はじめに
この記事では個人的に前々から気になっていたブラウザ自動操作ツールのPlaywrightを触って、簡単なツールを作成してみたという内容です。
調べながら作成したので、ところどころ非推奨な書き方などあるかもしれませんが、甘い目で見てください、、
Playwrightとは
PlaywrightとはWebブラウザの操作を自動化することができるライブラリです。E2Eフレームワークと言ってテストの自動化で使用されるみたいです。(私は実務では使用したことがありません。)
ボタンの押下やフォームへの入力、画面キャプチャの生成など様々なことを自動で行えます。
Webブラウザの操作自動化といえばSeleniumが思いつきますが、他にもあるんですね。勉強不足。
JavaScriptやPythonなど様々な言語に対応しており、調べるとJavaScriptで書いている記事が多かったのですが、一応自分がJavaをメインで使用しているので今回はJavaで書いてみました。
早速触ってみる
公式ドキュメントなどを参考にしながらとりあえずコードを書いてみました。
とりあえずグーグルの検索画面から検索ワードを入力して、スピードスターと名高い阿部寛さんのホームページにアクセスするプログラムを作成しました。
【環境】
OS:Windows11
言語:Java
フレームワーク:Spring boot
パッケージ管理:Maven
まずはpom.xmlにPlaywrightを追加します
<dependency>
<groupId>com.microsoft.playwright</groupId>
<artifactId>playwright</artifactId>
<version>1.40.0</version>
</dependency>
Maven installするとMaven依存関係にPlaywrightが追加されていることを確認できました。
以下、コードです。
package com.example.demo.controller;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.microsoft.playwright.Browser;
import com.microsoft.playwright.BrowserType;
import com.microsoft.playwright.Locator;
import com.microsoft.playwright.Page;
import com.microsoft.playwright.Playwright;
@RequestMapping("/sample")
@RestController
public class Sample {
@PostMapping(value="/post")
public void getJsonValue() {
try(Playwright playwright = Playwright.create()) {
// ブラウザ起動
Browser browser = playwright.chromium().launch(new BrowserType.LaunchOptions().setHeadless(false));
Page page = browser.newPage();
// グーグル検索ページを開く
page.navigate("https://google.com/");
Locator locator = page.getByTitle("検索");
// 検索フォームに検索ワードを入力
locator.fill("阿部寛 ホームページ");
locator.press("Enter");
// 検索結果で出てくるリンクをクリック
page.click("a[href='https://d1d76jlpbzebww.cloudfront.net/']");
// 阿部寛様鑑賞タイム(処理停止)
page.waitForTimeout(10000);
}
}
}
最初にPlaywright.create()でPlaywrightインターフェイスの実装クラスであるPlaywrightImplを生成することから始まります。
その後にplaywright.chromium().launch()でブラウザを起動しています。ブラウザはChrome以外にfirefoxなどにも対応しているみたいです。
Pageインスタンスを生成することができたらいよいよブラウザ操作の処理を書いていきます。
Locatorインスタンスの要素を設定して検索ワード入力から検索結果の表示までを書いています。
メソッド名もわかりやすく直観的に書けるのは良いですね。
処理が終了するとブラウザが閉じてしまうのでしばしの阿部寛様鑑賞タイム処理を添えて作成完了です。
実行してみた結果が以下になります。
