はじめに
HTMLParserを使う機会があったのですが、どれも使ってみただけの紹介で、概念を解説したような記事がなかったのでここで改めて紹介しようと思います。(優秀な方ならドキュメント等読めば理解できるのでしょうが、最初はそれなりに理解に時間がかかったのでここでまとめてみます。)
参考:20.2 html.parser
※ソースを読んでいるわけではなく勝手なイメージで説明しています。もし挙動が間違っているなどがあればご指摘お願いいたします。
HTMLParserクラス
このクラスを俯瞰してみるために次のコードを張り付けておきます。
class MyParser(HTMLParser):
def handle_starttag(self, tag, attrs):
pass # タグが始まった時に呼ばれる
def handle_endtag(self, tag):
pass # タグが終わった時に呼ばれる
def handle_data(self, data):
pass # データを呼び出すときに呼ばれる
基本的な構造の理解としてはこれだけで十分です。HTMLはタグと要素で構成されているのはご存じてあると想定して話を進めていきます。
parser = MyParser() # HTMLParserを改良して作った自分用のパーサー
parser.feed(html) # 何らかのhtml形式のデータを引数としてパーサーを実行。
このようにfeedメソッドを呼び出すことでパースが始まります。
feedメソッドが呼び出されたときにどのような呼び出しがされるのかを図示しながら説明します。
<HTML>
<HEAD>
<TITLE>Greeting</TITLE>
</HEAD>
