pythonでデータ分析を行うためのライブラリで、データの読み込みや編集、統計量の表示が可能。
公式ドキュメント:http://pandas.pydata.org/pandas-docs/stable/
0.ライブラリのインポート
import pandas as pd
1.シリーズとデータフレーム
pandasには、Numpyをベースとした Series と DataFrame という型が存在する。
■ Seriesの生成
ser = pd.Series([10, 15, 20, 25])
>>> ser
0 10
1 15
2 20
3 25
dtype: int64
■ DataFrameの生成
pd.DataFrame([[100, "a", True],
[150, "b", False],
[300, "c", False],
[550, "d", True]])

DataFrameオブジェクトを作る方法は多数ある
pd.DataFrame(np.arange(12).reshape((3, 4)))

# 辞書からデータフレームを作成
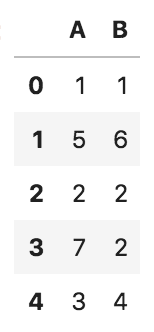
pd.DataFrame({
'A' : [1, 5, 2, 7, 3],
'B' : [1, 6, 2, 2, 4]
})
2.データの基本操作・整形
生成したデータを使い基本操作を解説します。
■ データの作成
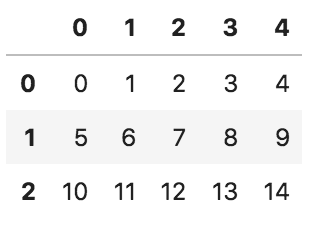
df = pd.DataFrame(np.arange(15).reshape((3, 5)))
df
■ 行名、列名の指定
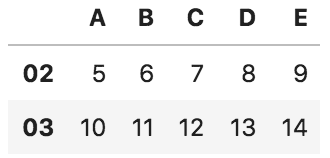
df.index = ["01", "02", "03"]
df.columns = ["A", "B", "C", "D", "E"]
df

■ 列を指定し表示
df["A"] #A列のみ表示

■ 複数の列の指定
df[["A", "B"]] #[]忘れないように..

■ 行の指定
df[1:] #2行目以降を表示
■ locメソッドを使った範囲指定
loc[]の引数には、行名、列名を入力する
df.loc["02", ["B", "D"]] #行"02"、列"B"と"D"の値を出力

■ ilocメソッドを使った範囲指定
loc[]の引数には、行番号、列番号を入力する
df.iloc[:2, 2:4]
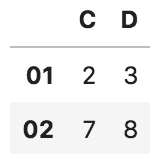
■ 条件で抽出
df[df["E"] > 5] #列Eが5より大きいデータを抽出
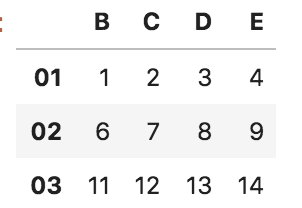
■ queryメソッドで抽出
SQL構文のように複数条件で抽出可能
df.query("A > 3 and C < 10")
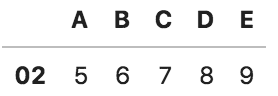
■ 列の削除
df.drop("A", axis=1) #列名を指定
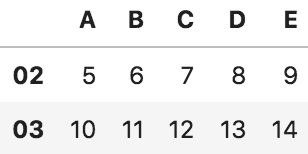
■ 行の削除
df.drop(["01", "03"])

