はじめに
今回は、身長+スリーサイズをもとに、セクシー女優のカップ数を推定していきます。
NNを使って何かをやってみたのは初めてなので、どうかお手柔らかにお願い申し上げます。。
環境
| 項目 | 値 |
|---|---|
| OS | Windows 10 Home |
| Python | 3.6.2 |
| Chainer | 3.4.0 |
| jupyter | 4.3.0 |
使用したデータ
こちらで使用されているデータセットになります。複数シートがありますが、その中の欠損値を取り除いたバージョンです。
全部で2200名程度となります。
データ収集された方に大変感謝申し上げます。
データ公開ページには、以下の記事から辿れます。
データ内容としては、Dカップが偏って多いとのことです。
Pythonでエロサイトスクレイピングして、AV女優のビッグデータからスケベなインサイトを見出す - Qiita
https://qiita.com/kkdmgs110/items/593b9a2a270734d06070
学習
手法
学習は3層ニューラルネットワークで行います。入力データに対しては、「BatchNormalization」という、標準偏差と平均を基に正規化を行う手法を適用しています。今回用いたニューラルネットワークを下図に示します。
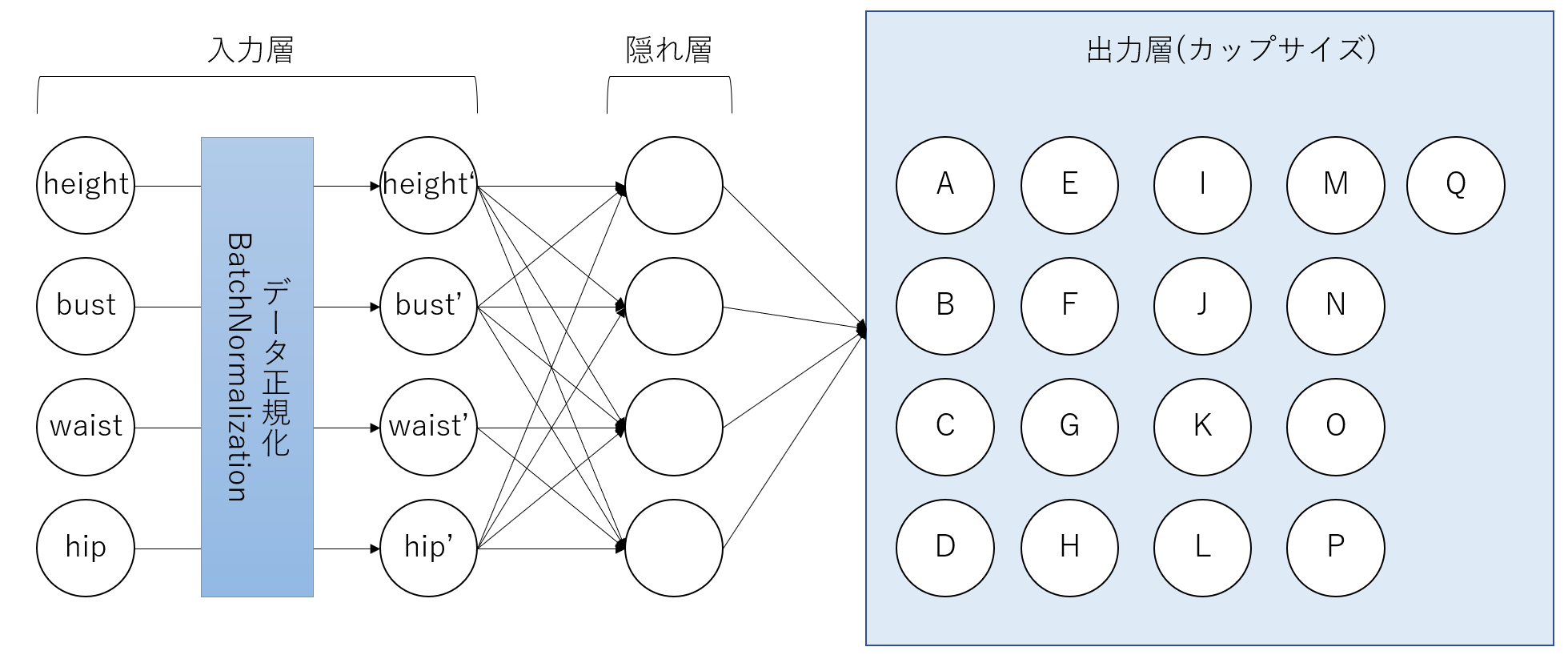
コード
以下のコードで学習させていきます。実行はjupyter上で行っています。
# coding: utf-8
import pandas as pd
# データ読み込み
df = pd.read_csv('dataset.csv')
# 教師データ(cupnum列)
t = df.iloc[:, 6]
# 入力変数(3~6番目)
x = df.iloc[:, 2:6]
# 確認
t.head(3)
# 確認
x.head(3)
# Numpyにデータ型を変換
tn = (t.values - 1).astype('int32')
xn = x.values.astype('float32')
import chainer
# Chainer指定の各サンプル毎に(x,t)とタプル形式で保存する
dataset = list(zip(xn, tn))
# 訓練データのサンプル数
n_train = int(len(dataset) * 0.7)
# 訓練データ(train)と検証データ(test)に分割
train, test = chainer.datasets.split_dataset_random(dataset, n_train, seed=1)
import chainer.links as L
import chainer.functions as F
class NN(chainer.Chain):
# モデルの構造を明示
def __init__(self):
super().__init__()
with self.init_scope():
self.l1 = L.Linear(4, 4)
self.l2 = L.Linear(4, 17)
self.bn1 = L.BatchNormalization(4) # BatchNormalizationを定義
# 順伝播
def __call__(self, x):
u1 = self.l1(self.bn1(x))
z1 = F.relu(u1)
u2 = self.l2(z1)
return u2
import numpy as np
# 再現性確保のためシードを固定
np.random.seed(1)
# NNモデルをインスタンス化
nn = NN()
model = L.Classifier(nn)
from chainer import optimizers
# 最適化にはSGDを使用
optimizer = optimizers.SGD()
optimizer.setup(model) # modelと紐付ける
# iteratorsの設定
batchsize = 20
train_iter = chainer.iterators.SerialIterator(train, batchsize)
test_iter = chainer.iterators.SerialIterator(test, batchsize, repeat=False, shuffle=False)
# updaterの設定
updater = chainer.training.StandardUpdater(train_iter, optimizer, device=-1)