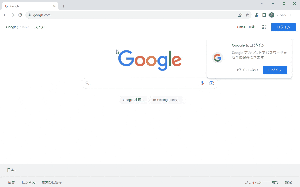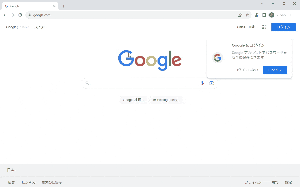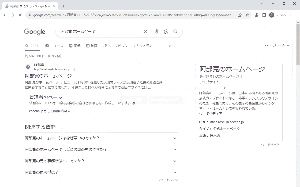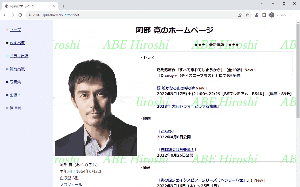
無事にホームページを自動で表示させることができました。
さすがの表示速度ですね。
ちなみにBrowserTypeインターフェイスに定義されているConnectOptionsクラスのslowMoをlaunchの引数に設定すると実行速度を遅くすることができるようです。
せっかくなので簡易的なツールを作成してみた
見出しの通りPlaywrightを使用して簡易的なツールを作成してみました。
Playwrightの概要を知りたかっただけの人はここでブラウザバックでOKです。
どんなツールか
Webページのキャプチャを自動で取得して保存するツール
作成背景
現在参画している案件がセキュリティが厳しく外部のWebページを参照することができないかつ電子機器も持ち込めない状況で調べものをすることが大変、、
幸いなことに完全に環境が構築されるまでは外部ネットワークに繋がるので今の内に使用技術のドキュメントや良記事のキャプチャをローカルに保存しておいていつでも見れるようにしておこうと思いましたが、たくさんのページの保存を手動でやるのは面倒と感じ、ツールを作ろうと思ったのがきっかけです。
完全に自分用のツールです。
ツール概要
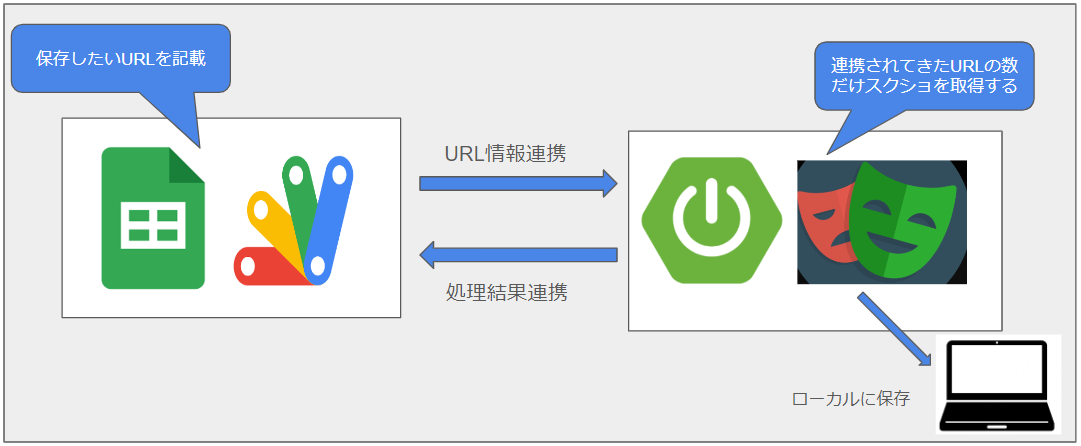
おおまかな処理の流れは図の通り。
スプレッドシートにキャプチャを取得したいURLを記載し、それをSpringにAPI連携し、Playwrightで取得し保存という流れ。
【環境】
OS:Windows11
ツール:スプレッドシート
クライアント側言語:GAS
ホスト側言語:Java
ホスト側フレームワーク:Spring boot
ホスト側パッケージ管理:Maven
トンネリングサービス:ngrok
スプレッドシートを使用した理由はGoogleアカウントがあればどのPCからでもURLを残しておいて、後でまとめてSpringのAPIに連携できると思っただけです。
トンネリングサービスのngrokは「エングロック」と呼ぶらしく、めちゃくちゃ簡単に言うと、ローカル開発環境で実行されているWebサーバーに対して、一時的にインターネットからのアクセスを可能にするものです。
アクセス用のURLが作成され、そこに対してアクセスすると外部からローカル環境のアプリケーションを利用することができます。
デプロイする必要がないので開発中のAPIを試したい時などに使えそうですね。
いろいろ試しましたがGASからローカルにアクセスできず、個人利用するだけなのでngrokを使用し、値の連携を可能にしました。
クライアント側
まずはスプレッドシートに必要な情報を記載していきます。
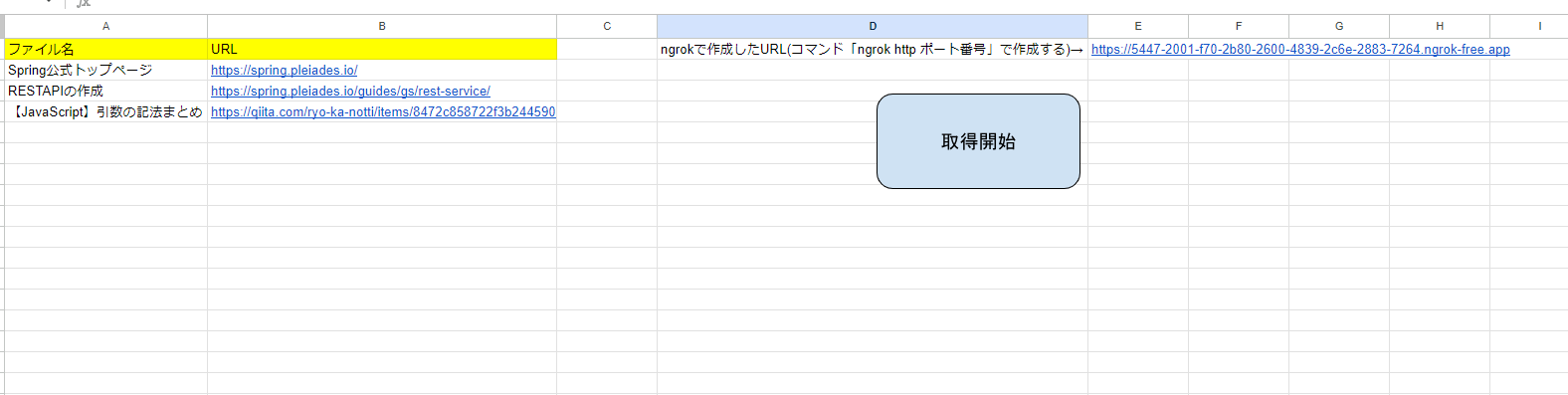
URLと保存するときのファイル名を連携するため、A,B列に必要な情報を記載します。
E1セルにはngrokで生成したURLを記載します。(ngrokを停止するとURLは無効になり、起動するたびに新しいURLが生成されるため)
必要情報を記載し、取得開始ボタンを押すと処理が走ります。
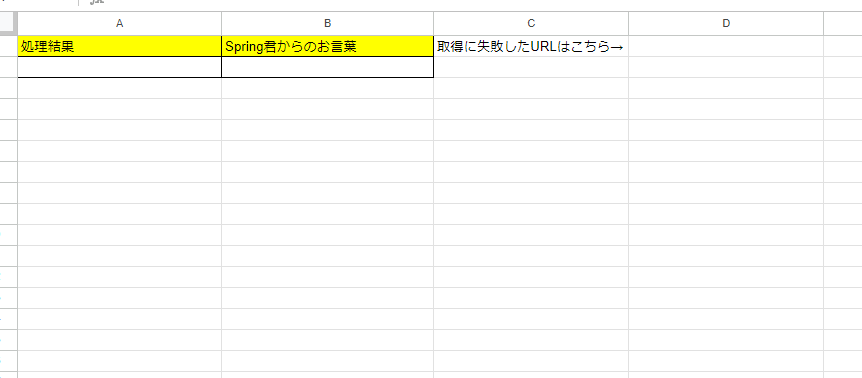
処理結果が返ってくると別シートに処理結果の詳細が記載されるようにしました。
処理結果で返ってくるのは「処理結果コード」「メッセージ」「取得失敗URL」の3つです。
キャプチャ取得に失敗した場合は対象のURLがわかるようにD列に列挙されるようにしました。
取得開始ボタンを押したときに実行されるGASのコードです。
一応、データ不足や先頭がhttpでないか、ファイル名重複などはチェックし、JSON形式のデータを作成し、Springに連携しています。
処理結果が返ってきたらそれを処理結果シートに記載しています。
function sendCaptureData() {
class CaptureData {
constructor(fileName, url) {
this.fileName = fileName;
this.url = url;
}
}
// シートの取得
const executionSheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('実行');
const resultSheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName('処理結果');
//前回処理結果をクリア
resultSheet.getRange("A2:B2").clearContent();