■ 列の追加
df['new']=[100,200,300]
df

3.データを基本情報を調べる
アヤメのデータを使って基本情報を抽出します。
■ CSVファイルの読み込み
df = pd.read_csv("/Users/..../iris.csv")
# CSVファイルのローカルアドレスをタプルに入力
# CSVに区切りがある場合はタプルに("~.scv", sep = ",")のように指定する
■ 最初の5行のみ表示
df.head() #タプル内に数字を指定し任意の行数に変えることも可能
■ 最後の5行のみを表示
df.tail()
■ データフレームの大きさを確認
>>> df.shape
(150, 5) #150行5列のデータフレーム
■ 基本統計量をまとめて表示
df.describe()
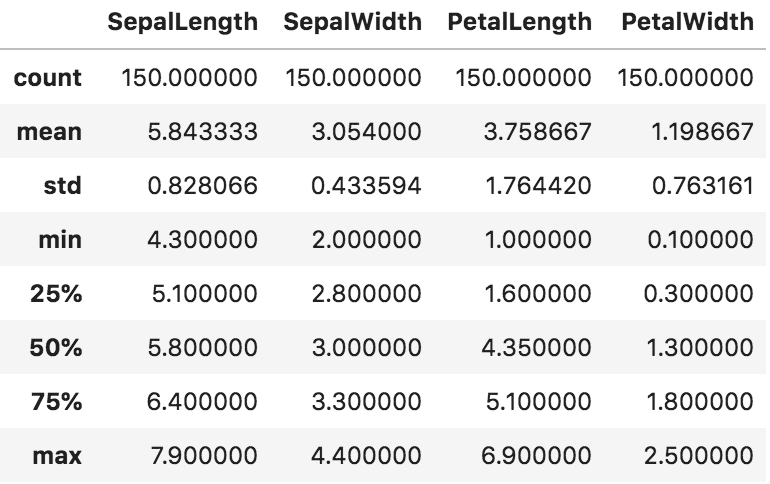
■ 基本統計量メソッド
- .max() 最大値
- .min() 最小値
- .mode() 最頻値
- .mean() 平均値
- .median() 中央値
- .std() 標準偏差
- .count() 件数
- .corr() 相関係数(列間のデータの相関関係を数値化、主にテーブル全体に対して使う。)
- .unique() カテゴリカルデータの項目を表示
- .value_counts() 項目別数量
df.mean() #列ごとの平均を出力

4.その他の実用的な整形メソッド
データ分析で使う様々なメソッドを紹介します。
3.同様アヤメのデータ(df)を使用します。
■ ソート・並べ替え
df.sort_values(by="PetalWidth")
# "PetalWidth"列でソート
# デフォルトでは昇順
df.sort_values(by="PetalWidth",ascending=False)
# 降順
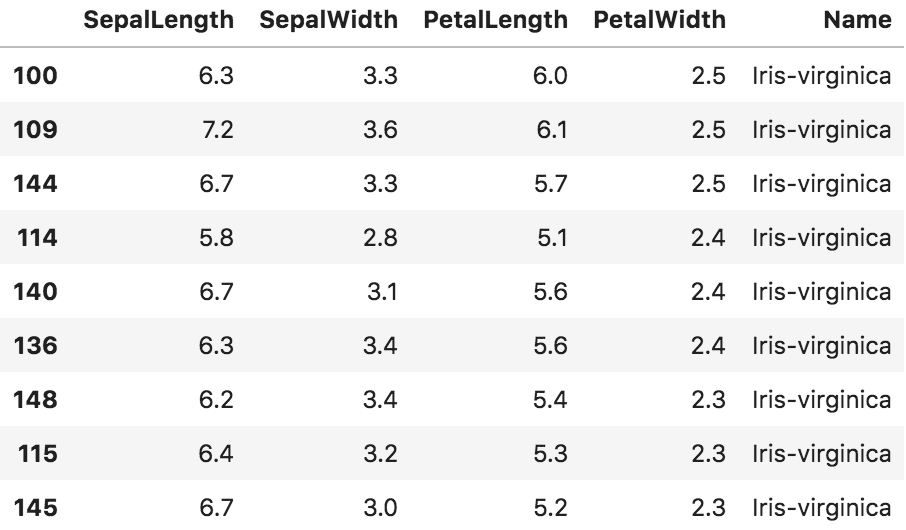
■ グループバイ
df_groupby = df.groupby("Name") #Name列で集約されたオブジェクトを作成
df_groupby.mean() #Nameのカテゴリー別平均
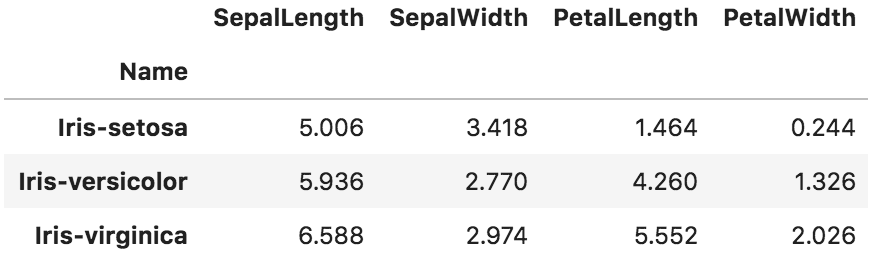
df_groupby.describe() #カテゴリー別基本統計量をまとめて表示

