はじめに
Elasticsearchはスケーラビリティと可用性、耐久性向上のためデータをいくつかに分割(Sharding)した上でそのコピー(Replica)を作成、各ノードに分散させる機能があります。これにより一部のノードに障害が発生してもサービスの継続とデータロストの防止を実現しています。単純に考えてReplicaと同じ数までのノードが故障してもデータは失われない、ということになりますね。
しかしクラウドやKubernetes上でElasticsearchを動かそうとした場合この考え方だけでは穴がありますので、今回はGKEを題材にその穴の塞ぎ方を検討したいと思います。
前提知識
- 一般的な冗長構成・可用性の考え方を理解していること
- Elasticsearchの基本的な動作、使い方を知っていること
- k8s(GKE)の基本的な動作、使い方を知っていること
- LinuxやGCPの基本的な使い方を知っていること
- GKE, GCEあたり
この記事で使うやや曖昧な用語の定義
障害ドメイン
この記事でいうところの障害ドメインとは「一度にまとめて壊れることを想定する範囲」とします。言い換えると「設計時に考慮する障害の範囲」でしょうか。例えば「サーバーを2台立てたので1台故障しても大丈夫です!」という場合において障害ドメインは「1台のサーバー」ということになります(この場合2台同時に壊れることは想定していない)。
通常Elasticsearchを使った場合の障害ドメインは1つのノードで、他のデータベース等でも概ね同様かと思います。しかしクラウド環境においては大抵の場合障害ドメインは1つのデータセンターでありGCPではZone、AWSではAvailability Zone(AZ)と称されます。余談ですが私は過去にAWSのSolution Architect試験を取得したことがありますが「AWSで冗長性を確保する場合はAZを跨いだ構成にすること」ということが徹底されていました。
耐久性
障害が起きてもデータが消えないことを指します。サービスを継続して提供する「可用性」とは区別して書きます。
そのままデプロイするとどのような問題が起こるか?
k8sが障害ドメインを考慮しないでPodをデプロイする
k8sのスケジューラーはノード毎のリソース使用状況を考慮して良い感じにPodを分散してくれますが、これは特段設定をしない限り障害ドメインを考慮しないので場合によっては障害ドメインを重複してしまう可能性があります。特にクラウドでは一般的なオンプレ環境と違い別のノード(サーバー)であっても同じ障害ドメインに属するのが当たり前なのでこの傾向がより顕著になります。
また動作には永続ディスクが必要になるので障害発生時にPodが再起動されてもディスクをアタッチできずに起動失敗する、等といった問題もあります。
Elasticsearchがインフラ側の障害ドメインを考慮しないでデータを分散する
Elasticsearchが認識するノードは通常そのバックエンドについては考慮されないので、例えばShard4, Replica1で障害ドメインA, Bそれぞれにサーバーが2台ずつあった場合以下のように配置されてしまう可能性があります。4分割されたS0〜S3までのデータがありそのReplicaであるS0'〜S3'がある、という下記の状況ではS0とS3のReplicaが同じ障害ドメインに属しているので、例えばAがダウンするとS0のデータが失われてしまいます。
- 障害ドメインA
- ノード1: S0 S1
- ノード2: S0' S2
- 障害ドメインB
- ノード3: S1' S3
- ノード4: S2' S3'
データの分散具合によってはスループットが低下する
通常クラウドにおける障害ドメインはデータセンターを跨ぐため物理的な距離があり、ドメイン内同士の通信より遅延が大きくなります。Elasticsearchの検索クエリーはShard毎に分散して行われ最後にそれを集計した結果を返却するという動作をしますので、単一の障害ドメイン内でデータが揃わない場合データセンター越しの通信が発生しスループットが低下することが考えられます。
下記の状況では先ほどと違いデータの耐久性という面では問題はありませんが、一つのドメインで検索に必要な全データが揃いません。例えば障害ドメインAに対して検索クエリーを発行した場合S0とS1のデータはありますがS2のデータはBまたはCと通信しないと入手できないことになります。
- 障害ドメインA
- ノード1: S0
- ノード2: S1
- 障害ドメインB
- ノード3: S2
- ノード4: S0'
- 障害ドメインC
- ノード5: S1'
- ノード6: S2'
対策
何を実現しなければならないか?