resultSheet.getRange("D1:D" + resultSheet.getRange(resultSheet.getMaxRows(), 4).getNextDataCell(SpreadsheetApp.Direction.UP).getRow()).clearContent();
// 取得範囲の開始行番号
let startRowNumber = 2;
// 取得範囲の開始列番号
let startColumnNumber = 1;
// 取得範囲の最終列番号
let endColumnNumber = 2;
// 取得範囲の最終行
let lastRow = executionSheet.getLastRow();
// データの取得
if((lastRow - 1) == 0 ) {
Browser.msgBox("データが設定されていません。処理を終了します。");
return;
}
const values = executionSheet.getRange(startRowNumber, startColumnNumber, lastRow - 1, endColumnNumber).getValues();
// Springに連携するオブジェクトの生成
const captureDataArray = [];
// ファイル名の配列(重複チェック用)
const fileNameArray = [];
for (let i = 0; i < values.length; i++) {
// 要素不足チェック
if(values[i][0] == '' || values[i][1] == '') {
Browser.msgBox("ファイル名とURLの要素数が一致していません。処理を終了します。");
return;
}
// URLの形式チェック
if(!values[i][1].startsWith("http://") && !values[i][1].startsWith("https://")) {
Browser.msgBox("URLの形式ではない文字列が含まれているので処理を終了します。");
return;
}
// ファイル名重複チェック
if(fileNameArray.indexOf(values[i][0]) != -1) {
Browser.msgBox("重複しているファイル名があるため処理を終了します。");
return;
}
captureDataArray.push(new CaptureData(values[i][0], values[i][1]));
}
// オブジェクトの表示(デバッグ用)
for (const CaptureData of captureDataArray) {
console.log("object", CaptureData.fileName, CaptureData.url);
}
// 作成したリンクデータを送信する
const options = {
"method" : "POST",
"headers" : { "Content-Type": "application/json"},
"payload" : JSON.stringify({
"captureData" : captureDataArray
}),
}
const url = executionSheet.getRange("E1").getValue() + "/capture/post";
const response = JSON.parse(UrlFetchApp.fetch(url, options));
// 処理結果を「処理結果」シートに記載
const resultCode = response.resultCode;
switch(resultCode) {
case 0:
resultSheet.getRange("A2").setValue("正常");
break;
case 1:
resultSheet.getRange("A2").setValue("データなし");
break;
case 2:
resultSheet.getRange("A2").setValue("不正なデータ");
break;
case 3:
resultSheet.getRange("A2").setValue("キャプチャ取得失敗データあり");
let lastRow = 1;
for (const failureUrl of response.failureUrl) {
// 取得失敗したURLを記載
resultSheet.getRange("D" + lastRow).setValue(failureUrl);
lastRow += 1;
}
break;
case 4:
resultSheet.getRange("A2").setValue("エラー");
break;