■ ピポッドテーブル
新しくデータフレームを作成します
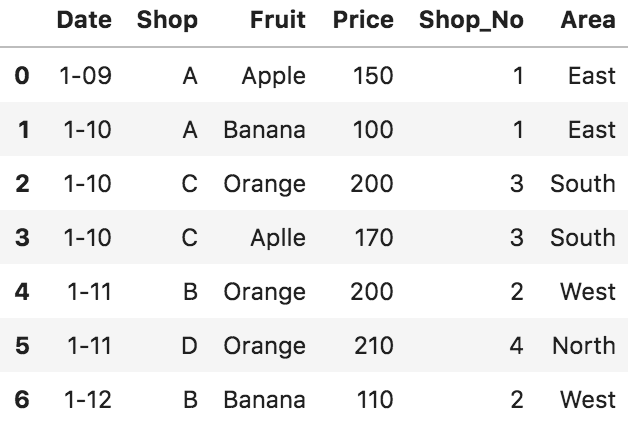
df=DataFrame([['1-09','A','Apple',150],
['1-10','A','Banana',100],
['1-10','C','Orange',200],
['1-10','C','Aplle',170],
['1-11','B','Orange',200],
['1-11','D','Orange',210],
['1-12','B','Banana',110]],
columns=['Date','Shop','Fruit','Price'])
df

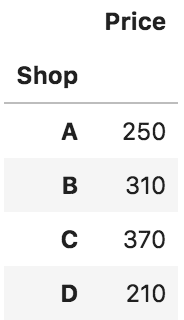
df.pivot_table(values = 'Price', index = 'Shop', aggfunc = sum)
# 店舗別の売上合計
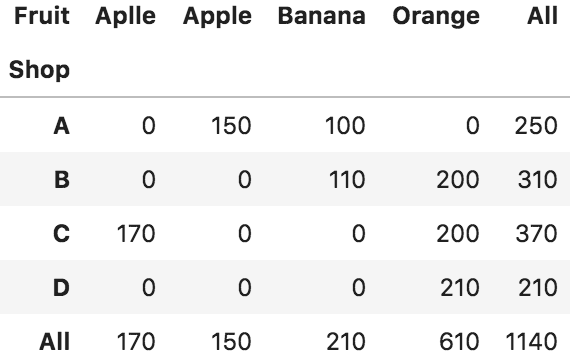
df.pivot_table(values = 'Price', index = 'Shop', columns = 'Fruit', aggfunc = sum)
# columnsを追加し商品別に売上を表示

df.pivot_table(values = 'Price', index = 'Shop', columns = 'Fruit',
aggfunc = sum, fill_value = 0)
# fill_value = 0 でNaNを0に変換

