これを読んで得られること
- CRF(条件付き確率場)を用いた時系列データの分類
- 自分のためにまとめておこうというモチベーション
- まとめているうちに自分の中で整理されてきて、記事にするほどじゃないよねという気になっている
これを読んでも書いていないこと
- 自然言語のCRFによる分類の方法
- 各ライブラリにあるチュートリアルが詳しいのでそちらへ
- CRFの詳細説明
- これも大学の講義資料とか書籍とかたくさん詳しい方がいらっしゃるのでそちらへ...
より正確にはCRFに入れる前に分布を仮定して離散化プロセスが必要です。
CRFとは
深層学習がはやる前に流行っていた教師あり学習のひとつ。例えば、文章中の固有表現の抽出といった系列に対するラベルの付与(系列ラベリング)問題を解く際に適用される。
系列ラベリング
- 系列ラベリング
- 系列に対してラベルを付与するもの
- 隠れマルコフモデル(HMM)やCRFや深層学習のLSTMがある
- 系列に対してラベルを付与するもの
- 系列データ
- 自然言語処理や時系列データ(前後関係がある)
- 画像(周辺情報も大事)
- ラベリング
- 自然言語処理は分類で何かを分類すること(MeCabで形態素解析するとか)
- 時系列データの場合は回帰で今の時点から次の時点を予測すること
- 画像のピクセル毎の分類(セマンティックセグメンテーション)
今回やりたいことは、時系列データを用いてある時点での挙動を分類すること。
例えば、人の速度と歩数から歩いているか、走っているか、自転車に乗っているかといった推定をしたり、心臓の周波数データから緊張しているとかリラックスしているとかを推定すること。
HMMやCRFの関係性をまとめると次のような図となる。(日本語を付した。一部意訳。)

(引用: An Introduction to Conditional Random Fields https://arxiv.org/abs/1011.4088 )
CRFとは
- マルコフ確率場の一種
- マルコフ確率場とは依存関係を無向グラフで表すもの(上図の下段)
- 学習で最大化する対象
- 設計する事後確率
- 教師あり学習
実装手順
ライブラリ候補
- PyStruct
- CRFSuite
- sklearn_crfsuite
sklearn_crfsuiteはCRFSuiteのラッパーでsklearnのモデルセレクションのパッケージが利用できるようになっている。つまりはハイパーパラメーターチューニングが楽。なので今回はsklearn-crfsuiteを用いる。ちなみに線形連鎖条件付き確率場を実現しているライブラリである。
実装ステップ
- データを集める
- データを学習データとテストデータに分割する train_test_split
- 学習データとテストデータを整形する
- 系列データに分割する for文を用いて切ったりくっつけたり
- CRFのモデルを決めるsklearn_crfsuite.CRF()で最適化アルゴリズムを設定したり
- 学習データを学習させる crf.fit(X_train, y_train)
- テストデータで推論する crf.predict(X_test)
- テストデータの正解率を確認する metrics.flat_classification_report() recallとかもこれ
- ハイパーパラメータのチューニング RandomizedSearchCV
- ハイパーパラメーターと正解のスコアのばらつきを可視化
手順は公式チュートリアルを見ながら時系列データに応用
https://sklearn-crfsuite.readthedocs.io/en/latest/tutorial.html
1. データを集める
今回は気象庁の気温と気圧から天気を予測する。
2020年1月1日から2021年1月22日までの3時間毎の気温と気圧と天気をお借りした。
https://www.data.jma.go.jp/gmd/risk/obsdl/index.php
df = pd.read_csv('202001data.csv', encoding='shift-jis', skiprows=3)
df = df.append(pd.read_csv('202004data.csv', encoding='shift-jis', skiprows=3))
df = df.append(pd.read_csv('202007data.csv', encoding='shift-jis', skiprows=3))
df = df.append(pd.read_csv('202010data.csv', encoding='shift-jis', skiprows=3))
df.columns = ['datetime', 'temparature', 'weather', 'pressure']
df = df[['datetime', 'temparature', 'pressure', 'weather']]
df = df.dropna(how='any')
df = df.reset_index(drop = True)

