文字化け(もじばけ)とは、コンピュータで文字を表示する際に、正しく表示されない現象のこと。
(Wikipediaより)
1番身近な文字化けの例はcsvファイルをExcelで開いたときではないでしょうか?
こんなとんでもないことに遭遇したことはありませんか?
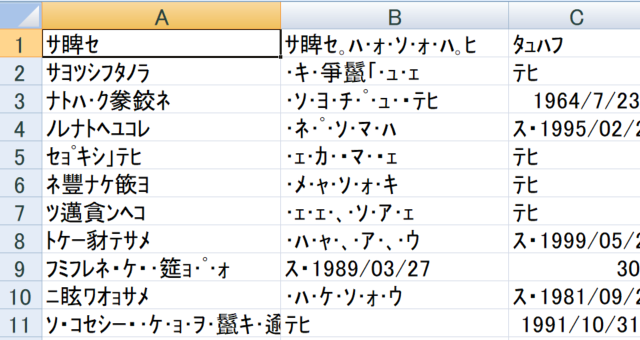
一体何が起きているのでしょうか?
ファイルが壊れてしまったのでしょうか?
この文字化けがどんな理由で起きるのか、どう対処すればいのかを解説します。
なぜ文字化けするのか?
ひと言で言うと、文字化けの多くはファイルの文字コードと異なる文字コードで開こうとしたときに起こります。
いきなり『文字コード』というよくわからない単語が出てきましたね。
まずは文字コードについてざっくり理解してみましょう。
これがわかれば、文字化けの原因も対処法もわかります。
文字コードとは?
私たち人間が**【愛】**という文字をノートに記録するときは、文字を文字として扱います。
当たり前のことですね。
ですが、コンピュータはこの【愛】という文字を文字として扱うことはできません。
コンピュータはデータを0と1の2進数でしか扱えないからです。
では、コンピュータはどのように文字を表現しているのかというと、文字を数字に対応させて扱っているのです。
例えば、次の表のような感じです。
| 文字 | 対応する数字 |
|---|---|
| ! | 21 |
| " | 22 |
| ... | ... |
| A | 65 |
| B | 66 |
| C | 67 |
| D | 68 |
| ... | ... |
【A】という文字は、【65】という数字に、
【!】という記号は、【21】という数字に対応させていることがわかります。
この文字と数字の対応パターンを文字コードといいます。
