目的
事業者等の信頼関係をはかる指標を測る仕組みを作りたい。
まず、事業者に対して条件を課し、その達成度によって階級(星3や星5など)をつけます。
そして、事業者には階級によってなにかしら優遇を与えることで競争を促し、結果として信頼関係の底上げをすることができます。
階級制にする意義
階級制にすることで得られる効果はもう一つあります。それは、「事業者の参入する敷居を低くすることができる」ことです。
どのような条件を課すか
今のところ以下の項目を考えています。
①金銭的な担保
②プライバシー
③契約条件
④セキュリティ
⑤レスポンスの速さ
⑥法律、コンプライアンス
⑦会員補償、グルーピング
それぞれの項目において線引きをするための基準がさらに必要であり、さらに枝分かれすることになります。
⑦の会員補償はなかなか難しく、様々な問題点が発生しました。
また以下では、
「項目」:上記の①-⑦のこと , 「基準」:それぞれの項目に対する明確な基準のこと
として言葉を用います。
そして以下のサンプルでは5つの項目とそれぞれ5つの基準があるとして、5×5の配列を入力としていることに注意してください。
技術的方法
私が実際に考えた方法を振り返っていきたいと思います。主に以下の三つから成り立ちます。
①.二進数のbit演算によって識別する方法
↓
②.二進数ではなく10進数表示の配列を用いて識別する方法
↓
③.②の内容の拡張
①,②ともに問題点があったためこのような推移となりました(③にも問題点はまだあるので発展させる必要はあります)。
作成するモデル
実際に作っていくモデルは以下の図のようになります。
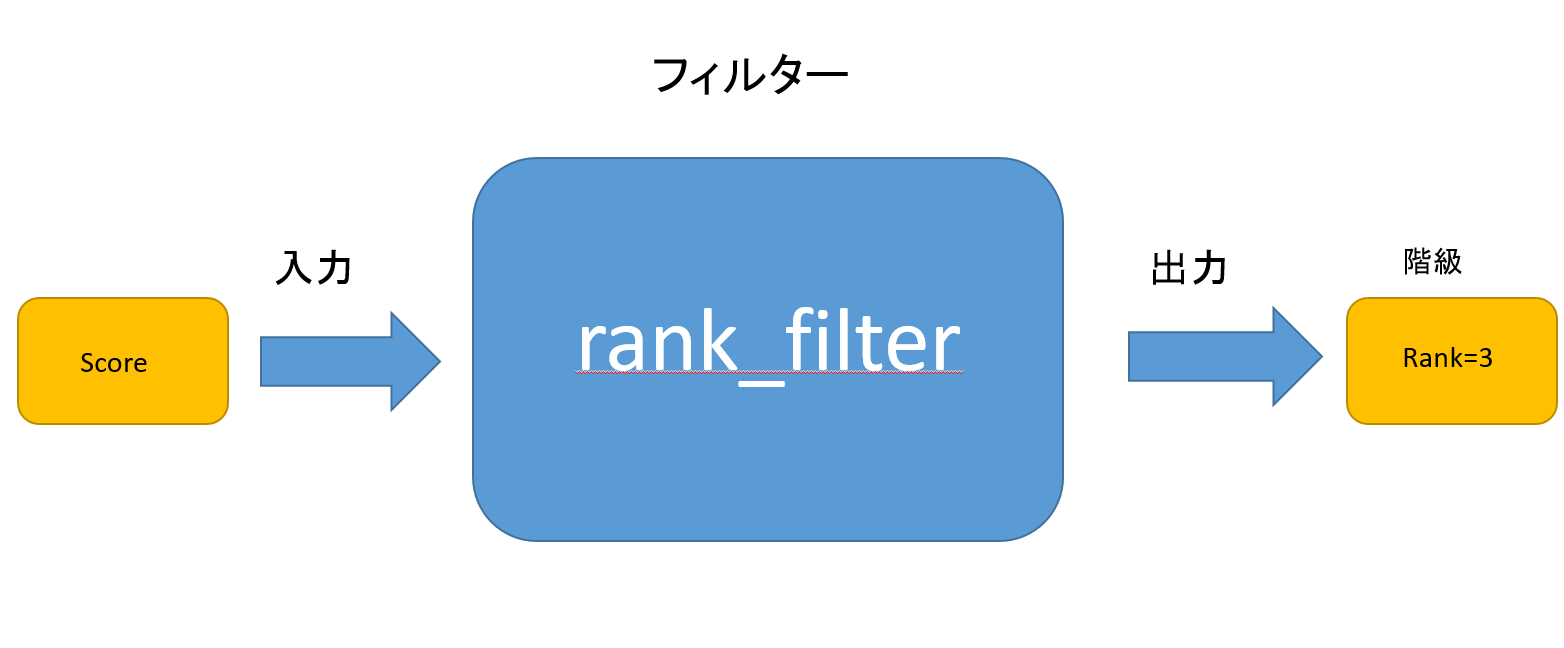
それぞれの事業者のステータスを記した1次元または2次元配列をFilter(識別子)に入力すると、出力として階級(rank)がでてくるモデルです。
①bit演算によって識別する方法
最初はbit演算で実装しようと考えました。
bit演算では3bitあれば8通り、4bitあれば16通り表せて、計算処理を早くできると思っていたからです。
しかし、いくつか問題点がありました。
問題点①:nbitで2のn乗通り表せても、演算ができない
二進数で011(3),100(4)などをあらわしてもAND演算やOR演算ができないという問題があります。