以下2つを同時に満たす必要があります。
- 障害ドメイン内で完全なIndexが揃うようにShardを配置する(パフォーマンス)
- 障害ドメインを跨いでReplicaを配置する(可用性・耐久性)
k8sでPodが起動するノードをZone単位で制限する
k8sには特定の条件に合うNodeにしかPodを立てない等といった制御をするための機能があります。GKEでは自動でノードに failure-domain.beta.kubernetes.io/zone=<zonename> というLabelが付いてくるので、これを元にnodeSelectorかnodeAffinityでZoneを固定することでZoneを重複してPodが立つことを防止できます(同僚に聞いたところではEKSやAKS等でも同様になLabelが付いてくるそうです)。
$ kubectl get nodes -L=failure-domain.beta.kubernetes.io/zone
NAME STATUS ROLES AGE VERSION ZONE
gke-default-cluster-default-pool-10751bd4-c54r Ready <none> 178m v1.13.11-gke.14 asia-northeast1-b
gke-default-cluster-default-pool-10751bd4-xs7k Ready <none> 178m v1.13.11-gke.14 asia-northeast1-b
gke-default-cluster-default-pool-2e3a585c-4vmd Ready <none> 177m v1.13.11-gke.14 asia-northeast1-c
gke-default-cluster-default-pool-2e3a585c-zkrn Ready <none> 177m v1.13.11-gke.14 asia-northeast1-c
gke-default-cluster-default-pool-74cd1ba7-1lsv Ready <none> 177m v1.13.11-gke.14 asia-northeast1-a
gke-default-cluster-default-pool-74cd1ba7-ff5x Ready <none> 177m v1.13.11-gke.14 asia-northeast1-a
なお永続ディスクは基本的にZoneを跨げませんのでその制約もこの設定で回避することが可能です(2つまでならRegional persistent diskでアクセスできますが今回やりたいこととは合わないので割愛)。
但しこれはあくまでk8s側の話であって、内部で動くElasticsearchがどのようにデータを配置するかまでは関知しないためこれだけではまだ不十分です。
Elasticsearchのオプションで障害ドメインを認識してShard, Replicaを配置してもらう
Shard Allocation Awarenessを使うと何らかのタグでElasticsearchのクラスター内部を区分けしReplica, Shardが重複しないようにしてくれます。詳細は後述しますがElastic社公式のCRDではManifestで指定できるのでPodの制限と同じようにZone名をタグに使えば良いでしょう。
