はじめに
AWS Lambdaは、開発の面ではプログラミングが簡単で、運用の面では変化する使用パターンに迅速に対応できるアプリケーションです。Lambdaの特徴は、関数が安全で、隔離された環境で実行される点です。各環境のライフサイクルは、Init、Invoke、Shutdownという3つの段階で構成されます。
AWS Lambdaのライフサイクルごとの特徴
| Category | Desciption |
|---|---|
| Init | 関数のランタイムをブートストラップし、静的コードを実行 (INIT_REPORT) |
| Invoke | APIリクエストに応答してLambda関数が呼び出される |
| Shutdown | ランタイムを終了。持続時間は2秒に制限され、応答がない場合はShutdown SIGKILLが送信される |

https://docs.aws.amazon.com/images/lambda/latest/dg/images/Overview-Successful-Invokes.png
Init段階
- すべての拡張プログラムを初期化 (例: Datadog、Splunk、Log Insightなど)
- ランタイムをブートストラップ
- 関数の静的コードを初期化
- ランタイムフックの実行 (Lambda SnapStartのみ該当) beforeCheckpoint
ランタイムおよびすべての拡張がAPIリクエストを送信し、準備が整ったことを知らせるとこの段階が終了します。この段階は10秒に制限されます。3つのタスクがすべて実行されない場合、10秒以内に完了しないと、Lambdaは最初の関数時点で段階を再試行します。ほとんどの場合、数ミリ秒で完了しますが、さまざまな理由で時間がかかることもあります。
たとえば、Spring Boot、Quarkus、Micronautのようなフレームワークと共にJavaランタイムを使用するLambda関数のInit段階は、10秒近くかかる場合があります (依存性の注入、関数コードのコンパイル、およびクラスパスコンポーネントのスキャンを含む)。
Cold Startとは?
AWS Lambdaは、リクエストが発生した時点でインスタンスを起動し、コードを実行します。
コードを実行するには、上記のInit段階が先行する必要があり、これをCold Startと呼びます。
最初のリクエストはCold Startにより多くの時間がかかりますが、2回目以降のリクエストは同じコンテナでコードを実行するだけで済むため、迅速に処理できます。

https://docs.aws.amazon.com/images/lambda/latest/operatorguide/images/perf-optimize-figure-1.png
Cold Startが発生する要因
- 関数への最初のリクエストが発生したとき
- 新しいアプリケーションバージョンのデプロイ時
- 一定期間リクエストがない場合、インスタンスがクリーンアップされ、新しいインスタンスが起動される場合
- 同時呼び出しが発生して利用可能なインスタンスがない場合 (Concurrencyでさらに詳述)
Lambda SnapStartの特徴
- 特定のLambda関数に対してLambda SnapStartを有効にし、新しいバージョンの関数を公開すると、最適化プロセスがトリガーされます。
- プロセスによって関数が起動され、Init段階全体にわたってプロセスが実行されます。
- メモリおよびディスク状態の不変の暗号化されたスナップショットを取得し、再利用できるようにキャッシュします。
- 関数が呼び出されると、必要に応じてキャッシュから状態がチャンク単位で取得され、実行環境を満たすために使用されます。
- 追加料金は発生しません。
結論として、新しい実行環境を作成する際に、専用のInit段階が不要になるため、この最適化により呼び出し時間が短縮され、予測しやすくなります。
SnapStart機能を使用すると、2つのフェーズに分かれて動作します。
- Deploymentフェーズ
- デプロイ中にLambdaはランタイムを生成し、新しいコードでInit作業を実行します。
- 初期化が完了すると、メモリとローカルディスクの状態をスナップショットとして作成します。
- Lambdaバージョンをデプロイする際にaliasを指定してデプロイし、デプロイが完了するまでは以前のバージョンがトリガーされます。
- Invocationフェーズ
- Cold Startの3段階の代わりに、Restore段階が実行され、SnapStartがロードされて初期状態に迅速に復元されます。
- Warm Start条件ではInvoke段階のみが実行されます。
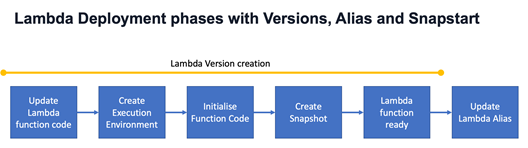
SnapStartの注意点
- 固有性: 乱数データのSeedingに問題があります。固有性を維持する必要がある値がスナップショットに含まれる場合、固有性を維持することができません。例えば、Bootstrap段階で生成された乱数がグローバル変数に保存される場合、その変数はスナップショットに含まれます。すべてのLambda関数が同じ値を使用することになり、固有性が失われます。
これを解決するためには、固有性を維持する必要があるデータをhandler function内で生成するか、ランタイムフックを利用して処理する必要があります。 - キャッシュの持続期間: 14日間使用されない場合、キャッシュが削除されます。ランタイムが更新またはパッチされた場合にスナップショットが変更されると、Lambdaは自動的にキャッシュを更新します。
- 遅延時間に非常に敏感な関数には、Provisioned Concurrencyを使用する方が良いかもしれません。
- Corretto JAVA 11バージョン以降で使用可能です。
- デプロイ時間の増加
フックを利用したInit時間の短縮
オープンソースのCRaCプロジェクトの一環としてランタイムフックが提供されています。
-
BeforeCheckPoint
スナップショットが生成される前の、コード初期化段階で実行されるフックです。
Spring Handlerのグローバル変数を設定するのと似た効果が得られます。例えば、DBから取得した大量のメモリをキャッシュし、beforeCheckpointメソッドを使用してオブジェクトを生成し、データを格納して後で呼び出せるように構成することができます。ただし、古いデータを参照する可能性があります。 -