}
resultSheet.getRange("B2").setValue(response.message);
Browser.msgBox(response.message);
}
ホスト側
続いて、Spring側の実装です。
プロジェクトの構造はこちら
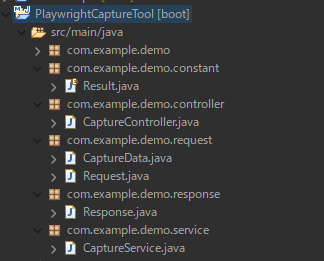
まずはGASからのリクエストを設定するRequestクラス↓
package com.example.demo.request;
public class Request {
private CaptureData[] captureData ;
public Request() {
}
public Request(CaptureData[] captureData) {
this.captureData = captureData;
}
public void setCaptureData(CaptureData[] captureData) {
this.captureData = captureData;
}
public CaptureData[] getCaptureData() {
return this.captureData;
}
}
レスポンスに含む処理結果コードとメッセージを定義しているenum↓
package com.example.demo.constant;
public enum Result {
// 正常終了
NORMAL(0, "正常に終了しました。"),
// データなし
NO_DATA(1, "データが連携されていません。"),
// 不正なデータ
ILLEGAL_DATA(2, "不正なデータが含まれています"),
// キャプチャ取得失敗データあり
PARTIAL_FAILURE(3, "いくつかのキャプチャの取得に失敗しました。"),
// エラー
ERROR(4, "エラーが発生しました。"),;
private int resultCode;
private String message;
public int getResultCode() {
return this.resultCode;
}
public String getMessage() {
return this.message;
}
private Result(int resultCode, String message) {
this.resultCode = resultCode;
this.message = message;
}
}
GASに返す処理結果を表すクラス↓
resultCodeとmessageには上記のenumの値が入ります。
failureUrlはキャプチャ取得に失敗したURL情報を格納します。
PARTIAL_FAILURE以外はnullを設定します。
package com.example.demo.response;
public class Response {
private int resultCode;
private String message;
private String[] failureUrl;
public Response() {
}
public Response(int resultCode, String message) {
this.resultCode = resultCode;
this.message = message;
}
public int getResultCode() {
return this.resultCode;
}
public void setResultCode(int resultCode) {
this.resultCode = resultCode;
}
public String getMessage() {
return this.message;
}
public void setMessage(String message) {
this.message = message;
}
public String[] getFailureUrl() {
return this.failureUrl;
}
public void setFailureUrl(String[] failureUrl) {
this.failureUrl = failureUrl;
}
}
ここからはリクエストを受領してからの処理を書いているコントローラとサービスです。
package com.example.demo.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import com.example.demo.constant.Result;
import com.example.demo.request.Request;