011 & 100 = 000 を計算したところでようの011と100を判別する手段がなくなってしまいます。(000 & 000 = 000 の可能性もある)
基本的にbit演算する場合は各桁に一つの意味づけをするので3bitなら3つの状態しか表すことができません。
Aを001,Bを100とすると001 & 100 = 101 であればAとBの状態であることがわかります。
問題点②:bit表現にすると二次元配列となり、メモリを多く使う。
例えば項目が5つありそれぞれに1,2,3,2,5の階級がついているとすると
1,2,3,2,5
[1,1,1,1,1]
[0,1,1,1,1]
[0,0,1,0,1]
[0,0,0,0,1]
[0,0,0,0,1]
となります。
二次元になるため、フィルターとのAND計算する際にすべての要素で計算することになり、その分処理時間がかかってしまいます。
この問題を解決するため、10進数での表現([1,2,3,2,5]をそのまま)を使うようにします。
2進数表現と10進数表現との速度比較
以下では100万回くりかえした時の処理時間を計測して比較したいと思います。
二進数表示の場合
import numpy as np
import time
t1 = time.time()
filter_impotant = np.array([[0,0,1,0,0],
[1,1,0,1,1],
[0,0,1,1,1],
[0,0,0,0,1],
[0,1,0,1,0]])
input = np.array([[0,0,1,1,0],
[1,1,0,1,1],
[0,0,0,1,1],
[0,1,0,0,1],
[1,0,0,1,0]])
for num in range(1000000):
result = (filter_impotant&input)
t2 = time.time()
print(t2-t1)
結果
1.035663366317749
10進数表示の場合
import numpy as np
import time
t1 = time.time()
filter_rank_1 = np.array([1,1,1,1,1])
input = np.array([1,2,3,2,5])
for index in range(1000000):