# trainerとそのextensionsの設定
from chainer import training
from chainer.training import extensions
# trainerの基本設定
epoch = 100
trainer = training.Trainer(updater, (epoch, 'epoch'), out='result')
# 評価データで評価
trainer.extend(extensions.Evaluator(test_iter, model, device=-1))
# 学習結果の途中を表示する
trainer.extend(extensions.LogReport(trigger=(1, 'epoch')))
# 1エポックごとに、trainデータに対するaccuracyと、testデータに対するaccuracyを出力させる
trainer.extend(extensions.PrintReport(['epoch', 'main/accuracy', 'validation/main/accuracy', 'elapsed_time']), trigger=(1, 'epoch'))
# 学習の実行
trainer.run()
結果
精度について
概要
精度は40%手前という結果になりました。
epoch20くらいまで急激に上昇しましたが、その後は微増に転じ、epoch60~80で飽和しました。
推移グラフ
推移のグラフを以下に示します。
青は訓練データに対する正解率、オレンジは検証データに対する正解率です。
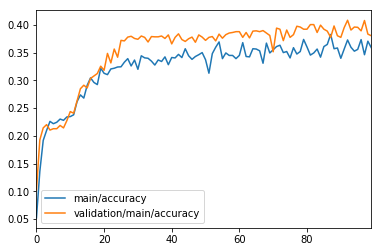
推移の詳細な値
精度に関する詳細な数値を以下に示します。
epoch main/accuracy validation/main/accuracy elapsed_time
1 0.0518987 0.102451 0.130143
2 0.135897 0.192647 0.242791
3 0.191667 0.214216 0.357829
4 0.209615 0.220098 0.474134
5 0.225949 0.210294 0.594562
6 0.221795 0.212745 0.715166
7 0.224359 0.212745 0.827799
8 0.230128 0.218627 0.937838
9 0.227848 0.214216 1.05567
10 0.233974 0.227451 1.16818
11 0.234615 0.243627 1.28491
12 0.237821 0.240686 1.4006
13 0.261392 0.262745 1.51739
14 0.273718 0.284804 1.64686
15 0.267949 0.291176 1.76315
16 0.291026 0.286275 1.87721
17 0.30443 0.303431 1.98985
18 0.296154 0.307843 2.10897
19 0.292308 0.312255 2.22686
20 0.321795 0.32549 2.3425
21 0.312658 0.318137 2.4574
22 0.310256 0.348529 2.58126
23 0.320513 0.331373 2.69891
24 0.321795 0.356373 2.81549
25 0.324051 0.341667 2.93369
26 0.324359 0.372059 3.05993
27 0.332692 0.371078 3.17508
28 0.339103 0.377941 3.28894
29 0.325949 0.379412 3.40697
30 0.336538 0.37549 3.52079
31 0.319872 0.37402 3.64247
32 0.344231 0.379902 3.75547
33 0.340506 0.377451 3.88218
34 0.339744 0.369118 4.01605
35 0.334615 0.378922 4.15818
36 0.327564 0.378431 4.2854
37 0.336709 0.378431 4.41908
38 0.333974 0.379902 4.55167
39 0.342308 0.37549 4.69385
40 0.328205 0.381863 4.85839
41 0.341139 0.365686 5.03962
