イントロ
Redisはキャッシュサーバーとして多く使用されていますが、最近では多くの変化がある技術です。今回はRedisの新しい部分についてポスティングします。
SortedSet
RedisのSorted Setを使用してリアルタイム検索システムを実装する方法は、効率的でありながらリアルタイムでデータを更新し管理する強力な方法を提供します。Redis Sorted Setは、値をスコアに従って自動的に並べ替えるデータ構造です。これを利用すると、検索ワードの人気度や頻度をスコアとして使用してリアルタイムで検索ワードの順位を管理することができます。
-
Sorted Set初期化
- 各検索ワードをSorted Setに追加する際、検索ワードがキー(Key)となり、その検索ワードのスコア(例:検索回数)が値(Value)となります。
- ユーザーが特定の単語を検索するたびに、その単語のスコアを増加させるためにZINCRBYコマンドを使用します。
-
リアルタイム検索ワード順位の更新
-
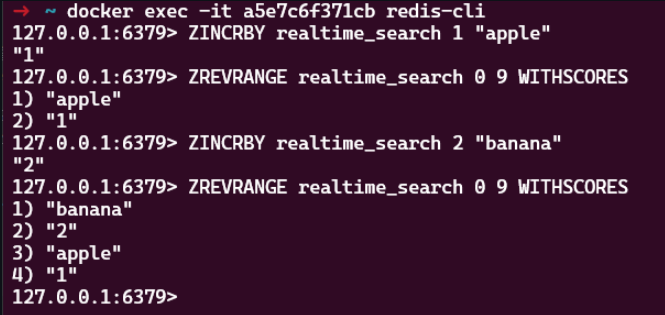
ZINCRBYコマンドを使用して検索スコアを増加させることができます。
$ ZINCRBY realtime_search 1 "apple" $ ZINCRBY realtime_search 2 "banana"
-
ZINCRBYコマンドを使用して検索スコアを増加させることができます。
-
検索ワード順位の取得
-
ZREVRANGEコマンドを使用してスコアが高い順に検索ワードを取得することができます。
// 上位10個の検索ワードとそのスコアを返します。 $ ZREVRANGE realtime_search 0 9 WITHSCORES
-
ZREVRANGEコマンドを使用してスコアが高い順に検索ワードを取得することができます。
-
期間別または条件別順位の調整
- 特定期間のデータのみを維持するために、検索ワードのスコアを定期的にリセットしたり、古い検索ワードを自動的に削除することができます。
- EXPIREコマンドを使用して自動的に期限切れにすることができ、ZREMRANGEBYSCOREで特定のスコア範囲の検索ワードを削除することもできます。
Sorted Setの操作速度
RedisのSorted Setは、内部的にスキップリスト(skip list)、ハッシュマップ(hash map)、および場合によってはジップリスト(小さなデータセットの最適化のための圧縮データ構造)を使用して実装されています。これらの構造はデータの挿入、削除、検索を効率的に行うことができ、大部分の操作は対数時間の計算量(O(log N))を持ちます。
パフォーマンス詳細
- 挿入(ZADD):新しい要素を追加したり既存の要素のスコアを更新する際、Sorted SetはO(log N)の計算量を持ちます。ここでNはSorted Setの要素数です。
- 削除(ZREM):特定の要素を削除する操作もO(log N)の計算量を持ちます。
- 検索(ZRANK、ZSCOREなど):要素の順位を見つけたりスコアを取得する操作はO(log N)の計算量で行われます。
- 範囲クエリ(ZRANGE、ZREVRANGEなど):特定の順位範囲にある要素を取得する際の計算量はO(log N + M)です。ここでMは返される要素の数です。
スキップリスト
スキップリストは複数のレベルを持つリンクドリスト構造で、ノードが一つ以上のレベルで次のノードを指すポインタを持っています。
-
初期状態がノード3,7,8,12で構成されるスキップリストを仮定します。
レベル 3: ヘッド -> 12 レベル 2: ヘッド -> 7 -> 12 レベル 1: ヘッド -> 3 -> 7 -> 8 -> 12 -
挿入過程:値10を挿入
- 位置探索:
- レベル3から始めて12より小さい10を見つけるためにレベル2に移動します。
- レベル2で7の次が12であることを確認し、10を挿入する位置は7と12の間であることを確認してレベル1に移動します。
- レベル1で8の次が12であるため、10は8と12の間に挿入されます。
- レベル決定:
- レベル1で8の次が12であるため、10は8と12の間に挿入されます。
- ノード挿入およびポインタ更新:
- レベル1で8の次のノードを10に設定し、10の次のノードを12に設定します。
- レベル2で7の次のノードを10に設定し、10の次のノードを12に設定します。
- レベル3は変化なし
レベル 3: ヘッド -> 12 レベル 2: ヘッド -> 7 -> 10 -> 12 レベル 1: ヘッド -> 3 -> 7 -> 8 -> 10 -> 12 - 位置探索:
-
削除過程:値8を削除
- 位置探索:
- レベル3から始めて8を見つけます。
(削除しようとする要素を見つけるために最も低いレベルから始めるのが一般的です。)
- レベル3から始めて8を見つけます。
- ノード削除およびポインタ更新
- レベル1で7の次のノードを8から10に変更します。
レベル 3: ヘッド -> 12 レベル 2: ヘッド -> 7 -> 10 -> 12 レベル 1: ヘッド -> 3 -> 7 -> 10 -> 12 - 位置探索:
スキップリストの空間計算量
-
ポインタ保存: スキップリストの各ノードは複数レベルのポインタを保存する必要があります。一般的に、各ノードは平均して1/(1-p)個のポインタを保存します。ここでpはノードが次のレベルに昇格する確率です(例:p=0.5の場合、各ノードは平均して2つのポインタを持ちます)。
-
追加メモリ要件: スキップリストの構造を維持するために追加のメモリが必要です。特に高いレベルのノードでは多くのポインタが必要であり、これらのポインタはデータ自体よりも多くの空間を占有する可能性があります。
-