import com.example.demo.response.Response;
import com.example.demo.service.CaptureService;
@RequestMapping("/capture")
@RestController
public class CaptureController {
@Autowired
CaptureService captureService;
/**
* GASからJSONデータを受け取りキャプチャを取得する
*
* @param request GASから受けとったリクエスト
* @return 処理結果
*/
@PostMapping(value="/post")
@ResponseBody
public Response getCapture(@RequestBody Request request) {
System.out.println("request受領");
Response response = new Response();
// データ存在チェック
if(request.getCaptureData().length == 0) {
response = captureService.createResponse(response, Result.NO_DATA, null);
return response;
}
// 不正データチェック
if(captureService.isValidCaptureData(request.getCaptureData())) {
response = captureService.createResponse(response, Result.ILLEGAL_DATA, null);
return response;
}
// キャプチャ取得処理
response = captureService.getCapture(request.getCaptureData());
return response;
}
}
コントローラではGASからリクエストを受け取ってCaptureServiceのメソッドを呼び出すことでバリデーションやキャプチャ取得処理を行っています。
最後に処理結果をGASに返して処理は終了です。
以下は実際のチェック処理とキャプチャ取得処理を記載しているサービスクラス。
package com.example.demo.service;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
import org.springframework.stereotype.Service;
import com.example.demo.constant.Result;
import com.example.demo.request.CaptureData;
import com.example.demo.response.Response;
import com.microsoft.playwright.Browser;
import com.microsoft.playwright.BrowserType;
import com.microsoft.playwright.Page;
import com.microsoft.playwright.Playwright;
import com.microsoft.playwright.PlaywrightException;
@Service
public class CaptureService {
/**
* リクエストのデータが不正なデータでないかチェックする.
* 不正なデータだった場合はtrueを呼び出し元に戻す.
*
* @param captureData リクエストに含まれるキャプチャデータ
* @return チェック結果
*/
public boolean isValidCaptureData(CaptureData[] captureData) {
return Stream.of(captureData).anyMatch(cd -> {
boolean flag = false;
// 要素不足チェック
if(cd.getfileName() == null || cd.getUrl() == null) {
flag = true;
}
// ファイル名重複チェック
if(captureData.length != Stream.of(captureData).distinct().count()) {
flag = true;
}
// URLの形式チェック
if(!cd.getUrl().startsWith("http://") && !cd.getUrl().startsWith("https://")) {
flag = true;
}
return flag;
});
}
/**
* キャプチャを取得する.