AfterRestore
AfterRestoreはスナップショットを復元した後に実行されるフックです。
10秒のタイムアウトがあります。DBのコネクションプールを生成するなど、invoke段階の前に実行する必要がありますが、スナップショットよりも最新の状態を維持する必要がある場合に使用できます。
ただし、afterRestoreフックはCold Start時間を延長する可能性があるため、使用時には注意が必要です。
SnapStartのための性能改善
- staticでSpringBootLambdaContainerHandlerを実行
後続のリクエストでもインスタンスを再利用するため、性能を向上させることができます。public class StreamLambdaHandler implements RequestStreamHandler { private static SpringBootLambdaContainerHandler<AwsProxyRequest, AwsProxyResponse> handler; static { try { handler = SpringBootLambdaContainerHandler.getAwsProxyHandler(Application.class); // If you are using HTTP APIs with the version 2.0 of the proxy model, use the getHttpApiV2ProxyHandler // method: handler = SpringBootLambdaContainerHandler.getHttpApiV2ProxyHandler(Application.class); } catch (ContainerInitializationException e) { // if we fail here. We re-throw the exception to force another cold start e.printStackTrace(); throw new RuntimeException("Could not initialize Spring Boot application", e); } } @Override public void handleRequest(InputStream inputStream, OutputStream outputStream, Context context) throws IOException { handler.proxyStream(inputStream, outputStream, context); } } - Tomcatの削除
基本的に、Spring BootプロジェクトにはTomcatサーバーが含まれているため、shadeプラグインを使用して削除します。<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.5.1</version> <configuration> <createDependencyReducedPom>false</createDependencyReducedPom> </configuration> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <excludes> <exclude>org.apache.tomcat.embed:*</exclude> </excludes> </artifactSet> </configuration> </execution> </executions> </plugin> </plugins> - 非同期初期化
非同期イニシャライザは、JVMが起動してからAWS Lambdaがハンドラを生成するまでに経過した時間を推定します。デフォルトではServerless Java Containerは追加で10秒間待機しますが、これを利用して時間を短縮できます。import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.LambdaLogger; import com.amazonaws.services.lambda.runtime.RequestStreamHandler; import java.io.*; public class HandlerStream implements RequestStreamHandler { @Override public void handleRequest(InputStream inputStream, OutputStream outputStream, Context context) throws IOException { LambdaLogger logger = context.getLogger(); BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream, Charset.forName("US-ASCII"))); PrintWriter writer = new PrintWriter(new BufferedWriter(new OutputStreamWriter(outputStream, Charset.forName("US-ASCII")))); int nextChar; try { while ((nextChar = reader.read()) != -1) { outputStream.write(nextChar); } } catch (IOException e) { e.printStackTrace(); } finally { reader.close(); String finalString = writer.toString(); logger.log("Final string result: " + finalString); writer.close(); } } } -
@ControllerAdvice