レベルの数: 実際のメモリ使用量はレベルの数に大きく依存します。レベルが多いほど多くのポインタが必要となり、これにより空間計算量が増加します。
AVLやRBツリーとの比較
-
ポインタの数: スキップリストの各ノードは複数レベルに渡る複数のポインタを持つことができます。これにより、各ノードあたり複数のポインタが必要となり、特に高いレベルのノードは多くのポインタを持つことになります。
-
メモリ計算量: AVLツリーおよびレッド-ブラックツリーはそれぞれ高さが対数スケールで増加し、比較的均一な高さを維持するため、メモリ使用がより予測可能で効率的です。
RediSearch
RedisearchはRedisデータベースにテキスト検索およびインデックス機能を追加するモジュールです。Redisの高速なパフォーマンスとリアルタイムデータ処理能力を活用して高性能なテキスト検索を提供します。Redisearchはテキストベースの検索だけでなく、構造化データ
の検索、範囲検索、ソート、フィルタリング、オートコンプリートなどの高度な機能もサポートしています。
主要機能:
- テキスト検索: 自然言語処理、部分一致検索、正確なフレーズ検索など様々なテキスト検索機能。
- 構造化データ検索: 数値、日付、地理的な位置など様々なデータタイプをサポート。
- 高度なクエリ: AND, OR, NOT演算子、範囲検索、ソート、フィルタリングなど高度なクエリ機能。
- オートコンプリートおよび提案: オートコンプリートインデックスと提案機能。
- リアルタイム検索: Redisの高性能リアルタイムデータ処理能力を活用した高速検索。
Redisearchの利点
-
パフォーマンス: RedisearchはRedisのインメモリデータストアを基盤としているため、非常に高速な検索パフォーマンスを提供します。これはリアルタイムデータ処理が必要なアプリケーションに適しています。特に短い応答時間が重要な場合、Redisearchが有利です。
-
簡単なインストールと使用: RedisearchはRedisモジュールとして、Redisサーバーに簡単に追加インストールできます。Redisクライアントライブラリを通じて簡単に使用でき、複雑な設定は必要ありません。
-
リアルタイムインデックス: Redisearchはデータが追加または更新されたときにリアルタイムでインデックスを更新します。これにより変更されたデータを即座に検索でき、リアルタイムアプリケーションに非常に有用です。
-
低いメモリオーバーヘッド: RedisearchはRedisのデータ圧縮および効率的なメモリ管理機能を活用してメモリオーバーヘッドを最小限に抑えます。これにより大規模データ処理時にも効率的なメモリ使用が可能です。
-
統合されたデータストレージ: Redisは多様なデータ構造をサポートしており、Redisearchと一緒に使用することでテキスト検索、キャッシング、メッセージブローカーなどの機能を1つのデータストアで統合的に管理できます。
RediSearch vs ElasticSearch
https://redis.io/blog/search-benchmarking-redisearch-vs-elasticsearch/
-
Redisearch: リアルタイム検索、低遅延、簡単な設定が必要な場合に適しています。特にRedisを既に使用している環境では簡単に統合できます。
-
Elasticsearch: 大規模データセット、複雑なクエリおよび分析、高い拡張性が必要な場合に適しています。ログ分析、データ可視化、フルテキスト検索など多様な使用ケースに有利です。
サンプルコード
const Redis = require('ioredis');
const redis = new Redis({
host: 'localhost', // Redisサーバーホスト
port: 6379 // Redisサーバーポート
});
(async () => {
// インデックスが存在するか確認する関数
const indexExists = async (indexName) => {
try {
await redis.call('FT.INFO', indexName);
return true;
} catch (err) {
return false;
}
};
const createIndex = async (indexName) => {
const exists = await indexExists(indexName);
if (!exists) {
await redis.call('FT.CREATE', indexName,
'ON', 'HASH',
'PREFIX', '1', 'doc:',
'SCHEMA',
'title', 'TEXT',
'content', 'TEXT'
);
console.log('Index created.');
} else {
console.log('Index already exists.');
}
};
// インデックス作成(既にある場合はスキップ)
await createIndex('myIndex');
// ドキュメント追加(更新含む)
const addOrUpdateDocument = async (docId, fields) => {
await redis.hmset(docId, fields);
console.log(`Document ${docId} added or updated.`);
};
// ドキュメント追加
await addOrUpdateDocument('doc:1', {
title: 'Hello World',
content: 'This is the content of the first document. It has some example text.'