* 取得に失敗したURLはリストで保持し、取得失敗したURLとしてクライアントに返却する.
*
* @param captureDataArray リクエストに含まれるキャプチャデータ
* @exception PlaywrightException Playwright実行に関するException
* @exception Exception その他Exceptioin
* @return 処理結果
*/
public Response getCapture(CaptureData[] captureDataArray) {
// 取得に失敗したURL件数
int failureCount = 0;
// 取得に失敗したURLのリスト
List<String> failureCapureDataUrlList = new ArrayList<>();
// httpステータス200
int httpStautsOk = 200;
Response response = new Response();
try(Playwright playwright = Playwright.create()) {
// ブラウザの起動
Browser browser = playwright.chromium().launch(new BrowserType.LaunchOptions().setHeadless(false));
Page page = browser.newPage();
for(CaptureData captureData : captureDataArray) {
try {
System.out.println(captureData.getUrl() + "のキャプチャ取得開始");
// URLにアクセスし、成功した場合にキャプチャを取得する
if (page.navigate(captureData.getUrl()).status() == httpStautsOk) {
page.screenshot(new Page.ScreenshotOptions()
.setPath(Paths.get("C:\\Users\\User\\Documents\\playwrightキャプチャ\\" + captureData.getfileName() + ".png"))
.setFullPage(true));
System.out.println("キャプチャ取得完了");
} else {
System.out.println("キャプチャ取得失敗。httpStatus=200以外");