result = input >= filter_rank_1
t2 = time.time()
print(t2-t1)
結果
0.8108527660369873
実験結果から10進数表示の方が早いことがわかります。
(この結果はフィルターとの計算のみの実験結果です。実際はこの後に、配列からランクを出す作業が必要ですが、どちらもほとんど同じ処理のため省いています。)
以上から、ここからは10進数表示を用いることとします。
②10進数の配列を用いて識別する方法
ここでは、入力を各項目のスコア(基準を満たした数)として表します。
例として、5つの項目のスコアがそれぞれ(2,3,4,0,2)のときは配列[2,3,4,0,2]が入力となります。
モデル
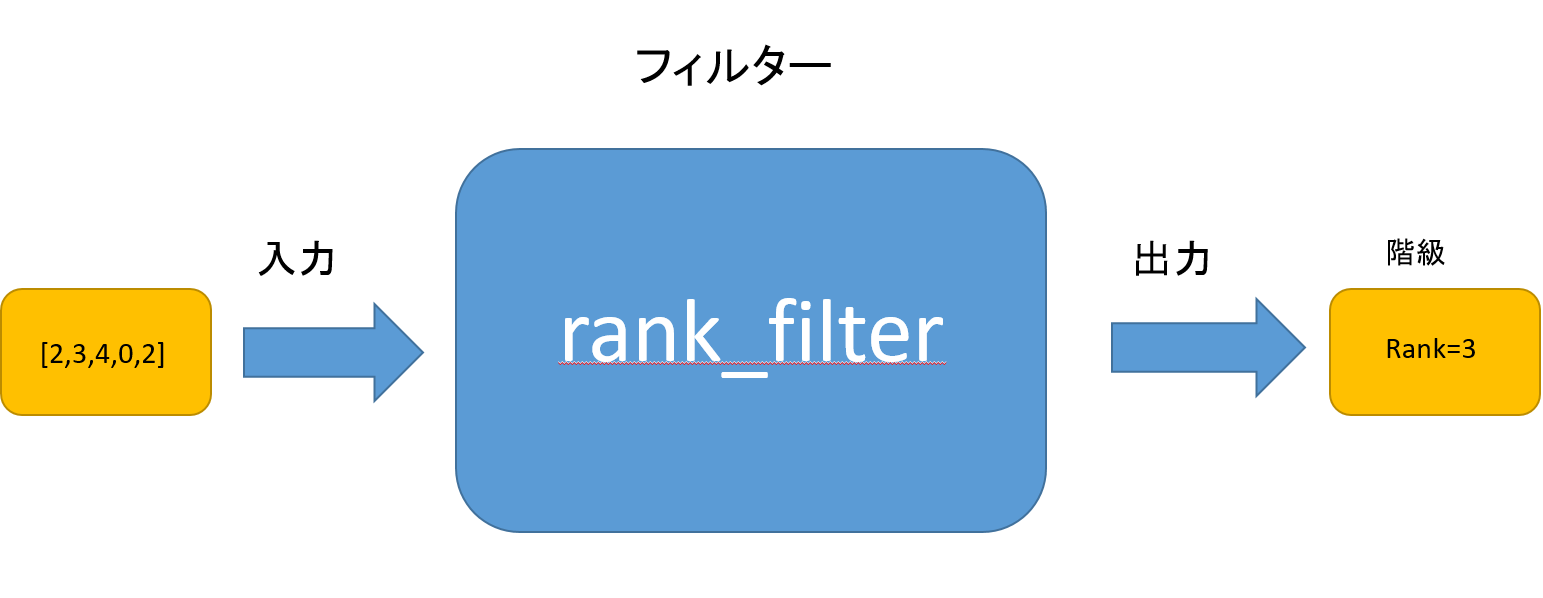
コード
まず、rankを決めるための基準となるフィルターを定義します。
# filterの設定
filter_rank_1 = np.array([1,1,1,1,1])
filter_rank_2 = np.array([2,2,2,2,2])
filter_rank_3 = np.array([3,3,3,3,3])
filter_rank_4 = np.array([4,4,4,4,4])
filter_rank_5 = np.array([5,5,5,5,5])
サンプルでは上記のように定めます。
それぞれのフィルターと入力の大小関係を比べて、入力値がすべて大きければそのランクを得られる仕組みにします。
def rank_filter(input):
#filterの設定
filter_rank_1 = np.array([1,1,1,1,1])
filter_rank_2 = np.array([2,2,2,2,2])
filter_rank_3 = np.array([3,3,3,3,3])
filter_rank_4 = np.array([4,4,4,4,4])
filter_rank_5 = np.array([5,5,5,5,5])
#filtersリスト: ひとつにまとめる
filters = np.vstack((filter_rank_1,filter_rank_2,filter_rank_3,filter_rank_4,filter_rank_5))
rank = 0