具体的な設定例
環境
- GKE
- Master version 1.13.11-gke.14
- Node zones
- asia-northeast1-a
- asia-northeast1-b
- asia-northeast1-c
- Nodes
- 6 x n1-standard-4 (2 per Zone)
- SSD 100GB
- Preemptible VM
- Network
- default
- Elasticsearch
- 公式CRD使用
- 7.4.0
- Kibana
- 公式CRD使用
- 7.4.0
Manifest
公式のカスタムリソースを適用することで Kind: Elasticsearch や Kind: Kibana を使うことができるようになります。実体としてはElasitcsearch側の設定諸々を指定してStatefulSetを作ってくれるもののようです。
私のリポジトリ にファイルを公開していますのでCloneしてディレクトリを移動して下さい。今回はMaster3台、Data6台を構築します。
elasticsearch.yaml
冒頭のStorageClassはPodと同じZoneに永続ディスクを作るためのものです。GKEデフォルトのStorageClassを使うとなぜかPodのZoneと違うZoneにディスクが作成されて起動に失敗するという事象がおきました(そもそも簡易的っぽいですしどっちにしろ自分で定義することになるとは思いますが)。
Masterとして起動するため node.master: true を設定しdataはfalseにしておきます。Zoneを指定するので個別に3つ作らないといけないのが少々面倒ですが頑張って書きましょう。また先に挙げた問題の対策のため以下の4つを指定しておきます(詳細な記述方法は実際のファイルを見て下さい)。当たり前ですがnodeSelectorとElasticsearch側でZoneの指定が食い違っていると正しく動きません。
- k8s
- nodeSlectorに
failure-domain.beta.kubernetes.io/zone: asia-northeast1-a
- nodeSlectorに
- Elasitcsearch
- node.attr.zone: asia-northeast1-a
- cluster.routing.allocation.awareness.attributes: zone
- cluster.routing.allocation.awareness.force.zone.values: asia-northeast1-a,asia-northeast1-b,asia-northeast1-c
Dataについては先と反対に node.data: true を指定しmasterはfalseにします。また上記問題対策の設定も必要なので同様に記述しておきます。