この対応パターン(文字コード)は1種類ではありません。
先述した文字コード表は『ASCII(アスキー)』という文字コードで、アルファベット・数字・記号しか表にありません。
私のような日本人は「漢字」や「かな」も使いますから、このASCIIでは対応する文字がなくて困ってしまいます。
そこで登場したのが、日本語も扱える文字コードです。
『シフトJIS(SJIS)』や『EUC』が代表的なものです。
ですが、アラビア文字やハングルを扱いたい場合には困ってしまいますね。
このように、各言語圏で文字コードを発明しまくった結果、現在では100種類以上の文字コードが存在しています。
さて、その結果、何が起こるか…。
文字コード同士の互換性の問題です。
【春】はどこへ行った??
例えば、【春】という文字は『EUC』という文字コードでは(16進数表記で)【bdd5】となりますが、SJISでは(16進数表記で)【8f74】となります。
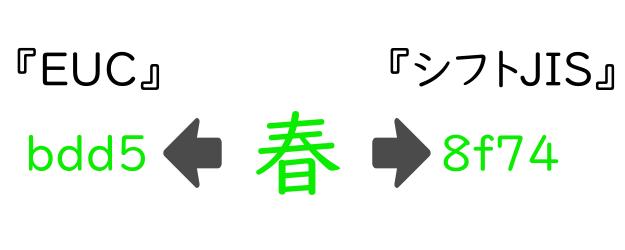
なので、EUCで保存した【春】という文字を、シフトJISで解釈しようとしても、【春】とは別の文字(【スユ】)と認識してしまうのです。
これが文字化けの正体です。
例えるなら、英語で『Come on!』と言われたとき、英語を知らない日本人が『家紋?』と解釈してしまうようなものです。

対処法
原因がわかったところで、対処法に移りましょう。
csvファイルをExcelで開いたら文字化けしてしまったというシーンを想定して対処法を解説します。
まずは本当に文字コードの違いが原因なのかを確認します。
ファイルの文字コードを調べる
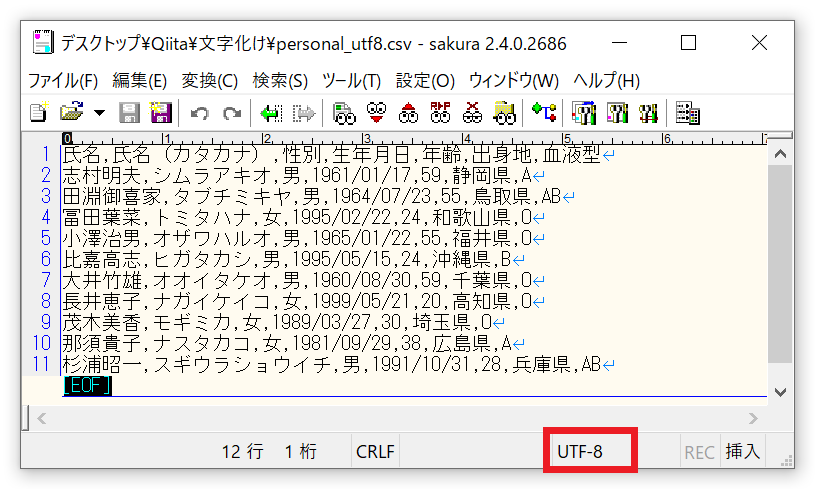
サクラエディタで、該当のcsvファイルを開きます。右下に文字コードが表示されていますので確認しましょう。