for index in range(5):
print(input >= filters[index])
filter = (input >= filters[index])
if (filter == True).all():
rank = index+1
print(rank)
return rank
inputを適当に定義して関数を実行します。
input = np.array([2,3,2,4,5])
rank = rank_filter(input)
print("rank= " + str(rank))
実行結果
[ True True True True True]
1
[ True True True True True]
2
[False True False True True]
[False False False True True]
[False False False False True]
rank= 2
以上で、実装は終わりです。しかし、これではまだ問題点があります。
問題点:基準に対する重みが考慮されていない
入力の配列([2,3,2,4,5]など)はそれぞれの項目に対するスコア(基準を満たしている数)です。
しかし、実際にはそれぞれの基準には絶対に必要な条件や、必要だが優先度の低い条件などがあると思います。
例えば、金銭的な担保という項目では、「期日までに払えている」や「請求した分を全額払えている」などは重要なことですが、「」というのは前二つに比べて優先度が低いでしょう。
5つの基準があって重要な二つは守れてないが、優先度の低い3つは守れているためスコアが3獲得できランクが上がるというのは意図しない挙動です。
この問題を回避するために次で拡張していきます。
③上記の方法の拡張
②での問題を解決するために、基準を考慮した二次元配列を入力とします。
作成するモデル
作成するモデルは以下のようになります。
scoreの前にスコアを決めるフィルター(score_filter)を実装することを目指します。
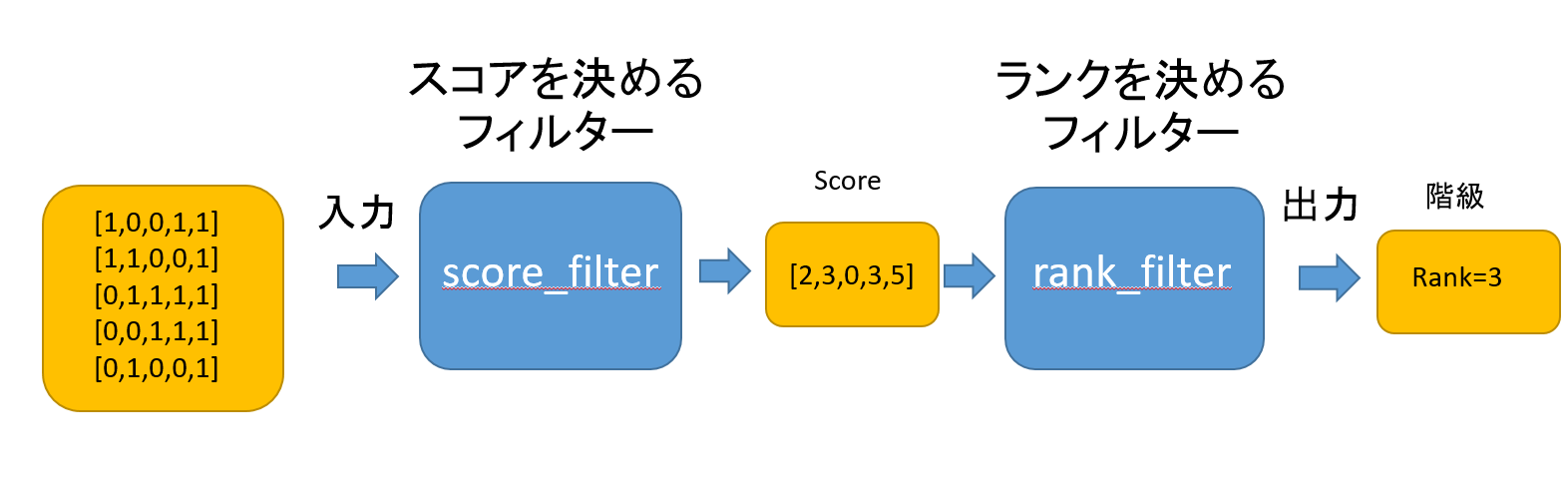
スコアを決めるフィルター
いままで入力を一次元として[2,3,2,3,5]のようにあらわしてきましたが、ここでは以下のように基準を考慮して入力を表します。