どちらのロールでも共通して永続ディスクを使用する必要があります。Dataについてはいわずもがなだと思いますが、Masterにも必要です。私は面倒くさがってemptyDirを指定したところ毎回メタデータが消えるためかテスト障害の発生後に復旧すると別のMasterノードと認識されてしまう事象が起きました。
動作確認
まずはElasticsearchクラスターを立ち上げるために以下のコマンド3つを順番に叩きます。 kubectl get pods で全部のPodがReadyになったら次の手順に進みましょう。
$ kubectl apply -f https://download.elastic.co/downloads/eck/1.0.0-beta1/all-in-one.yaml
customresourcedefinition.apiextensions.k8s.io/apmservers.apm.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/elasticsearches.elasticsearch.k8s.elastic.co created
customresourcedefinition.apiextensions.k8s.io/kibanas.kibana.k8s.elastic.co created
clusterrole.rbac.authorization.k8s.io/elastic-operator created
clusterrolebinding.rbac.authorization.k8s.io/elastic-operator created
namespace/elastic-system created
statefulset.apps/elastic-operator created
serviceaccount/elastic-operator created
$
$
$ kubectl apply -f elasticsearch.yaml
storageclass.storage.k8s.io/ssd created
elasticsearch.elasticsearch.k8s.elastic.co/eck created
$
$ kubectl apply -f kibana.yaml
kibana.kibana.k8s.elastic.co/kibana created
$
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
eck-es-data-a-0 1/1 Running 0 11m
eck-es-data-a-1 1/1 Running 0 11m
eck-es-data-b-0 1/1 Running 0 11m
eck-es-data-b-1 1/1 Running 0 11m
eck-es-data-c-0 1/1 Running 0 11m
eck-es-data-c-1 1/1 Running 0 11m
eck-es-master-a-0 1/1 Running 0 11m
eck-es-master-b-0 1/1 Running 0 11m
eck-es-master-c-0 1/1 Running 0 11m