df.pivot_table(values = 'Price', index = 'Shop', columns = 'Fruit',
aggfunc = sum, fill_value = 0, margins = True)
# margins = True 合計を表示
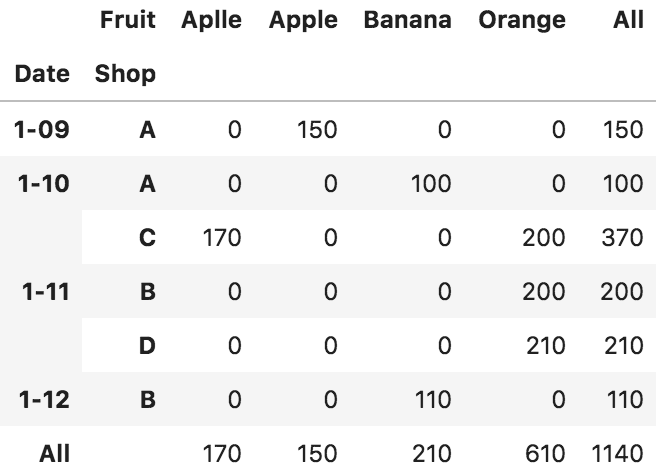
df.pivot_table(values = 'Price', index = ['Date','Shop'], columns = 'Fruit',
aggfunc = sum, fill_value = 0, margins = True)
# 'Date'を加えてindexを階層化
■ データフレームの連結
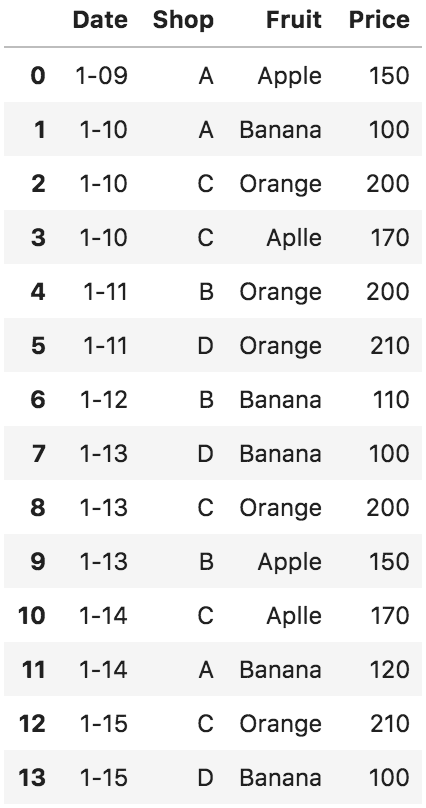
データフレーム df を改めて確認
df

同じ構造をもつ df_2 を作成
df_2 = DataFrame([['1-13','D','Banana',100],
['1-13','C','Orange',200],
['1-13','B','Apple',150],
['1-14','C','Aplle',170],
['1-14','A','Banana',120],
['1-15','C','Orange',210],
['1-15','D','Banana',100]],
columns=['Date','Shop','Fruit','Price'])
df_2