ここでは、『UTF-8』という文字コードになっていますね。
実はExcelはデフォルトでは『シフトJIS』としてファイルを開こうとします。
なので、『シフトJIS』以外の文字コードで保存されているファイルでは、文字化けする可能が高いのです。
つまり、このUTF-8の文字コードで保存されているファイルをそのままExcelで開くと文字化けします。
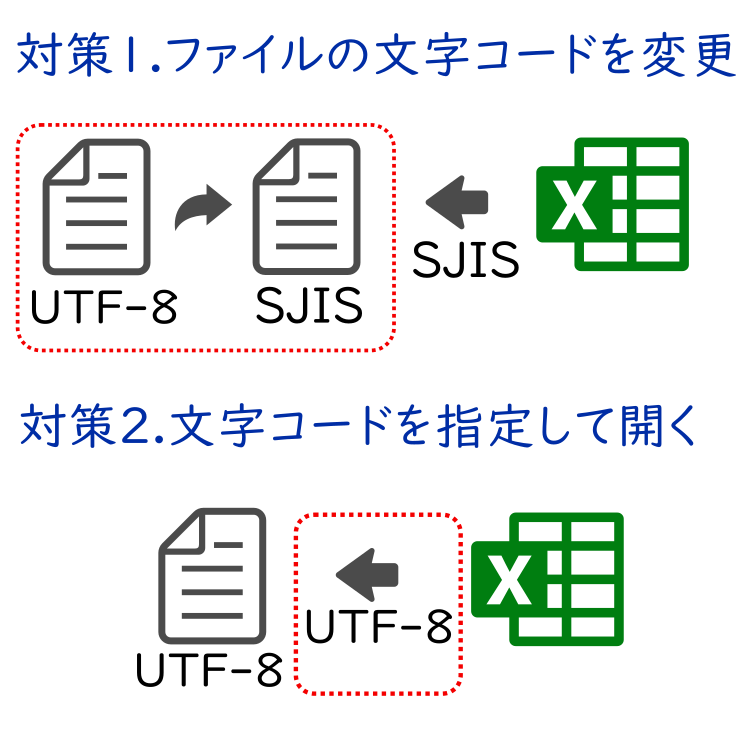
対処法は2つ
対処法ですが、要は文字コードを合わせればいいわけです。
方法としては大きく2つあります。
- csvファイルの文字コードをシフトJISに変更して保存する
- Excelで開くときにcsvファイルの文字コードで開く
対策1. csvファイルの文字コードをシフトJISに変更
サクラエディタでcsvファイルを開きます。(他のエディタでも構いません)
"名前を付けて保存"を選択すると、保存するときの文字コードを選択することができます。ここで、SJIS(シフトJIS)で保存します。
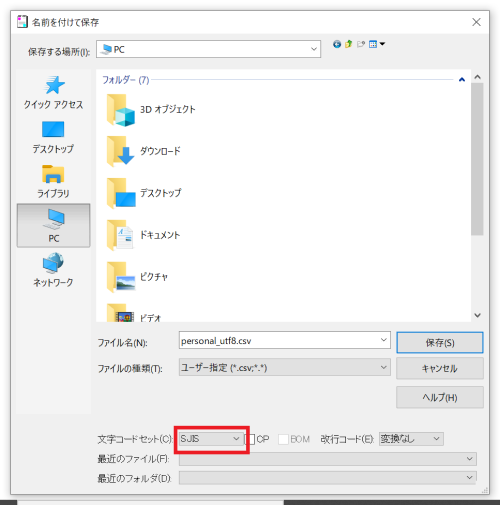
すると、ExcelのデフォルトもシフトJISなので、文字コードが一致することになるため文字化けは起きません。
対策2. Excelで開くときに文字コードを指定する
Excelを起動して「データ」タブから「外部データの取り込み-テキストファイル」を選択します。
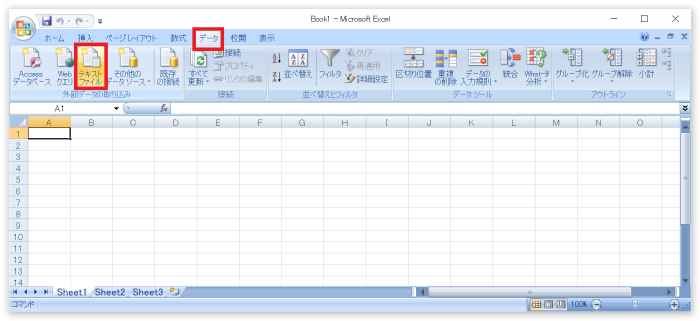
開きたいファイルを選択します。

すると開くときの文字コードを選択する画面になります。ここで、ファイルの文字コードに合わせて選択します。
ここではファイルが『UTF-8』なので『UTF-8』を選択します。