kibana-kb-67679bf955-z4sdr 1/1 Running 0 11m
正常性確認
Kibanaの画面でクラスターのHealthを確認しますが、Serviceを作るのは面倒なのでport-forwardを使います。以下コマンドを叩いてからブラウザで https://localhost:5601/app/monitoring にアクセスします。
$ kubectl port-forward service/kibana-kb-http 5601
Forwarding from 127.0.0.1:5601 -> 5601
Forwarding from [::1]:5601 -> 5601
なおデフォルトのIDは elastic でパスワードは以下のコマンドで表示して下さい。シェル変数にも入れておくのは後でcurlを叩くためです。
$ PASSWORD=$(kubectl get secret eck-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode)
$ echo $PASSWORD
hvm7xcjpkgt45fshwgfxx79c
最初は監視がOffになっています。画面の真ん中に出てくる Turn on monitoring ボタンを押してからリロードすると以下のような画面になりますので、Health is green であることを確認します。またNodesのタブから全てのノードがOnlineであることも確認します。
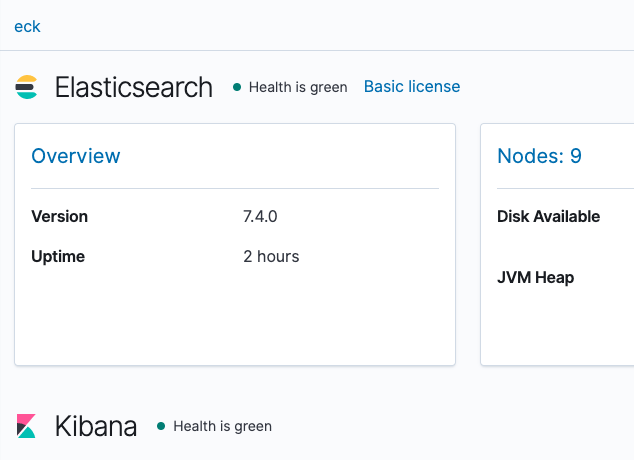
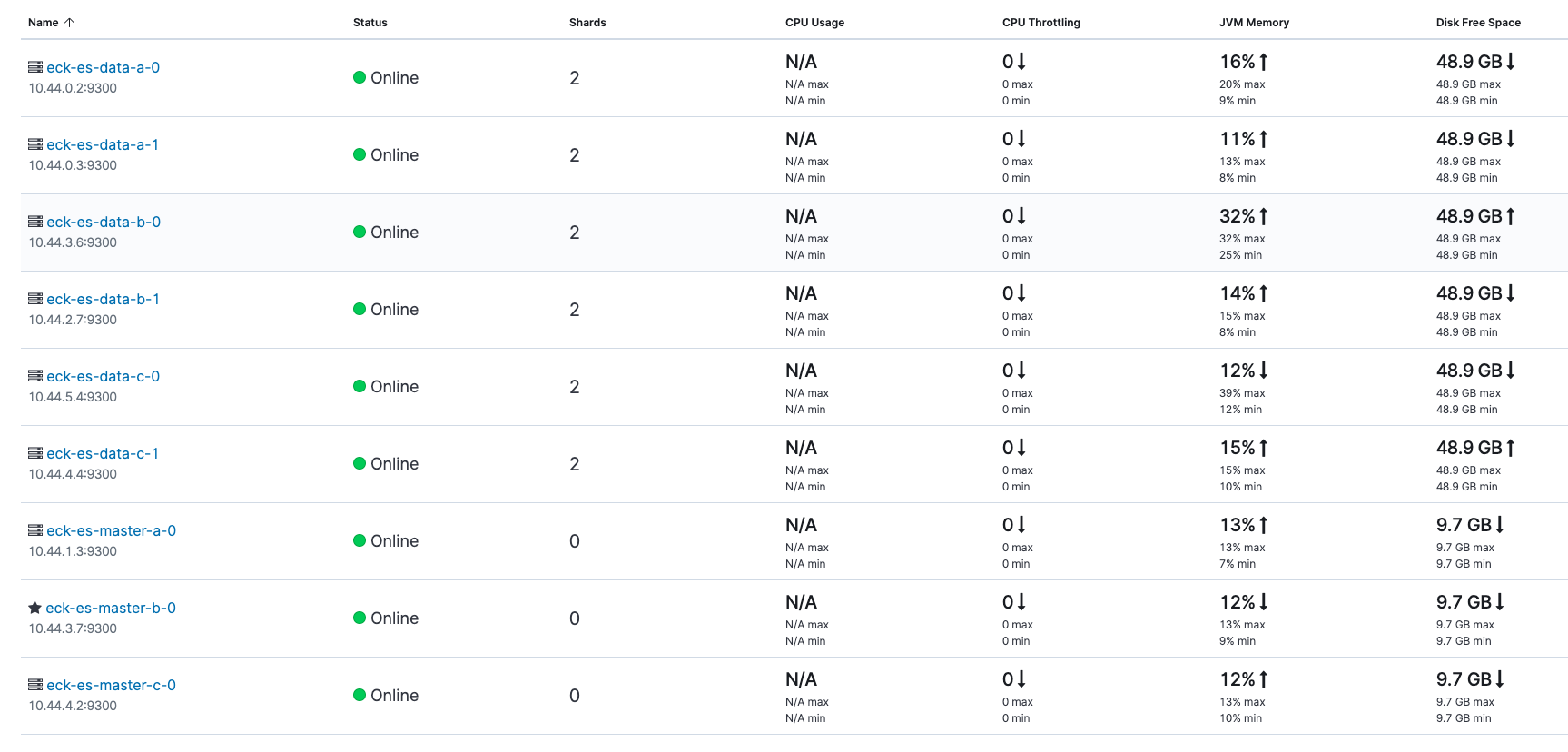
Shardが1Zoneで揃う&ReplicaがZoneを跨いでいる
初期状態では何もShardが無いので以下のようにしてShardの設定とダミーデータの挿入を行いますが、その前にAPIのエンドポイントへもport-forward設定を行います。
$ kubectl port-forward service/eck-es-http 9200
Forwarding from 127.0.0.1:9200 -> 9200
Forwarding from [::1]:9200 -> 9200
shard_conf.json にはShard4, Replica2の設定内容が入っています。つまり4分割されたデータが3重に用意され、想定通りの動きならばReplicaがZoneを跨いで分散配置されるはずです。
$ curl -sS -u elastic:$PASSWORD --insecure -X PUT "https://localhost:9200/twitter" -H 'Content-Type: application/json' -d @shard_conf.json | jq
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "twitter"
}
$
$ curl -sS -u elastic:$PASSWORD --insecure -X POST "https://localhost:9200/twitter/_doc" -H 'Content-Type: application/json' -d @data.json | jq
