概要
学部3年の時に作ったアプリに関する書き起こしです.
電車で移動する間など,イヤホンをして音楽を聴くことが多いかと思います.
みなさんは,どのくらいの音量で聴きますか?大音量で聴きたい派の方もいるでしょう.
僕は,周囲の音も少し聴こえる程度の音量が好みです.
音楽が聴こえないのは悲しいですし,逆に,常に大音量なのも鬱陶しいからです.
気がつけば,車内でボリュームボタンをカチカチし続けている自分がいました.
面倒なので,音楽等の再生音量を,周囲の騒音より少し大きい程度に自動調整するアプリを作成することにしました.
実現方法
基本原理
スマートフォン(Android)のアプリケーションとして形にしました.
スマホのマイクを用いて周囲の音量を測定し,再生音量決定モデル(後述)によって再生音量を決定し,音量を変更しています.
AudioManager とか AudioRecord とかを使います.
まず,周辺音量を何ミリ秒ごとに測るかという問題があります.短すぎると正しく周辺音量を取得できないでしょう.
次に,(周辺音量を取得->再生音量の変更)のサイクルをどのくらいの頻度で行うかという問題もあります.高頻度すぎると短時間に音量が変化しすぎて鬱陶しいです.
いろいろ試しましたが,結論として,周辺音量の取得は100ミリ秒に1度,何度か計測した値のうちの最大値として得ることにしました.それを10回繰り返し,それら計測値の平均値を最終的な周辺音量値として扱うようにしました.
都合,(周辺音量を取得->再生音量の変更)のサイクルは1000ミリ秒毎に行われます.
この処理はソースコードを読んだ方がわかりやすいかもしれません.
このサイクルを実行するソースコードは次の通りです.
package com.gmail.axis38akasira.autovolumer;
import android.os.Handler;
import android.support.annotation.NonNull;
import android.widget.TextView;
import com.gmail.axis38akasira.autovolumer.notifications.NotificationWrapper;
class VolumeManager implements Runnable {
private AudioResources aRes;
private Handler handler;
private TextView textView_envVol, textView_playingVol;
private NotificationWrapper notificationWrapper;
private int micSenseCnt = 0, micSenseSum = 0;
VolumeManager(@NonNull AudioResources aRes, @NonNull Handler handler,
@NonNull TextView textView_envVol, @NonNull TextView textView_playingVol,
@NonNull NotificationWrapper notificationWrapper) {
this.aRes = aRes;
this.handler = handler;
this.textView_envVol = textView_envVol;
this.textView_playingVol = textView_playingVol;
this.notificationWrapper = notificationWrapper;
}
@Override
public void run() {
if (aRes.getMicAccessAllowed()) {
final short[] buffer = aRes.readByAudioRecorder();
// 最大
int max_val = Integer.MIN_VALUE;
for (short x : buffer) {
max_val = Math.max(max_val, x);
}
// 何度も計測して,平均値をその時間間隔の間の計測結果とする
micSenseSum += max_val;
if (micSenseCnt != 9) micSenseCnt++;
else {
final double inputLevel = micSenseSum / 10.0;
micSenseSum = 0;
micSenseCnt = 0;
textView_envVol.setText(String.valueOf(inputLevel));
final int outLevel = aRes.applyPlayingVolume(inputLevel, textView_playingVol);
if (outLevel != -1) {
notificationWrapper.post(
MainActivity.class, "音量の自動調整が有効",
notificationWrapper.getActivity().getString(R.string.vol_playing)
+ String.valueOf(outLevel)
);
}
}
}
handler.postDelayed(this, 100);
}
}
再生音量決定モデル
まず,周囲の音量レベルから再生音量を決定する関数のようなものを作成することを考えました.
このとき,もしも再生音量のステップ数が全てのデバイスで同じ(かつ,OSがアップデートしてもそれが変わらないと保証されている)なら,ifをいくつか書けば簡単に実現できそうです.
Input: 周辺音量
return: 再生音量
func 再生音量決定関数:
if 周辺音量 < 750:
return 0
if 周辺音量 < 3750:
return 1
if 周辺音量 < 9750:
return 2
(再生音量のステップ数だけつづく)
しかし,それを仮定するのは難しい(し,安直すぎておもしろくない)と感じました.
そこで,出力を実数値まで拡張した連続関数の形で,周囲の音量レベルから再生音量を導く数理モデルを作成することにしました.
具体的には,周辺音量レベルの最大音量に対する割合を実数値で返すモデルを作成することを試みました.