});
await addOrUpdateDocument('doc:2', {
title: 'Redisearch Example',
content: 'This is an example of using Redisearch with Node.js. Redisearch is powerful.'
});
await addOrUpdateDocument('doc:3', {
title: 'Example Title',
content: 'Another example of a document with the title containing example.'
});
await addOrUpdateDocument('doc:4', {
title: 'Hello Redisearch',
content: 'Document with a title that starts with Hello.'
});
const countTitlesWithSubstring = async (substring) => {
const query = `@title:*${substring}*`;
const aggregateResult = await redis.call(
'FT.AGGREGATE', 'myIndex', query,
'GROUPBY', '0', 'REDUCE', 'COUNT', '0', 'AS', 'count'
);
return aggregateResult[1];
};
const searchDocumentsInTitle = async (word) => {
const searchResult = await redis.call('FT.SEARCH', 'myIndex', `@title:${word}*`);
console.log(searchResult);
return searchResult;
};
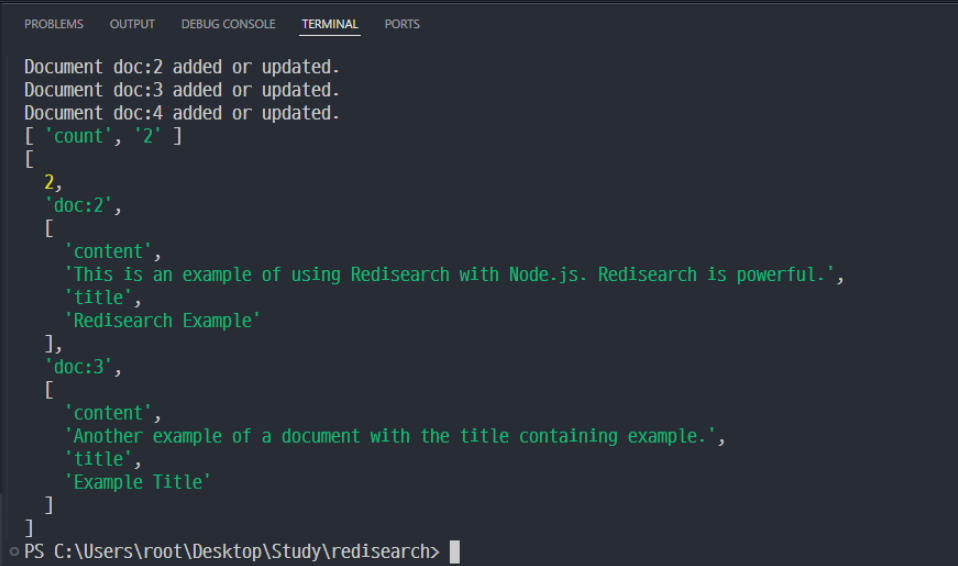
// 'example'を含むtitleの数を集計
const substringToCount = 'example'; // ex*
const count = await countTitlesWithSubstring(substringToCount);
console.log(count);
const wordToSearch = 'ex';
await searchDocumentsInTitle(wordToSearch);
redis.quit();
})();
高度なクエリ機能
- AND, OR, NOT演算子: 複雑な論理条件を設定できます。
const searchResult = await redis.call('FT.SEARCH', 'myIndex', 'example | redisearch -powerful'); - 正確なフレーズ検索: 引用符を使用して正確なフレーズを検索できます。
const searchResult = await redis.call('FT.SEARCH', 'myIndex', '"example of using Redisearch"'); - 範囲検索: 数値や日付などの範囲を検索できます。
await redis.call('FT.CREATE', 'myIndex', 'ON', 'HASH', 'PREFIX', '1', 'doc:', 'SCHEMA', 'price', 'NUMERIC'); const searchResult = await redis.call('FT.SEARCH', 'myIndex', '@price:[10 100]'); - フィルタリング: 特定のフィールド値で結果をフィルタリングできます。
const searchResult = await redis.call('FT.SEARCH', 'myIndex', '@title:example @content:Redisearch'); - ソート: 結果を特定のフィールド基準でソートできます。
const searchResult = await redis.call('FT.SEARCH', 'myIndex', 'example', 'SORTBY', 'price', 'ASC'); - 集計: 検索結果をグループ化し統計を計算できます。
const aggregateResult = await redis.call('FT.AGGREGATE', 'myIndex', '*', 'GROUPBY', '1', '@title', 'REDUCE', 'COUNT', '0', 'AS', 'count'); - オートコンプリートインデックス生成: オートコンプリートのためのインデックスを生成できます。
await redis.call('FT.SUGADD', 'autoComplete', 'redisearch', '1'); - オートコンプリート提案: ユーザーが入力したテキストに対してオートコンプリートの提案を受け取ることができます。
const suggestions = await redis.call('FT.SUGGET', 'autoComplete', 'red', 'FUZZY');