独自の@ControllerAdviceクラスを使用したい場合は、まず@Applicationクラスで該当する@Bean設定を削除する必要があります。これにより、カスタム例外処理ロジックが優先的に適用されるようになります。 - Cold StartおよびSpring Initializeの最適化
SnapStartを実行しても、Cold Startに応じて速度が若干低下する可能性があります。EventBridgeにWarmer用Lambdaを設定し、SnapStart aliasが適用されたLambdaバージョンをウォーミングします。
さらに、LambdaウォーミングはSpringインスタンスを直接ウォーミングしないため、Health-Check APIを介してSpringインスタンスもウォーミングしました。
ここで、170msはAPI Gatewayでデフォルトでかかる時間です。同じVPCにあるターゲットAPIの場合、約50msに短縮されます。
- SnapStartのみ適用時:1200ms
- SnapStart + Cold Start Warmer invoke適用時:400ms
- SnapStart + Warmer invoke + call Health check適用時:170ms - ComponentScan
Springアノテーションはパッケージを受け取り、そのパッケージ内のすべてのクラスでSpring関連の設定、リソース、およびBeanを自動的にスキャンします。これは開発中には非常に便利ですが、クラスが増えるとその分初期化時間が遅くなります。上記のクラスで始めると、Springは命令文で宣言されたクラス (すでにJVMによってロードされています) のみを検査するため、パッケージ全体をスキャンする重い作業を回避できます。@Configuration @Import({ PetsController.class }) public class PetStoreSpringAppConfig { ... }
個人的には、ドメイン領域が増えるとその分重くなるのは避けられません。しかし、私が使用しているサーバーはドメイン領域コードがシンプルで、コンポーネントも多様ではないため、それほど重くはありませんでした。 - コンストラクタ注入の回避
パラメータ名を関連するBeanに関連付けるためには、Springはデバッグフラグを有効にした状態でコンパイルされる必要があります。Springはディスク上に関係をキャッシュするため、かなりのI/O時間ペナルティが発生する可能性があります。public class Pet { @ConstructorProperties({"name", "breed"}) public Pet(String name, String breed) { this.name = name; this.breed = synopsis; } } - Spring Security
AWS Lambdaの実行モデルのため、サーブレットセッションを使用して値を保存することはできません。@Order(1) @Configuration @EnableWebFluxSecurity public class SecurityConfig { @Bean public SecurityWebFilterChain securityWebFilterChain(ServerHttpSecurity http) { return http.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS); } }
LambdaとConcurrency
AWS rootアカウントには、各リージョンごとにFull Account Concurrencyというソフトリミットが存在します。
これは、1つのAWS rootアカウント内の特定リージョンにおけるすべてのLambda関数の同時実行数がこの設定値を超えることはできないことを意味します。
例えば、1つのLambda関数に対するリクエストが非常に多く、同時実行数が現在1000に達している場合、同時に別のLambda関数を呼び出すとすべてがThrottleにかかることになります。
Lambdaは常に1000の同時実行が即座に可能な状態で待機しているわけではありません。リクエストが入るとLambdaはキャパシティを増加させますが、最初にBurstとして増加させる同時実行数をBurst Concurrencyと呼び、ここにもリミットがあります。ソウルリージョンの場合、500です。
最初のBurst後もリクエストが大量に入り続けると、Lambdaはリージョンに関係なく同時実行数を1分間に500ずつ増加させます。
これを解決するために、2019年にProvisioned Concurrency機能がリリースされました。特定のバージョンやaliasごとに、micro VMが常に初期化された状態で待機し、一貫したレイテンシー応答を保証します。ただし、latestバージョンには設定不可

https://docs.aws.amazon.com/images/lambda/latest/dg/images/concurrency-4-animation.gif
同時性の計算方法
一般的に、システムの同時性は2つ以上の作業を同時に処理できる機能です。Lambdaでの同時性は、関数が同時に処理する進行中のリクエストの数を指します。Lambda関数の同時性を測定するための迅速で実用的な方法は次の通りです。
Concurrency = TPS * duration(by second)
例えば、1秒間に100件のリクエストを受け取り、durationが1秒であれば、concurrencyは100です。
逆に、平均durationを基にしていくつかのconcurrencyしかない場合は、TPSを推定することができます。
TPS = concurrency / duration(by second)
上記のverify APIを例に挙げると、15のconcurrencyがあれば300TPSが解決できます。
300TPS = 15(concurrency) / 0.05(second)
したがって、多くのconcurrencyが必要な場合は、warmerを利用して特定のLambdaを同時に起動させることで、Provisioned Concurrencyと同様の効果を得ることができます。また、durationが短いほど、少数のconcurrencyでも多くのTPSを処理することができます。