公共機関が提供するデータがPDF, CSVが多くて困ったことはありませんか?
APIを提供してくれたら万々歳、HTMLで公開してくれたらスクレイピングするのですが、、、
未だにPDFやCSVが多いのでオープンになるのが待たれますね。
環境
- Ruby 2.4.2
準備するもの
-
pdf-readerというgem
gem i pdf-readerしといてください。
やりたいこと
- PDFが公開されているurlを取得してくる
- urlを渡す
- PDFを取ってくる
- パースする
- データを使いやすい形に洗浄する(各自適当にやりましょー)
- 必要なデータを保存する(各自適当にry)
利用するデータに関して
今回は、ググったら出てきた
をサンプルとして使います。
下記のurl部分はそれぞれ変更してください。
やること
require 'open-uri'
require 'pdf-reader'
url = 'http://vips.eng.niigata-u.ac.jp/WebAccess/PDFAccessibilityQ&A.pdf'
io = open(url)
reader = PDF::Reader.new(io)
これでreaderにPDFのデータが格納されました。
色々データをみてみましょう。
簡単な文書データの場合(サンプル1)
reader.info
=> {:CreationDate=>"D:20070228171017+09'00'", :Author=>"渡辺 哲也", :Creator=>"Word 用 Acrobat PDFMaker 7.0", :Producer=>"Acrobat Distiller 7.0 (Windows)", :ModDate=>"D:20070228171023+09'00'", :Company=>"情報処理管理係", :SourceModified=>"D:20070220052243", :Title=>"PDF文書のアクセシビリティ"}
reader.infoを実行することでこのPDFの概要がわかります。
著者は誰なのか、どのソフトウェアで作成されたかなどなど...
reader.pages
=> [<PDF::Reader::Page page: 1>, <PDF::Reader::Page page: 2>, <PDF::Reader::Page page: 3>, <PDF::Reader::Page page: 4>, <PDF::Reader::Page page: 5>, <PDF::Reader::Page page: 6>, <PDF::Reader::Page page: 7>, <PDF::Reader::Page page: 8>]
pagesで各ページをオブジェクトとして操作できます。
reader.pages.first.text
=> "PDF 文書のアクセシビリティ\n\n (省略) タッチアップツールを使って追加します。"
本文に関しては、各ページにtextメソッドを使って取得できます。
表形式データの場合(サンプル2)
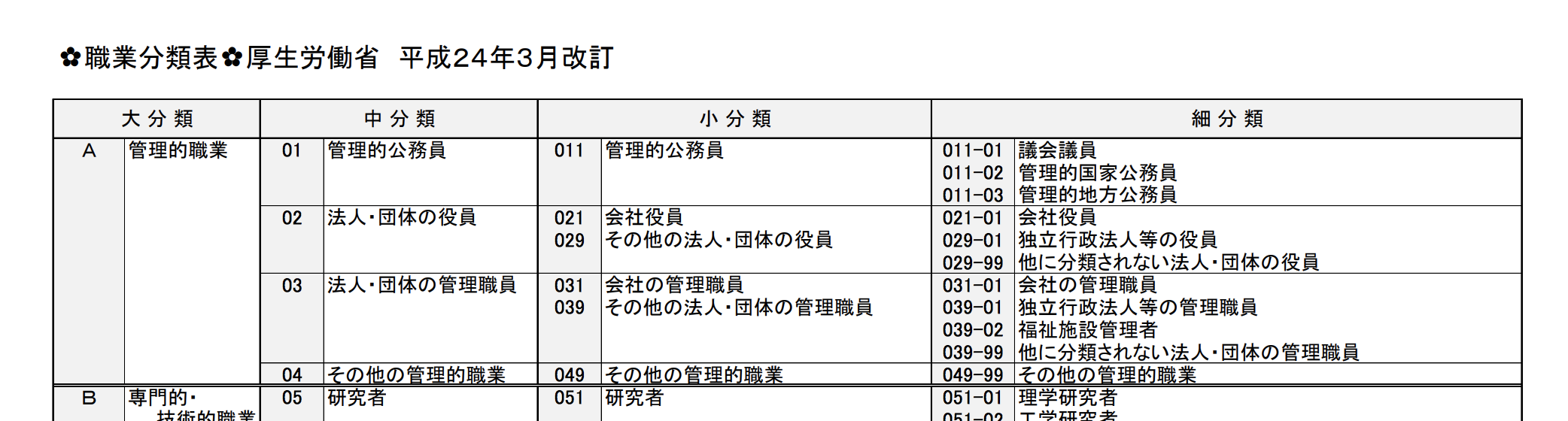
reader.pages.first.text
=> => "✿職業分類表✿厚生労働省 平成24年3月改訂\n\n\n 大 分 類 中 分 類 小 分 類 細 分 類\n A 管理的職業 01 管理的公務員 011 管理的公務員 011-01 議会議員\n 011-02 管理的国家公務員\n\n 011-03 管理的地方公務員\n 02 法人・団体の役員 021 会社役員 021-01 会社役員\n 029 その他の法人・団体の役員 029-01 独立行政法人等の役員\n 029-99 他に分類されない法人・団体の役員\n 03 法人・団体の管理職員 031 会社の管理職員 031-01 会社の管理職員\n 039 その他の法人・団体の管理職員 039-01 独立行政法人等の管理職員\n 039-02 福祉施設管理者\n 039-99 他に分類されない法人・団体の管理職員\n\n 04 その他の管理的職業 049 その他の管理的職業 049-99 その他の管理的職業\n B 専門的・ 05 研究者 051 研究者 051-01 理学研究者\n 技術的職業 ...(省略)"
各行を一つにまとめて表示されるので、読みづらいですね。
reader.pages.first.display
✿職業分類表✿厚生労働省 平成24年3月改訂
大 分 類 中 分 類 小 分 類 細 分 類
A 管理的職業 01 管理的公務員 011 管理的公務員 011-01 議会議員
011-02 管理的国家公務員
011-03 管理的地方公務員
(省略)
displayを利用するとちょっとだけみやすくなりますが、この辺は各自で整形する必要がありそうです。
画像などを含むファイル(サンプル3)
省略しますが、画像は表示されず、構造なども崩れてしまいそうです。
パースする上で一番難度がたかそうなのはこの形式になりそうですね。
終わり
パース自体は公開されているライブラリを利用すれば簡単にできそうですが、
そのデータがテキスト以外の構造的な意味合いを持っている場合は、それを読み取り加工する能力が必要になりそうです。
この辺を汎用的に行える方法がありましたらどなたか教えてくださいませ。
ちなみに......
Atraeでは、一緒に闘ってくれる仲間を全力で探しております!!
ぜひ、一緒に超絶かっこいいサービスを創りましょう!