2. データを学習データとテストデータに分割する
X_df = df[['temparature', 'pressure']]
y_s = df['weather']
X_train, X_test, y_train, y_test = train_test_split(X_df, y_s, random_state=0)
3. 学習データとテストデータを整形する
入力データはdictionary型にする。
X_train = X_train.to_dict(orient='records')
X_test = X_test.to_dict(orient='records')
正解ラベルはリスト型
y_train = y_train.to_list()
y_test = y_test.to_list()
4. 系列データに分割する
全データを等間隔のwindow幅を持つ系列データに整形する。
これは辞書型の集合の配列とする。
学習データとテストデータは[[{}{}{}], [{}{}{}], [{}{}{}]]こんなイメージ。
正解ラベルは[[], [], []]こんなイメージ。
from_i = 0
step = 10 # window幅
to_i = len(X_train) - step
X_trains = []
for i in range(from_i, to_i, step):
X_trains.append(X_train[i:i+step])
y_trains = []
for i in range(from_i, to_i, step):
y_trains.append(y_train[i:i+step])
to_i = len(X_test) - step
X_tests = []
for i in range(from_i, to_i, step):
X_tests.append(X_test[i:i+step])
y_tests = []
for i in range(from_i, to_i, step):
y_tests.append(y_test[i:i+step])
5. CRFのモデルを決める
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
c1=0.1,
c2=0.1,
max_iterations=100,
all_possible_transitions=True
)
6. 学習データを学習させる
crf.fit(X_trains, y_trains)
7. テストデータで推論する
labels = list(crf.classes_)
y_pred = crf.predict(X_tests)
metrics.flat_f1_score(y_tests, y_pred,
average='weighted', labels=labels)
8. テストデータの正解率を確認する
sorted_labels = sorted(
labels,
key=lambda x: (x[1:], x[0])
)
print(metrics.flat_classification_report(
y_tests, y_pred, labels=sorted_labels, digits=3
))
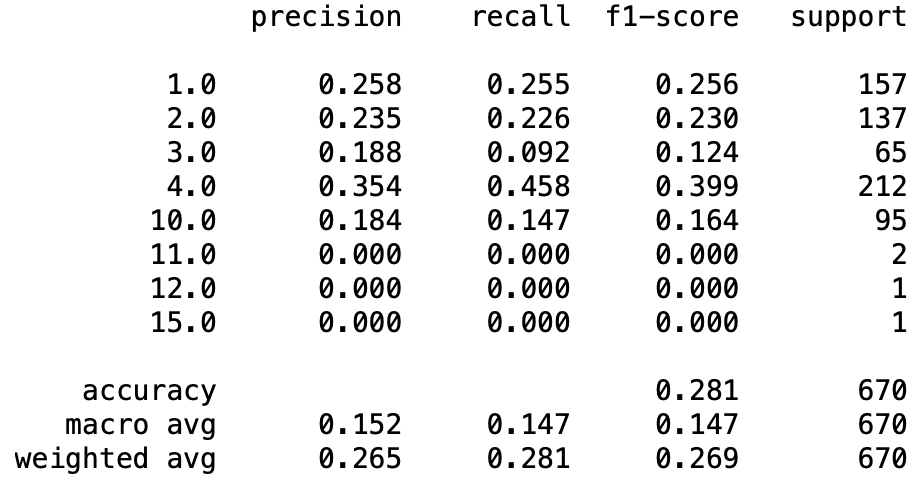
9. ハイパーパラメータのチューニング
# define fixed parameters and parameters to search
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
max_iterations=100,
all_possible_transitions=True
)
params_space = {
'c1': scipy.stats.expon(scale=0.5),
'c2': scipy.stats.expon(scale=0.05),
}
# use the same metric for evaluation
f1_scorer = make_scorer(metrics.flat_f1_score,
average='weighted', labels=labels)
# search
rs = RandomizedSearchCV(crf, params_space,
cv=2,
verbose=1,
n_jobs=-1,
n_iter=50,
scoring=f1_scorer)
rs.fit(X_trains, y_trains)
10. ハイパーパラメーターと正解のスコアのばらつきを可視化
_x = [s['c1'] for s in rs.cv_results_['params']]
_y = [s['c2'] for s in rs.cv_results_['params']]
_c = [s for s in rs.cv_results_['mean_test_score']]
fig = plt.figure()
fig.set_size_inches(6, 6)
ax = plt.gca()
ax.set_yscale('log')
ax.set_xscale('log')
ax.set_xlabel('C1')
ax.set_ylabel('C2')
ax.set_title("Randomized Hyperparameter Search CV Results (min={:0.3}, max={:0.3})".format(
min(_c), max(_c)
))
ax.scatter(_x, _y, c=_c, s=60, alpha=0.9)
print("Dark blue => {:0.4}, dark red => {:0.4}".format(min(_c), max(_c)))

結果より気温と気圧だけでは最大で28%の予測精度であった。
つまり気温と気圧からCRFで天候を予測することは難しい。
本記事の目的としては予測精度を上げることではなく、CRFで時系列データのある点の予測を行うことである。
何かありましたらコメントいただけると幸いです。
参考ページ
sklearn-crfsuite
https://sklearn-crfsuite.readthedocs.io/en/latest/index.html
Using CRF in Python
http://acepor.github.io/2017/03/06/CRF-Python/
An Introduction to Conditional Random Fields
https://arxiv.org/abs/1011.4088