{
"_index": "twitter",
"_type": "_doc",
"_id": "Mr_G324BjoDhhBoJ9Ht7",
"_version": 1,
"result": "created",
"_shards": {
"total": 3,
"successful": 3,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
そしてKibanaでIndicesタブ内の twitter を開き下の方にあるShard Legendを見るとShardがどのノードに配置されているかわかる画面があるかと思います。ノード名のアルファベットからどのZoneかわかるので「Replicaが同じZoneにいないこと(同じZone内に2つの番号が無いこと)」且つ「1つのZone内で全てのShardが揃うこと(全てのZoneにそれぞれ0, 1, 2, 3があること)」を確認します。
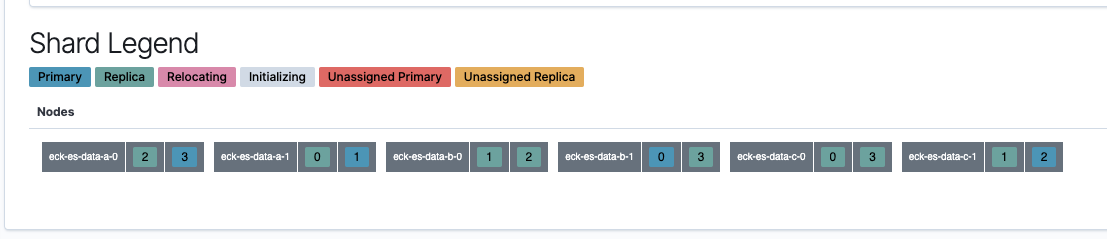
Podを落としても復旧する
では障害試験をやってみましょう。まずはMasterのPodを一つ落とします。
$ kubectl delete pod eck-es-master-a-0
pod "eck-es-master-a-0" deleted
$
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
eck-es-data-a-0 1/1 Running 0 109m
eck-es-data-a-1 1/1 Running 0 109m
eck-es-data-b-0 1/1 Running 0 109m
eck-es-data-b-1 1/1 Running 0 109m
eck-es-data-c-0 1/1 Running 0 109m
eck-es-data-c-1 1/1 Running 0 109m
eck-es-master-a-0 0/1 Init:0/1 0 10s
eck-es-master-b-0 1/1 Running 0 109m
eck-es-master-c-0 1/1 Running 0 109m
kibana-kb-67679bf955-z4sdr 1/1 Running 0 109m
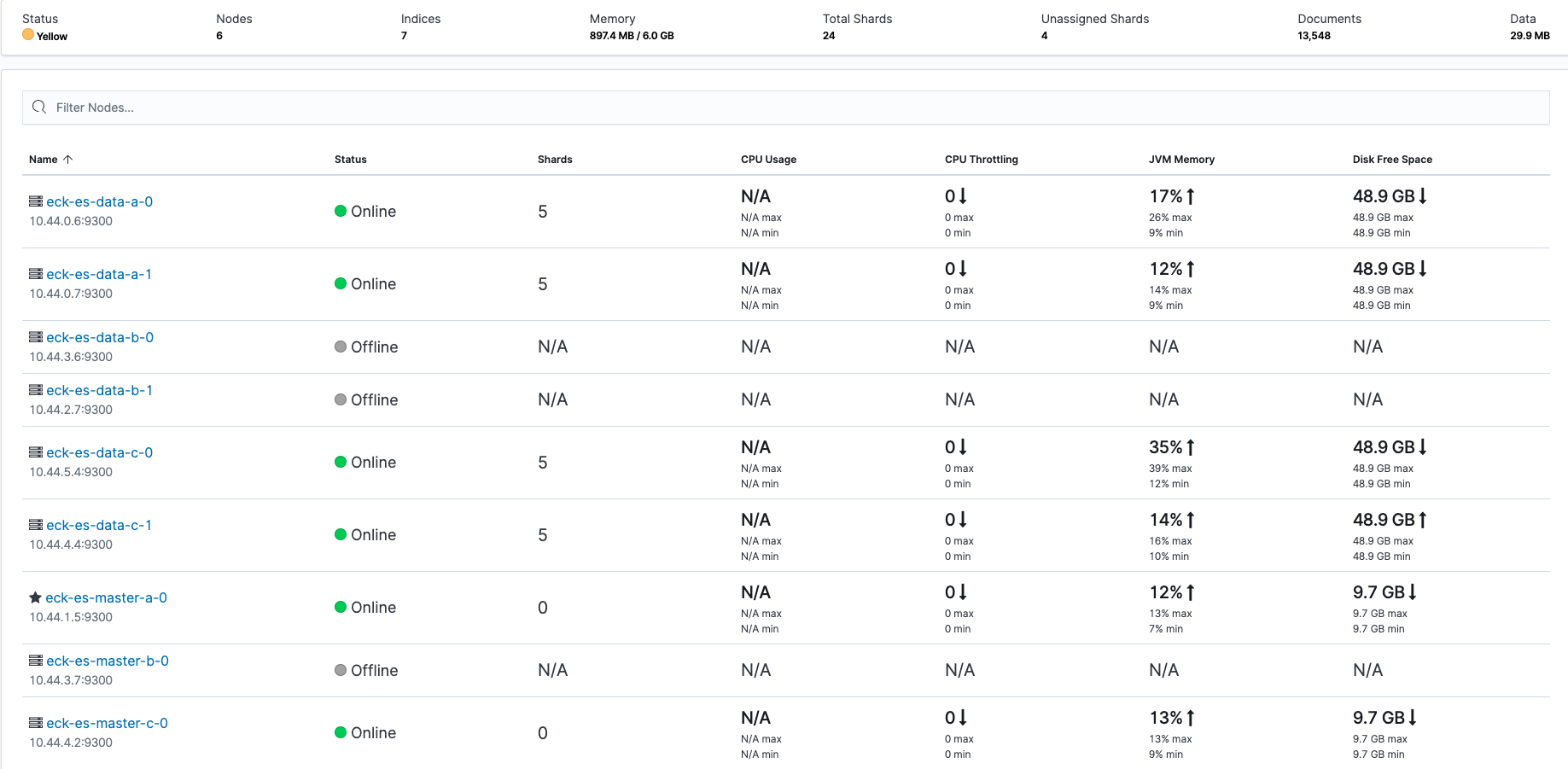
すぐにPodの再開が開始されますが、この最中にKibanaを覗いてみるとZone aのノードがOfflineになっています。Pod復旧後、これがOnlineに戻ればOKです。同様にしてDataでもやってみましょう。なおMasterの一部がダウンしただけなのでHealthはGreenのままで正常です。
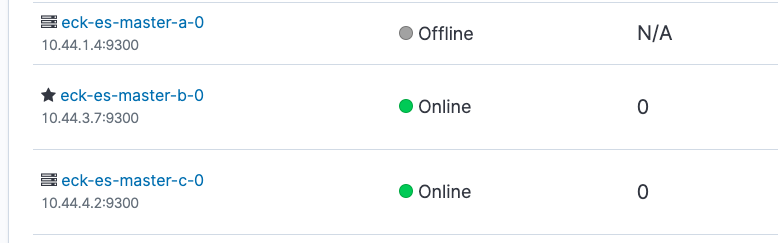
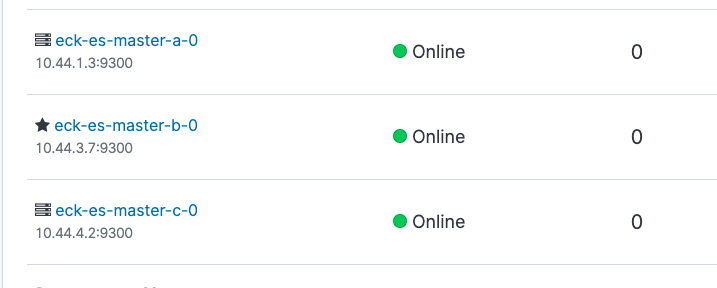
$ kubectl delete pod eck-es-data-a-0
pod "eck-es-data-a-0" deleted