42 0.340385 0.377451 5.19391
43 0.346795 0.383824 5.31573
44 0.341026 0.373529 5.44716
45 0.356962 0.370098 5.58203
46 0.344231 0.375 5.72504
47 0.337821 0.377941 5.85471
48 0.342949 0.368627 5.97195
49 0.346203 0.381863 6.09869
50 0.35 0.377941 6.21399
51 0.337179 0.372059 6.33287
52 0.312821 0.377451 6.44798
53 0.348101 0.378922 6.57127
54 0.359615 0.371078 6.69257
55 0.369231 0.383333 6.80589
56 0.339103 0.37598 6.92192
57 0.349367 0.382353 7.0525
58 0.344872 0.385294 7.17361
59 0.344872 0.386275 7.29612
60 0.339103 0.387745 7.41108
61 0.344937 0.387745 7.52945
62 0.367949 0.377451 7.65457
63 0.342949 0.386275 7.78553
64 0.342308 0.376471 7.9048
65 0.356962 0.388725 8.03104
66 0.35641 0.389216 8.16293
67 0.353205 0.387745 8.2877
68 0.330769 0.389706 8.40144
69 0.367089 0.385294 8.52047
70 0.349359 0.380882 8.65597
71 0.355128 0.351471 8.77369
72 0.360897 0.394118 8.88568
73 0.363291 0.392157 9.00146
74 0.35 0.371569 9.12215
75 0.351923 0.390686 9.23887
76 0.340385 0.377451 9.35267
77 0.358861 0.382353 9.47811
78 0.347436 0.397549 9.60196
79 0.351923 0.396078 9.7205
80 0.373718 0.392157 9.84158
81 0.360127 0.392157 9.96736
82 0.345513 0.40049 10.0894
83 0.349359 0.40049 10.2114
84 0.35641 0.386275 10.3242
85 0.341772 0.39951 10.4411
86 0.360897 0.392157 10.5563
87 0.364744 0.388725 10.6831
88 0.382692 0.377451 10.8028
89 0.356962 0.398039 10.9219
90 0.358333 0.380392 11.0541
91 0.339744 0.377451 11.1707
92 0.35641 0.395098 11.2858
93 0.372785 0.408333 11.4034
94 0.359615 0.390686 11.5182
95 0.352564 0.396078 11.6378
96 0.355769 0.395588 11.7508
97 0.373418 0.389216 11.8799
98 0.346154 0.407843 11.9948
99 0.370513 0.383333 12.1129
100 0.358974 0.380392 12.2264
結果表示コード
最後に、結果表示で用いたコードを示します。
# logファイルからの結果の読み込み
import json
with open('result/log') as f:
logs = json.load(f)
results = pd.DataFrame(logs)
# 確認
results.head(3)
# プロットをインライン表示
get_ipython().magic('matplotlib inline')
# Accuracy(精度)を表示
results[['main/accuracy', 'validation/main/accuracy']].plot()
カップ数予測トライ!