// 取得失敗したURLをリストに保持する
failureCount += 1;
failureCapureDataUrlList.add(captureData.getUrl());
};
} catch(PlaywrightException e) {
System.out.println("キャプチャ取得失敗。URLアクセス時にエラー発生");
// 取得失敗したURLをリストに保持する
failureCount += 1;
failureCapureDataUrlList.add(captureData.getUrl());
}
}
if(failureCount >= 1) {
String[] failureCapureDataUrlArray = failureCapureDataUrlList.toArray(new String[failureCapureDataUrlList.size()]);
response = createResponse(response, Result.PARTIAL_FAILURE, failureCapureDataUrlArray);
} else {
response = createResponse(response, Result.NORMAL, null);
}
} catch(Exception e) {
System.out.println("エラーが発生しました。");
e.printStackTrace();
response = createResponse(response, Result.ERROR, null);
}
return response;
}
/**
* クライアントに返す処理結果を作成する.
* 一部キャプチャ取得に失敗した場合のみ、失敗したURLも設定する.
*
* @param response 処理結果のインスタンス
* @param result 処理結果のenum
* @param failureUrl キャプチャ取得に失敗したURL
* @return 値を設定した処理結果のインスタンス
*/
public Response createResponse(Response response, Result result, String[] failureUrl) {
response.setResultCode(result.getResultCode());
response.setMessage(result.getMessage());
if(failureUrl != null) {