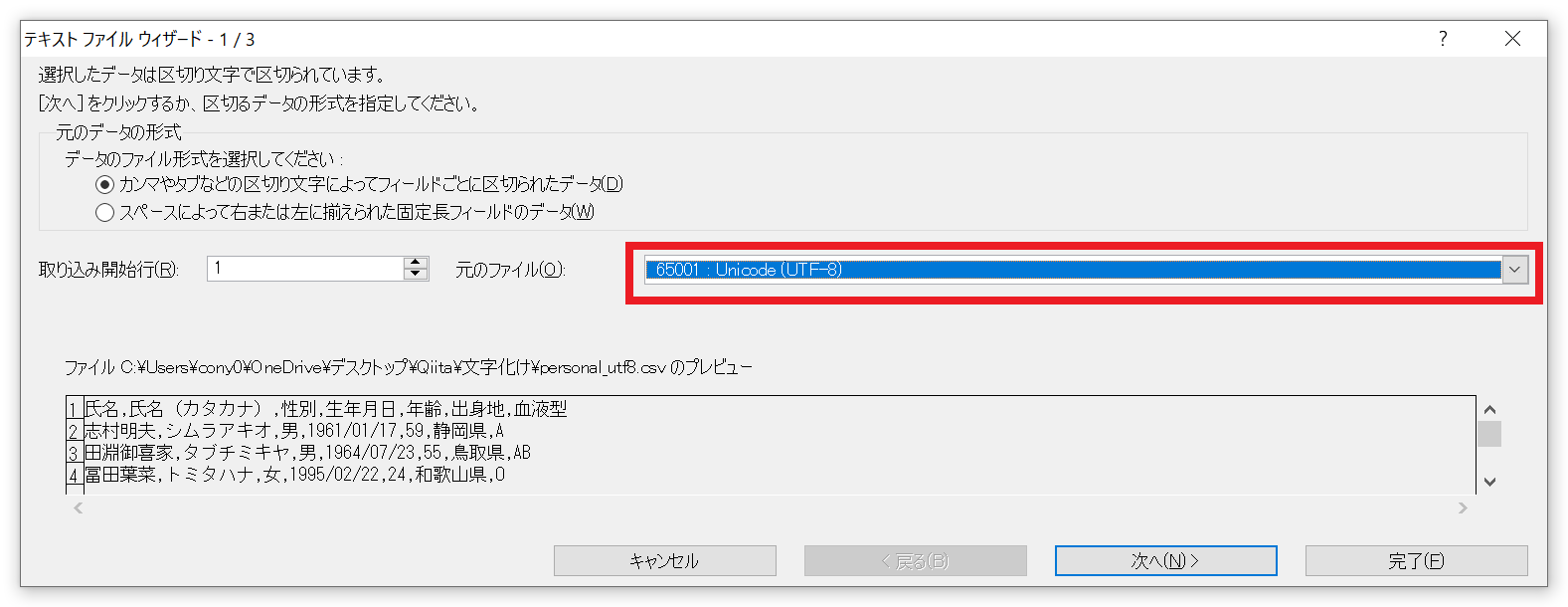
文字化けせずに開くことができましたね。
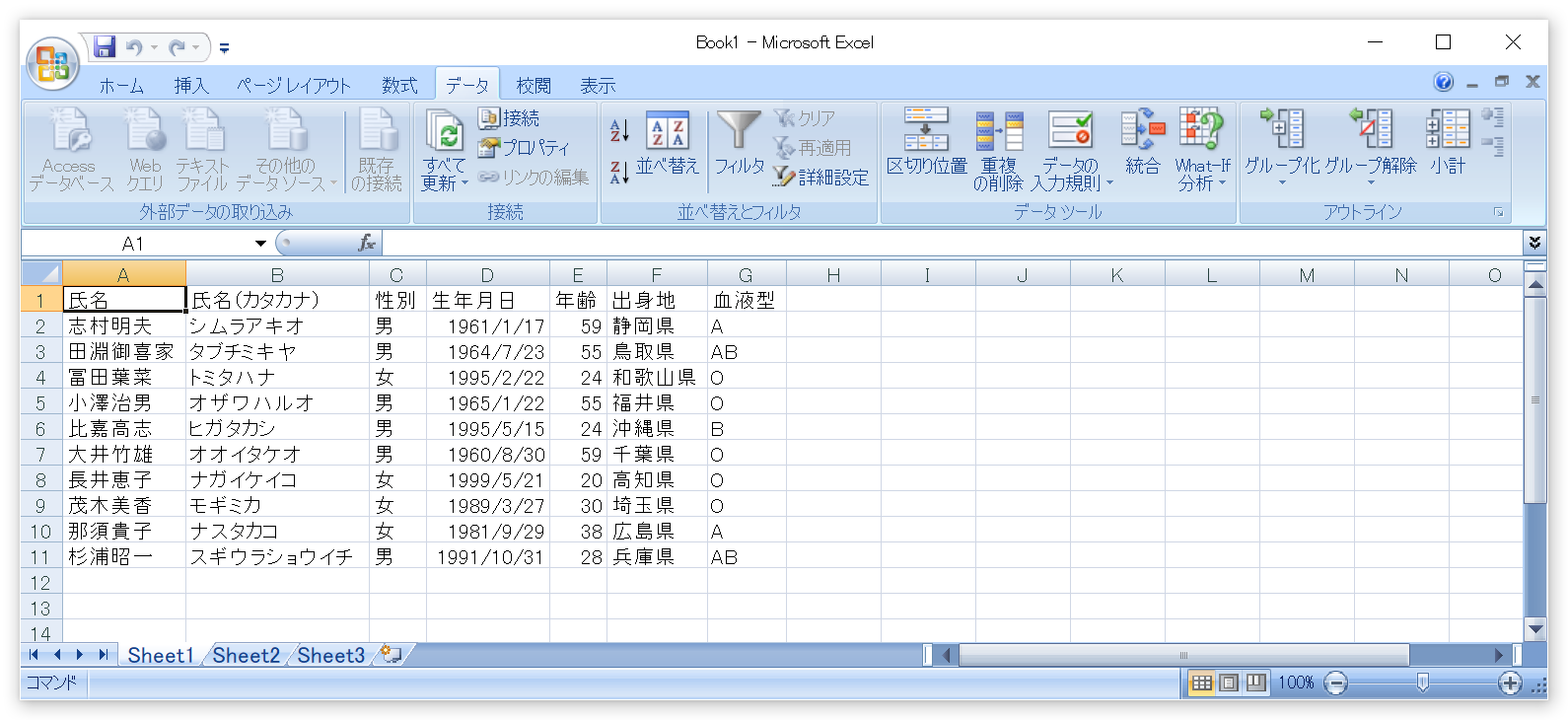
ここから先は、
『EUC』で保存した【春】という文字を『シフトJIS』で開くと【スユ】になってしまう理由についてです。
気になる方は続けてご覧ください。
【春】は【スユ】??
テキストエディタで【春】と書いて文字コード『EUC』で保存します。
これをExcel(『シフトJIS』)で開いてみましょう。

スユって何ですか??
なぜ半角なのか?
なぜ2文字?
いろんな疑問が湧いてきますね。
なぜ【春】が【スユ】に文字化けするのか詳しく見てみましょう。
まず、【春】は『EUC』では(16進数で)bdd5という2バイトで表現されます。
これを『シフトJIS』として解釈するとどうなるでしょうか?
『シフトJIS』では、半角文字を1バイト、全角文字を2バイトで表現します。
単にこれだけだと、2バイトの文字を解釈するときに、それが半角2文字なのか、全角1文字なのか区別ができませんね。
そこで『シフトJIS』では、半角か全角かを見分けるため、1バイトめが(16進数)で81~9fまたはe0~efの範囲であれば全角文字、それ以外なら半角文字とルールを決めています。
bdd5の1バイトめはbdですから、これは『シフトJIS』では全角文字ではない、つまり半角文字だ!と認識されます。
半角文字でbdは【ス】を表しています。
そして、次の1バイトをみるとd5でありこれも全角文字ではありません。つまり半角文字だと判断されるのです。半角文字でd5は【ユ】です。
こうして『春』は『スユ』と無理やり解釈されてしまいます。

どうでしたか?
文字化けもなかなか奥が深いですね。私も今回の記事を書くために色々調べてみて、その奥深さに驚きました!