まず,実機(Samsung Galaxy Feel SC-04J)を用いて,周囲の音量に対する,理想的な再生音量(の,最大音量に対する割合)を測定しました.
(とは言っても,境界部分を調べるだけです.これから作る関数が広義単調増加になることは直感的に明らかですから)
測定結果を元に,周辺音量と再生音量の対応データをでっち上げます.これを可視化した散布図がこちらです.
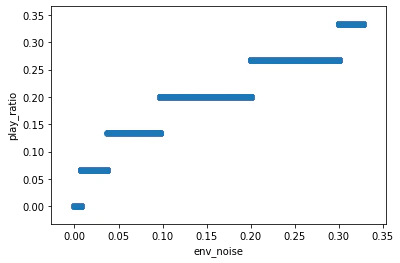
マイクからの入力音量レベルは符号付16bit整数型で与えられるため,範囲は[0, 32767)です.あとで処理しやすいよう,横軸を素の音量レベル*10^5にしています.
このデータを元にモデルをフィットさせて,次のような,滑らかないい感じの関数(?)を得たいと思います.
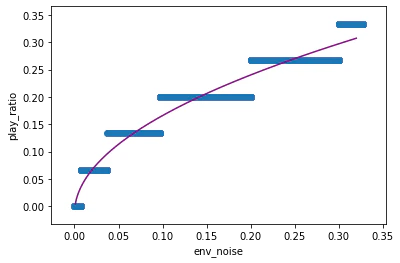
段々な形になって欲しくないので,NNのような表現力の高いモデルは避け,極力単純なモデルを用います.
候補として,次の関数を用意しました.
a+bx \\
a+bx+cx^2 \\
a+b \sqrt{x} \\
a+b \log{x}
Jupyter Notebook 上で学習させて,精度と学習後のパラメータを見てみます.
# a + bx にフィット
from sklearn.linear_model import LinearRegression
lr = LinearRegression().fit(np.array(x).reshape(-1, 1), y)
print(lr.score(np.array(x).reshape(-1, 1),y), lr.intercept_, lr.coef_)
# a + bx + cx^2 にフィット
lr2 = LinearRegression().fit(np.dstack((np.power(np.array(x),2),np.array(x)))[0], y)
print(lr2.score(np.dstack((np.power(np.array(x),2),np.array(x)))[0],y), lr2.intercept_, lr2.coef_)
# a + b sqrt(x) にフィット
lr3 = LinearRegression().fit(np.array(np.sqrt(x)).reshape(-1, 1), y)
print(lr3.score(np.array(np.sqrt(x)).reshape(-1, 1),y), lr3.intercept_, lr3.coef_)
# a + b log(x) にフィット
log_r = LinearRegression().fit(np.array(np.log(x[1:])).reshape(-1, 1), y[1:])
print(log_r.score(np.array(np.log(x[1:])).reshape(-1, 1),y[1:]), log_r.intercept_, log_r.coef_)
精度,定数項,係数
0.9566515430381373 0.05703034713007743 [0.85320093]
0.9858850873387448 0.035720497728703726 [-1.91782117 1.43981898]
0.9981469854250034 -0.013011305980174026 [0.56593706]
0.9695780780725732 0.39569447022473625 [0.09291432]
グラフにして可視化してみる.