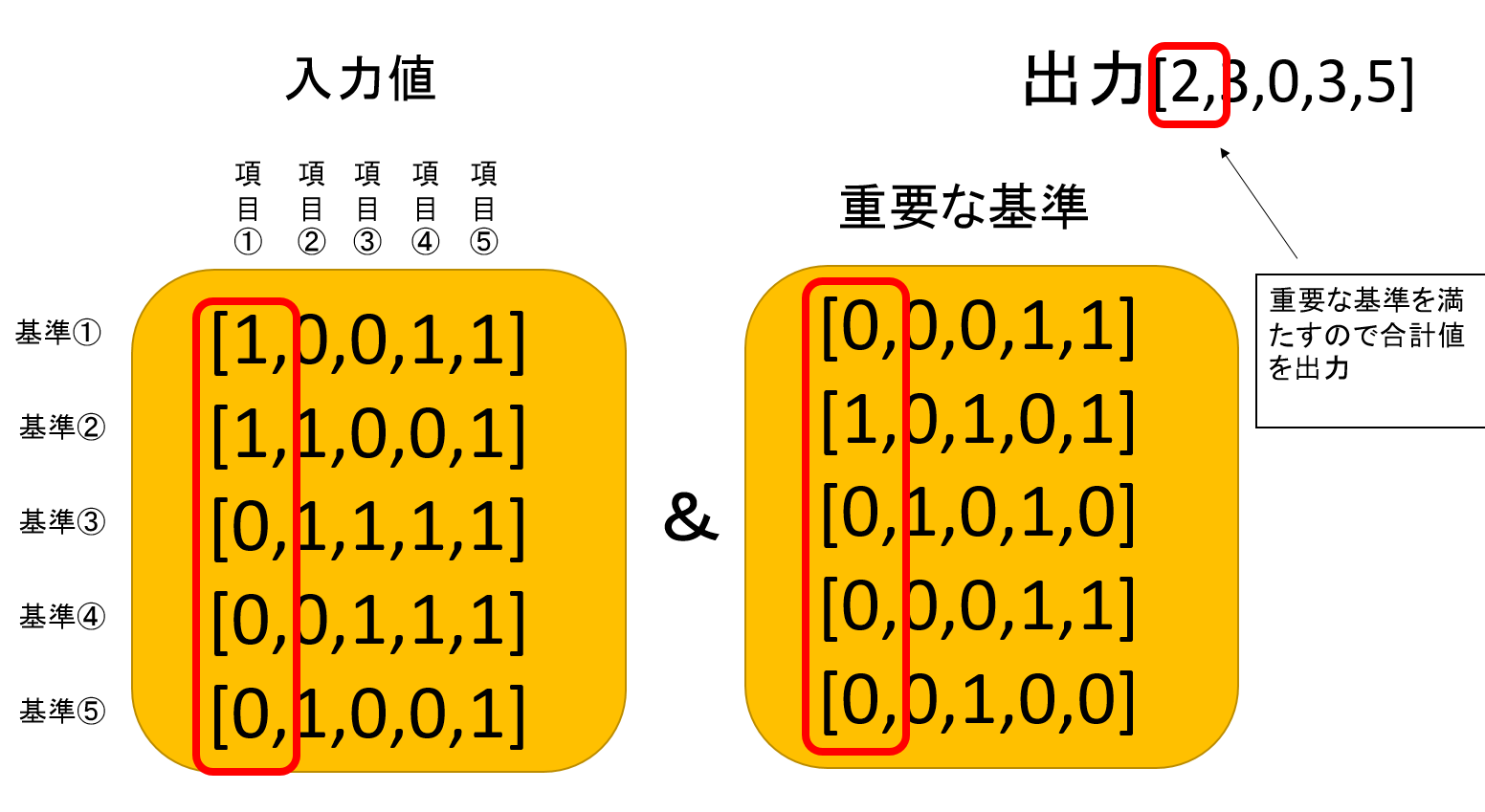
score_filter内では満たすべき基準をあらわした配列(filter_impotant)があり、その基準を満たしていれば合計がスコアとしてあらわします。
反対に、満たしていなければスコアを強制的に0とします。(強制的に0にはせず、それぞれの基準に重みをつけるという手法も一応考えられます。)
コード
def score_filter(input):
#filterの設定(縦軸:項目、横軸:基準)
filter_impotant = np.array([[0,0,1,0,0],
[1,1,0,1,1],
[0,0,1,1,1],
[0,0,0,0,1],
[0,1,0,1,0]])
#scoreの初期化
score = np.array([0,0,0,0,0])
for row in range(5):
filter = ((filter_impotant[:,row] & input[:,row]) == filter_impotant[:,row])
if (filter == True).all():
score[row] = sum(input[:,row])
else:
score[row] = 0
return score
入力値を適当に定め、実行してみます。
input = np.array([[1,1,1,0,0],
[1,1,1,1,1],
[1,1,1,1,1],
[0,1,1,0,1],
[0,1,0,1,0]])
score = score_filter(input)
print("score= " + str(score))
rank = rank_filter(score)
print("rank= " + str(rank))
実行結果
score= [3 5 4 3 3]
[ True True True True True]
1
[ True True True True True]
2
[ True True True True True]
3
[False True True False False]
[False True False False False]
rank= 3
以上で一通りの実装は完了しました。
残っている課題、問題点
会員情報はどのようにして表すか。
ここについては今後考えていきたいと思います。