df、 df_2 を行で連結
pd.concat([df, df_2], ignore_index=True)
# ignore_index=True でインデックスの振り直しが可能
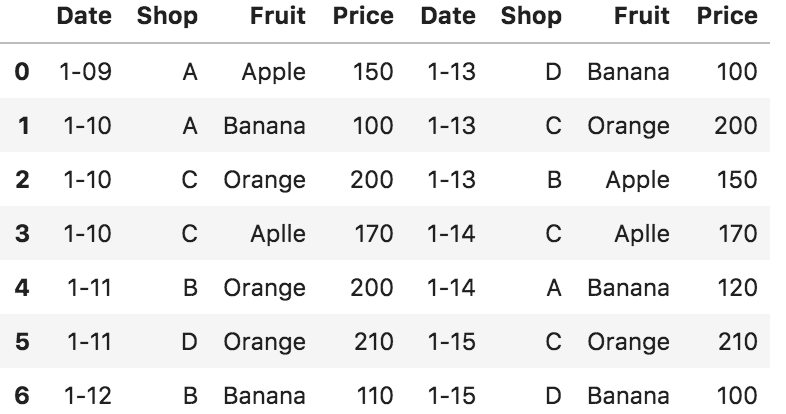
df、 df_2 を列で連結
pd.concat([df, df_2], axis=1, join_axes=[df.index])
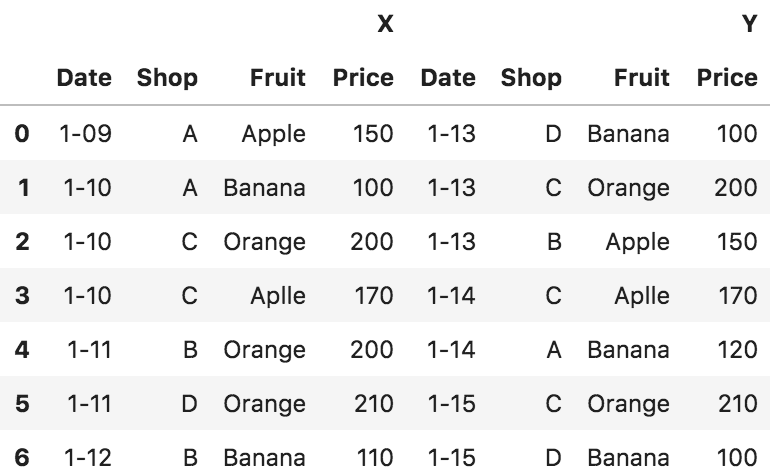
連結元のデータをラベルで分けて連結
pd.concat([df, df_2], axis=1, join_axes=[df.index], keys=['X', 'Y'])
■ データフレームの結合
引き続きデータフレーム df を使用
df
*df_3を作成 *
df_3 = DataFrame([['1','A','East'],
['2','B','West'],
['3','C','South'],
['4','D','North'],
['5','E','EC']],
columns=['Shop_No','Shop','Area'])
df_3
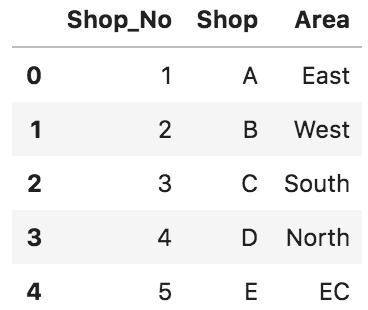
'Shop'を基点に結合
pd.merge(df, df_3, on='Shop')

howで結合方法を選択可能
- inner: 両方のデータに含まれるキーだけを残す。(内部結合)
- left: 1つめのデータのキーをすべて残す。(左外部結合)
- right: 2つめのデータのキーをすべて残す。(右外部結合)
- outer: すべてのキーを残す。(完全外部結合)
pd.merge(df, df_3, on='Shop', how='left')
pd.merge(df, df_3, on='Shop', how='right')

5.その他メモ
■ インデックス番号で抽出
df.ix[5:10]
■ データ変換(DataFrame → Numpy配列)
アルゴリズムによってはDataFrameのままでは読み込めないものもあり、その際に変換が必要。
df["A"].values #列AをNumpy配列に変換
■ データフレームに関数を適用
# データフレームの全ての値を2乗にしたい場合
func = lambda x: x**2
df.apply(func)
# 列に適用し更新したい場合
df["A"] = df["A"].apply(func)
# タプルにそのまま関数を書いても良い
df.apply(lambda x: x**2)
■ インデックス変更・更新
df.set_index('Date', inplace=True)
# 第一引数にindexにしたい列名を入力
# inplace=True でデータを更新
■ オブジェクト型のみに絞る / オブジェクト型を除外
# オブジェクト型のみ出力
df.select_dtypes(include=['object'])
# オブジェクト型を除外
df.select_dtypes(exclude=['object'])
■ エクセルファイルの読み込み
pd.read_excel("~.xlsx")