# グラフ描写
RNG = np.linspace(0, 0.32, 100)
DIV_NUM = 15 # デバイス毎に異なる,再生音量の最大値
plt.figure(figsize=(18,9))
plt.xlabel("env_noise")
plt.ylabel("play_level")
plt.scatter(df["騒音"]/100000, df["再生音量"]/DIV_NUM, label="data")
plt.plot(RNG, lr.intercept_ + lr.coef_ * RNG, label="a+bx", color="green")
plt.plot(RNG, lr2.intercept_ + lr2.coef_[1] * RNG + lr2.coef_[0] * RNG * RNG, label="a+bx+cx^2", color="red")
plt.plot(RNG, lr3.intercept_ + lr3.coef_ * np.sqrt(RNG), label="a+ b sqrt(x)", color="purple")
plt.plot(RNG, log_r.intercept_ + log_r.coef_ * np.log(RNG), label="a+ b log(x)", color="cyan")
plt.legend(loc='upper left', prop={'size':20})
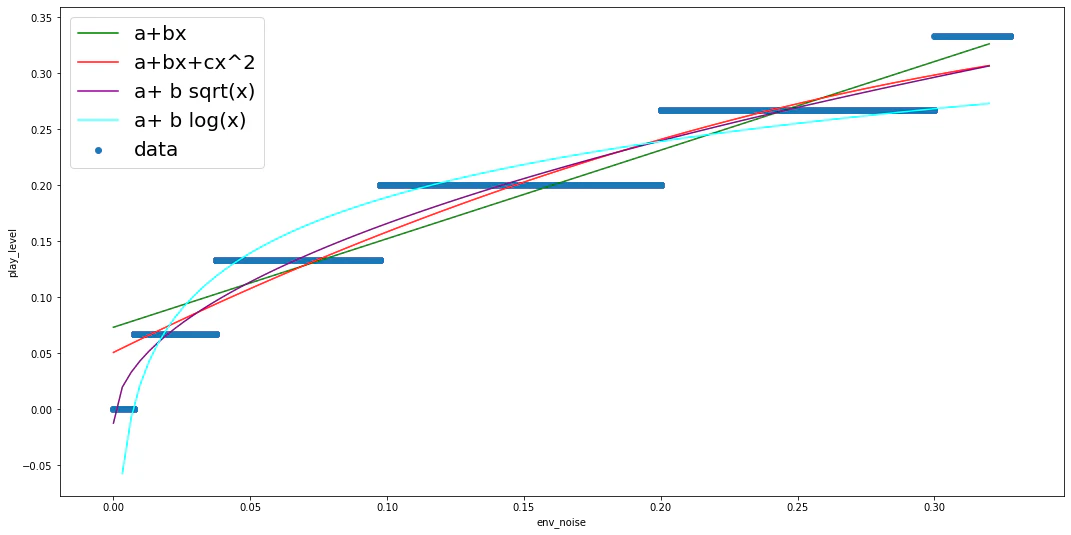
どれがええんかわからんやん!
実際に再生音量を決定するときには,(最大音量*音量の割合)を計算した後,それを整数にする必要がある.そこで,その計算を行った後の再生音量(整数値)を散布図に表示し,測定されたデータとの差異を確認しました.
# 騒音から再生音量を求める関数を用いて,実際にデバイスの再生音量を決定してみる
# 関数の値を四捨五入して整数化
RNG = np.linspace(0.001, 0.32, 500)
DIV_NUM = 15 # デバイス毎に異なる,再生音量の最大値
plt.figure(figsize=(18,12))
plt.scatter(df["騒音"]/100000, df["再生音量"], label="data")
plt.plot(RNG, np.round(DIV_NUM * (lr.intercept_ + lr.coef_[0] * RNG)), label="a+bx round", color="green")
plt.plot(RNG, np.round(DIV_NUM * (lr2.intercept_ + lr2.coef_[1] * RNG + lr2.coef_[0] * RNG * RNG)), label="a+bx+cx^2 round", color="red")
plt.plot(RNG, np.round(DIV_NUM * (lr3.intercept_ + lr3.coef_ * np.sqrt(RNG))), label="a+ b sqrt(x)", color="purple")
plt.plot(RNG, np.round(DIV_NUM * (log_r.intercept_ + log_r.coef_ * np.log(RNG))), label="a+ b log(x)", color="cyan")
plt.legend(loc='upper left', prop={'size':20})

$a+b \sqrt{x}$ を使った場合が正しい再生音量を決定できているように見えますので,これを選びました(本当はもっと定量的に判断したい).
フィットした時の結果から,このとき
\begin{align}
a &= 0.56593706 \\
b &= -0.013011305980174026
\end{align}
であることがわかります.最後に,これを用いる機能をアプリに追加します.
(変数名が微妙に違いますが察してください)
package com.gmail.axis38akasira.autovolumer;
class RegressionModel {
private final static double[] beta = {-0.012529002932674477, 0.56377634};
static Double infer(final double x) {
return beta[0] + beta[1] * Math.sqrt(x);
}
}
UI
適当にアクティビティを作りました.

有効かどうかわかりやすい方が良いと思い,通知にも状態がでるようにしました,

ソースコード
ここ
https://github.com/ryhoh/SmartVolumer
まとめ
個人的には便利なアプリに仕上がりました.モデルの決定方法がこれで良かったのかなと心残りです.
スマホのマイクを用いることで実現しましたが,スマホをカバンに入れた場合などは当然効きが悪くなります.本当はイヤホンに近い位置にマイクが付いていれば理想的です.
その点,僕はワイヤレスイヤホンで利用していますが,マイク内蔵型のワイヤードイヤホンを用いた場合にはどうなるのか気になります.