セクシー女優の方から、数人をピックアップしてカップ数の推定させてみます。
Rioさん(H:154, B:84, W:58, H:83, C cup)の場合
cup_table = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q']
# Rio
# 予測
xq = np.array([[154,84,58,83]], 'f')
# 予測値の計算
y = model.predictor(xq)
# Softmax関数で確率の総和が1になるように変換
F.softmax(y).data
cup_table[np.argmax(F.softmax(y).data)]
'D'
正解Cに対して推定Dと出てきてしまいました、、惜しい
蒼井そらさん(H:155, B:84, W:58, H:83, G cup)の場合
# 蒼井そら
# 予測
xq = np.array([[155,90,58,83]], 'f')
# 予測値の計算
y = model.predictor(xq)
# Softmax関数で確率の総和が1になるように変換
F.softmax(y).data
cup_table[np.argmax(F.softmax(y).data)]
'D'
正解Gに対してまたしてもDカップ。Dが多いからこの結果なのか…?
なればこそ、Dの女優くらいは正確に予測できるはず…
石原莉奈さん(H:155, B:85, W:56, H:84)の場合
# 石原莉奈
# 予測
xq = np.array([[155,85,56,84]], 'f')
# 予測値の計算
y = model.predictor(xq)
# Softmax関数で確率の総和が1になるように変換
F.softmax(y).data
cup_table[np.argmax(F.softmax(y).data)]
'D'
やっと正解。一安心。
ところで、Bが小さい方はどうなんだろうか。
野中あんりさん(H:154, B:74, W:56, H:84)の場合
# 野中あんり
# 予測
xq = np.array([[154,74,56,84]], 'f')
# 予測値の計算
y = model.predictor(xq)
# Softmax関数で確率の総和が1になるように変換
F.softmax(y).data
cup_table[np.argmax(F.softmax(y).data)]
'D'
これは、、、Dしか出ないようになっているのか、、、?
Bが大きければどうなるのだろうか?
さくら柚木さん(H:157, B:115, W:68, H:94)の場合
# さくら柚木
# 予測
xq = np.array([[157,115,68,94]], 'f')
# 予測値の計算
y = model.predictor(xq)
# Softmax関数で確率の総和が1になるように変換
F.softmax(y).data
cup_table[np.argmax(F.softmax(y).data)]
'D'
もしかして'D'しか返さない関数なのでしょうか。
まとめ
あんまり高い精度は得られませんでした。
原因としては、以下が考えられます。(根拠は不明ですが)
- データ面
- セクシー女優というか、人間がDカップに偏りすぎていること
- 身長+スリーサイズとカップ数は、思ったより相関が小さいかもしれない
- 実験手法面
- カップ数という連続性のある値にもかかわらず、回帰ではなく分類で学習させてしまったため
まあ細かく分析は行っていないため真の原因は不明ですが、、
所感
NNを今まで使ったことがなく、何かに使ってみようということで使ってみました。
初めてChainerを使用してみましたが、それにしては使いやすかったんじゃなかと思います。
読んでいただきありがとうございました。