データ用のPodを落とした場合、Replicaが配置しきれなくなるのでHealthはYellowになります。しかし他のノードでReplicaを参照できデータの欠損は起きないためRedにはなりません。
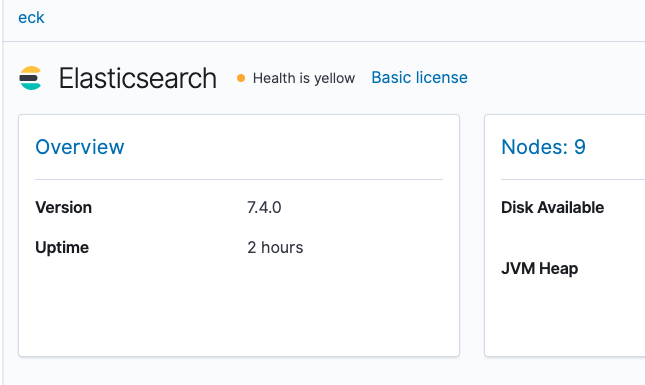

ZoneのVMを全部落としても復旧する
次はもう少し厳し目にやってみましょう。Zone障害を想定してVMを両方共シャットダウンしてしまいます。GKEのNode poolで動くVMはInstance groupで管理されているためGUIから操作することはできないので、SSHでログインして落とす必要があります。GUI上にあるSSHボタンを使ってブラウザから操作するのが手っ取り早いでしょう。GCEの画面からZone bに属するVMにSSHでログインし sudo halt を叩きます。
目論見通りZone bのノードがNotReadyになりKibana上でHealthがYellowになりました(Shard Allocation Awarenessのおかげで欠損が起きていない)が、GKEのauto-repairが発動するまで10分ほどかかるのでコーヒーを豆から淹れたりシャワーを浴びる等一休みしながら待ちます。kubectlでノードの状態がReadyに復帰しKibana上でもOnlineに戻っていればOKです。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-default-cluster-default-pool-10751bd4-c54r NotReady <none> 149m v1.13.11-gke.14
gke-default-cluster-default-pool-10751bd4-xs7k NotReady <none> 149m v1.13.11-gke.14
gke-default-cluster-default-pool-2e3a585c-4vmd Ready <none> 149m v1.13.11-gke.14
gke-default-cluster-default-pool-2e3a585c-zkrn Ready <none> 149m v1.13.11-gke.14
gke-default-cluster-default-pool-74cd1ba7-1lsv Ready <none> 149m v1.13.11-gke.14
gke-default-cluster-default-pool-74cd1ba7-ff5x Ready <none> 149m v1.13.11-gke.14

結論
- Elasticsearch on Kubernetesはインフラ基盤の仕様を考慮した設定が必須
- Kubernetes側ではPodと永続ディスクを特定のZoneに縛ること
- Elasticsearch側ではShard Allocation AwarenessでZoneを識別してデータを分散させること
- 当たり前ですがElastic Cloud(SaaS)で要件を満たせないかギリギリまで検討しましょう

- GCPにデプロイできるので外部サービスといえど遅延は最小限のはず