概要
最近、Google Cloudを使い始めた私です
せっかく使えるようになったということでやってみたかったことをやろうと思います
それはYoutubeのコメントを全て収集して分析するということです
分析と言っても当初想定していたのは、タイムスタンプ付きのコメントだけを集めて動画の注目ポイントを集めていつでも見返せるようにするというようなものです
とりあえず、コメント全部集めるところをやろうと思います
本題
ここで、Youtube Data APIの割り当て上限を再確認します
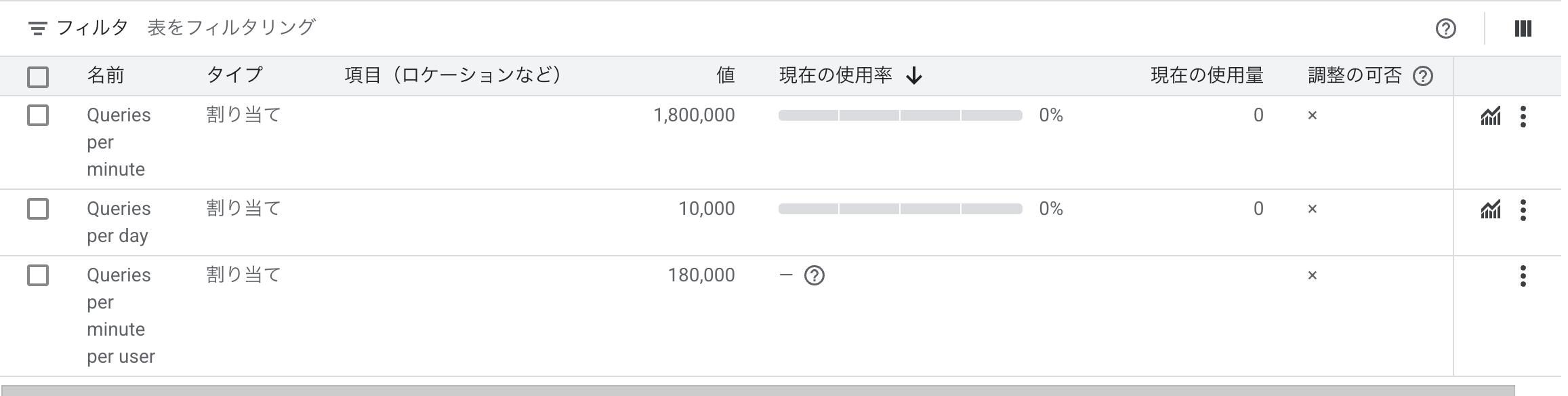
1日あたり10,000ユニット使えるようで、1回のリクエストで1ユニット消費でなくアクションごとに消費するユニットは異なる模様です
コメントなどの一覧取得系(list)は一部を除き、1リクエスト1ユニット消費
コメントを残すなどの作成系(insert, update, delete)は1リクエストあたり50~1,600ユニットを消費するようです
今回扱うのはcommentThreadsを使用する予定なので1日あたり10,000回リクエストできると考えて良さそうです
またcommentThreadsで1回あたりに取得できるデータ件数は1~100件のようです
https://developers.google.com/youtube/v3/docs/commentThreads/list?hl=ja
ということで1日あたりに取得できるコメントの総数は10,000 * 100 = 1,000,000コメント取得することができるという計算になります
これだけ取れればかなりの動画について処理を行うことができそうな気がします
実際のコード
収集できるコメントの件数がわかったところで、続いて実際のコードに移ろうと思います
環境としては以下の通りです、ライブラリのインストールが必要になるので仮想環境の作成をお勧めします
- Python3.11.9
まずはYoutube Data APIをPythonで実行するために必要なライブラリをインストールします
pip install google-api-python-client
コメントを収集するためのコードが以下になります
import googleapiclient.discovery
def get_all_comments(api_key: str, video_id: str) -> list:
"""
指定された動画IDのすべてのコメントを取得する関数
Args:
api_key (str): YouTube Data APIのAPIキー
video_id (str): コメントを取得したい動画のID
Returns:
list: 全てのコメントを格納したリスト
"""
# YouTube Data APIクライアントを構築
youtube = googleapiclient.discovery.build(
"youtube",
"v3",
developerKey=api_key
)
comments = []
next_page_token = None
while True:
try:
# コメントスレッドリストAPIを呼び出し
request = youtube.commentThreads().list(
part="snippet",
videoId=video_id,
textFormat="plainText",
maxResults=100, # 1ページあたりの取得件数を指定(最大は100)
pageToken=next_page_token
)
response = request.execute()
# レスポンスからコメントを抽出
for item in response["items"]:
comment_text = item["snippet"]["topLevelComment"]["snippet"]["textDisplay"]
comments.append(comment_text)
# 次のページトークンを取得
if "nextPageToken" in response:
next_page_token = response["nextPageToken"]
else:
# nextPageTokenが存在しない場合、最後のページに到達
break
except Exception as e:
print(f"エラーが発生しました: {e}")
break
return comments
# --- 使用例 ---
if __name__ == "__main__":
# 自身のAPIキーと動画IDを設定
YOUR_API_KEY = "YOUR_API_KEY"
VIDEO_ID = "VIDEO_ID"
all_comments = get_all_comments(YOUR_API_KEY, VIDEO_ID)
if all_comments:
print(f"動画ID: {VIDEO_ID} のコメント件数: {len(all_comments)}")
print("--- 最初の5件のコメント ---")
for i, comment in enumerate(all_comments[:5]):
print(f"{i+1}: {comment}")
else:
print("コメントが見つからないか、取得できませんでした")
とりあえず取得したコメントの5件を表示する結果になります
注意点としてはAPIの仕様上、コメントのスレッドについては取得されず、トップレベルのコメントについてのみを収集するようになっています
次にコメント内に含まれているタイムスタンプについてですが、こちらは正規表現を使って、時刻形式が当てはまればタイムスタンプだけを抜き出すということにします
さらに、タイムスタンプがわかれば該当シーンのリンクも判明させられるので、合わせて結果に複まえられるようにします
(該当シーンから流すためには秒数換算が必要なので、その計算も忘れずに)
for item in response["items"]:
comment_text = item["snippet"]["topLevelComment"]["snippet"]["textDisplay"]
# コメントからタイムスタンプを抽出
match = TIMESTAMP_PATTERN.search(comment_text)
scene_timestamp = match.group(0) if match else "該当なし"
link = "該当なし"
if match:
# タイムスタンプを秒数に変換
groups = match.groups()
hours = int(groups[0]) if groups[0] else 0
minutes = int(groups[1])
seconds = int(groups[2])
total_seconds = hours * 3600 + minutes * 60 + seconds
# YouTubeの該当シーンへのリンクを作成
link = f"{BASE_URL}&t={total_seconds}s"
comments_data.append({
"comment": comment_text,
"scene_timestamp": scene_timestamp,
"link": link
})
もろもろCSV出力などいろいろ飛ばしてしまっていますが、最終的なコードから出力された結果は以下の内容となります(僕の最近のお気に入りの作業用動画から拝借させていただきました、同じように好きな方いたら嬉しいです)
comment,scene_timestamp,link
13:25サンボマスター,該当なし,該当なし
このサンボマスタードラゴンは普通に企画にして欲しい。大っぴらには普段言わないけどもってる、個人的なこだわりとか主張を発表した後に歌う企画,該当なし,該当なし
これガチでシリーズ化してほしい,該当なし,該当なし
7:30 町田が龍と化して魂の咆哮をあげる所好き,7:30,https://www.youtube.com/watch?v=xkdReS1iMrg&t=450s
1:57 ォンナジョウシヨワミニギリ~,1:57,https://www.youtube.com/watch?v=xkdReS1iMrg&t=117s
終わりに
ということで、以上で初のGoogle Cloud & APIを利用したアイディアの具現化紹介でした
他にも色々なAPIが存在しているので、無料の範囲内で自分のアイディアに活用できそうなものを探してみたいと思います
今回のコードは気が済んだらgithubに挙げて改善続けていければな、、とぼんやり思っております
挙げられた暁にはぜひ覗きにきていただけると嬉しいです