response.setFailureUrl(failureUrl);
}
return response;
}
}
バリデーションを行うisValidCaptureData()とキャプチャ取得を行うgetCapture()レスポンスを作成するcreateResponse()を作成しました。
Playwrihtを使用した部分について特に最初の阿部寛さんのサンプルと比べて目新しいのはありませんので、キャプチャを取るところだけ解説します。
Pageインターフェースのscreenshot()で表示しているWebページのキャプチャを取得することができます。
引数にPage.ScreenshotOptions().setPath()にパスを指定することで好きなディレクトリにキャプチャを保存することができます。
また、setFullPage(true)とすると表示部分だけでなくWebページ全体を保存することができます。
これで完成です。
あとはngrokを起動してGASの処理を実行します。
ngrokのインストールから実行まではこちらに丁寧に記載されていますので気になる方は読んでみてください。
起動直後のところから。
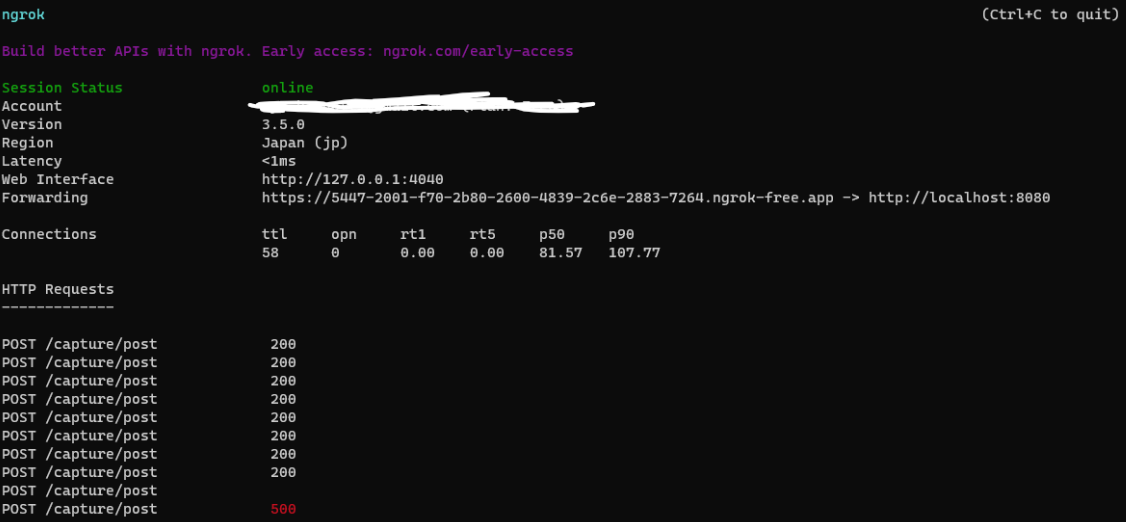
既にリクエストをいくつか投げた後がありますが、Forwardingのところに記載されているURLが公開用のURLです。
早速実行してみましょう。
取得開始ボタンを押します。

正常に終了したようです。処理結果シートを見てみましょう。
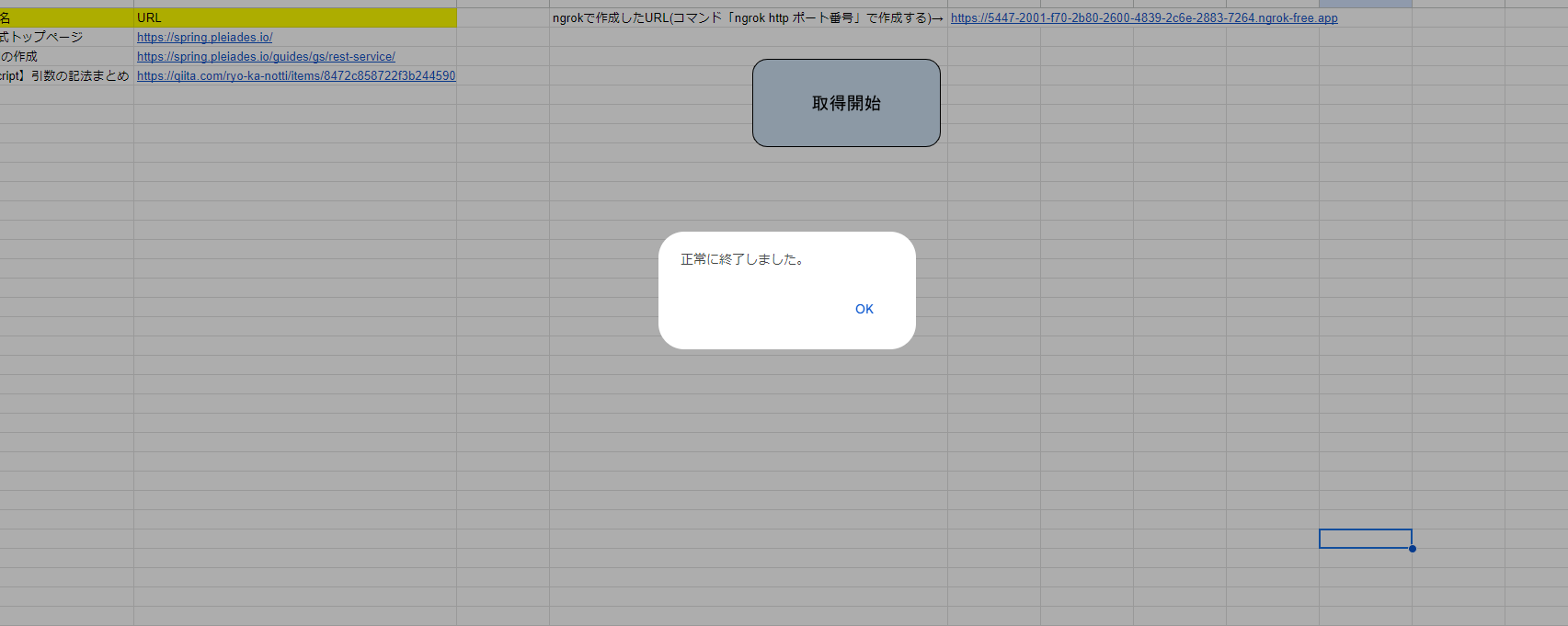
処理結果とそれに対応するメッセージが記載されています。

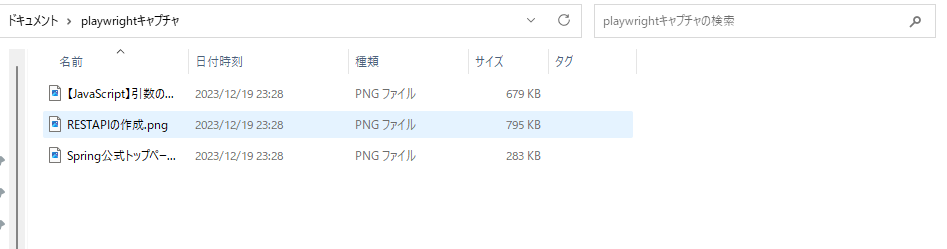
指定したパスにもしっかりキャプチャが保存されていますね。
一部キャプチャの取得に失敗した場合も見てみましょう。
先ほどの3つのURLに加えて適当なURLを記載しておいて取得開始ボタンを押します。

メッセージが変わりました。処理結果シートを見てみましょう。
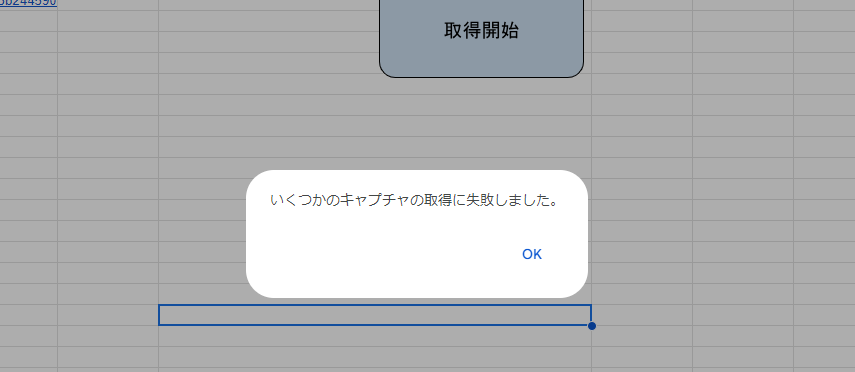
ちゃんと失敗用の処理結果とメッセージが記載されていて失敗したURLも残されています。
うまくいきました。

終わりに
自動操作は前々から気になっていたので触っていてとても楽しかったです。
今回書いたこと以外にもさまざまなことができるようなので気になる人は触ってみると良いかもしれません。
いつか実務でもテスト自動化してみたいと思いました。