<BODY class="mybody">
<H1>Hello</H1>
<P>World</P>
</BODY>
</HTML>

まず、上から順に捜査していき、開始タグがあることに気づきます。

次に、HTMLParserのhandle_starttagメソッドが呼び出されます。
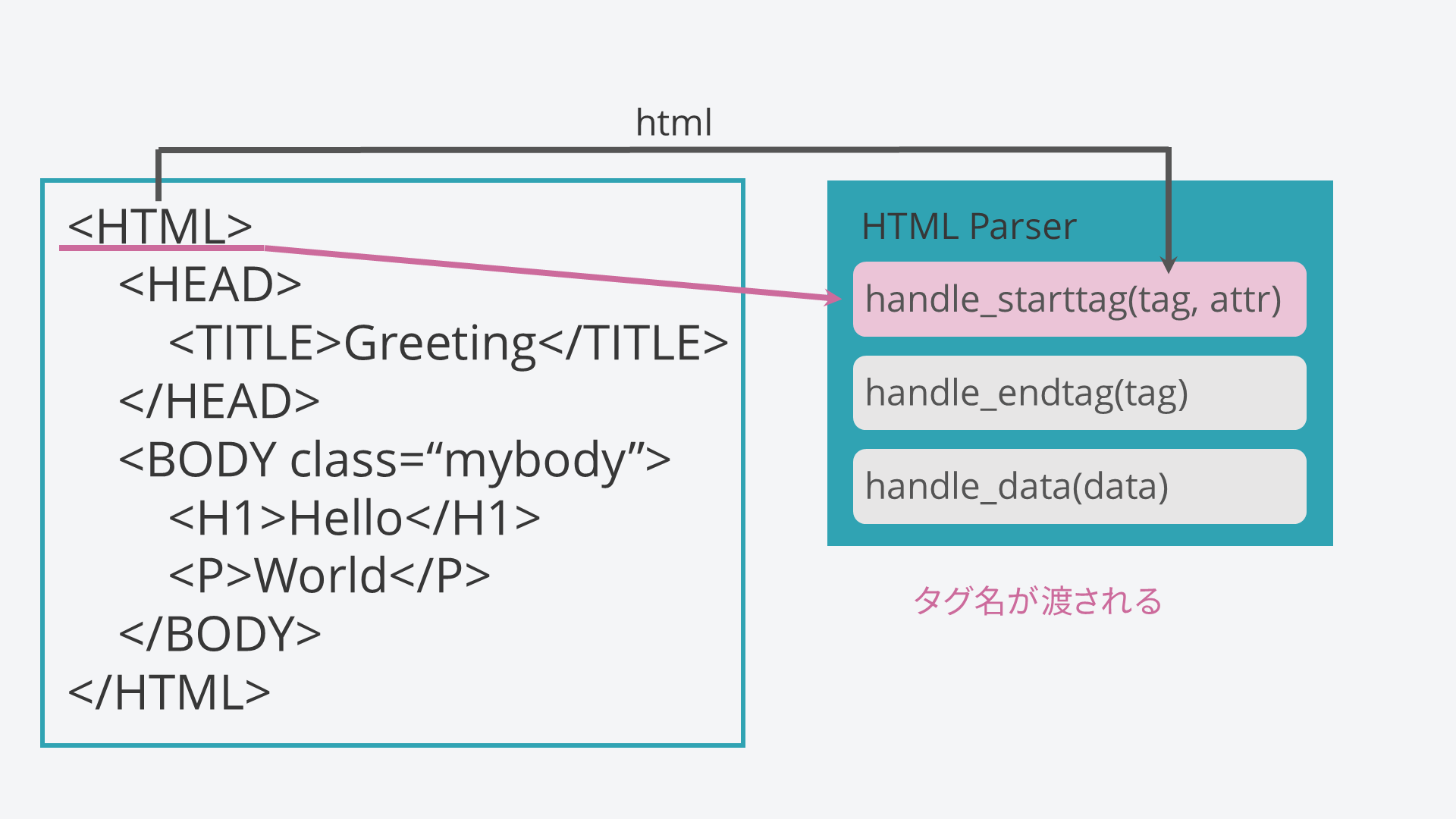
このとき、タグ名を小文字に変換したものが引数tagに渡されます。
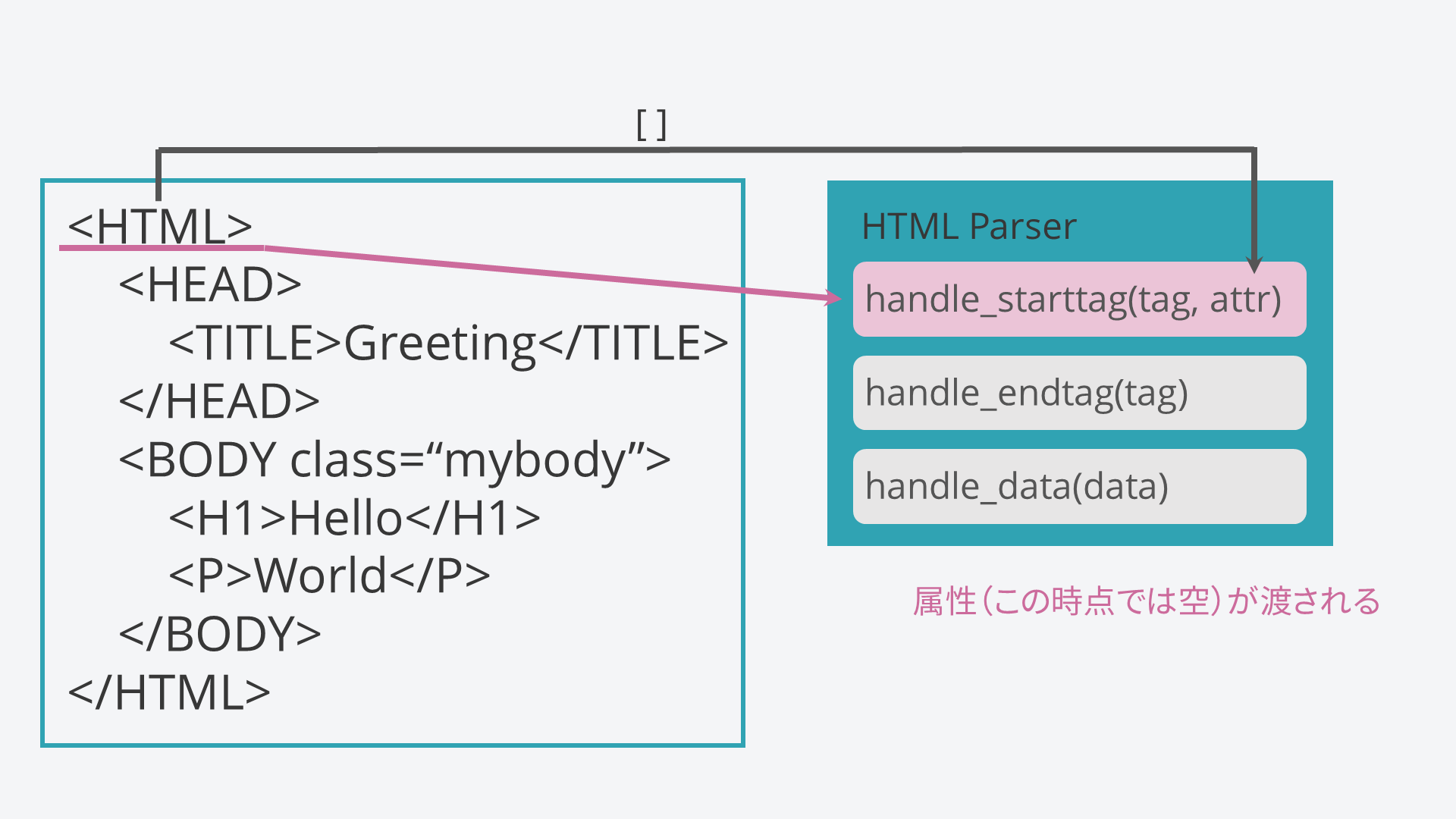
同時に、属性についても渡されます。

同じように、順番にこのような操作が繰り返されます。
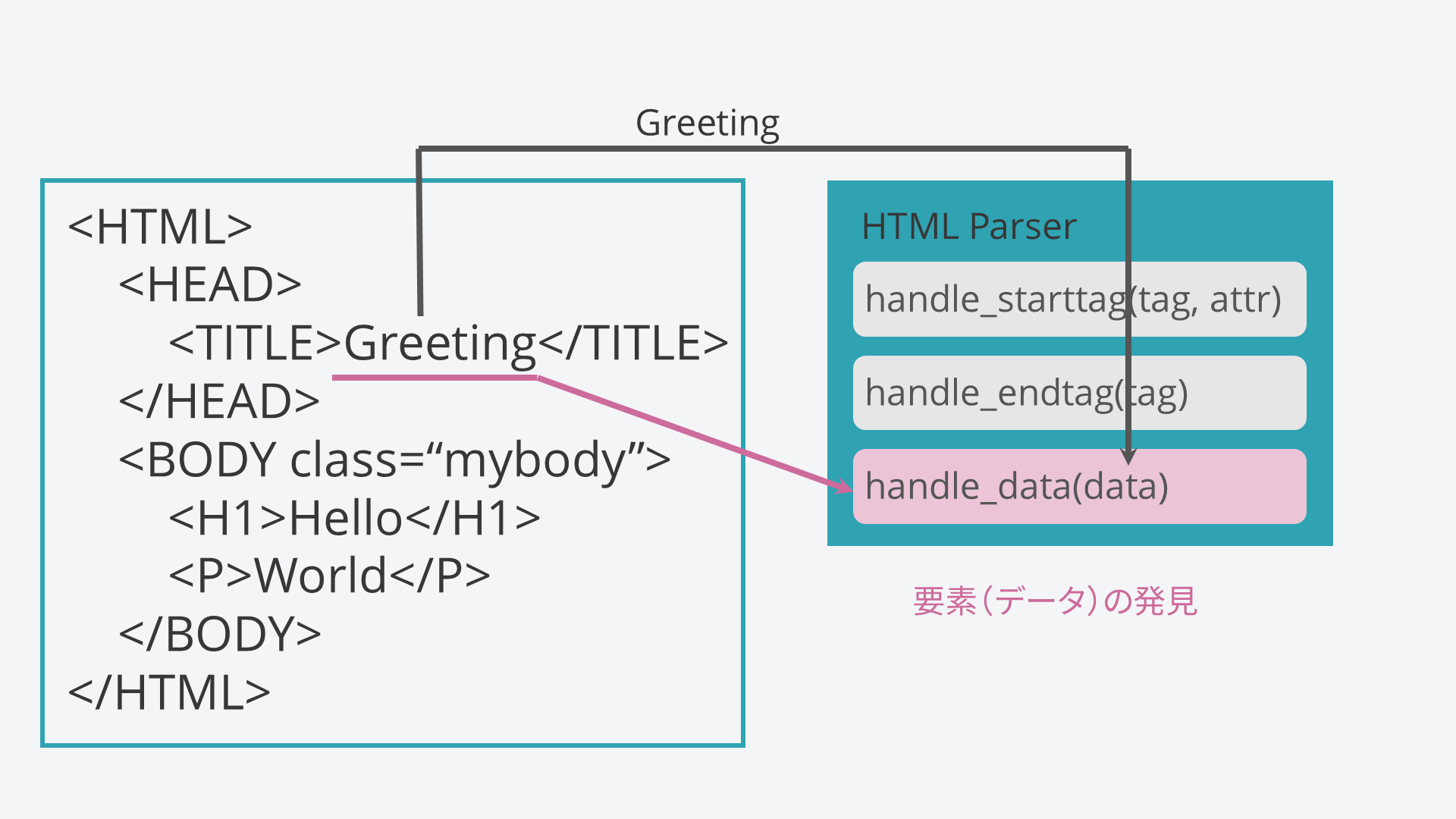
handle_dataメソッドはこのように要素に出会ったときに必ず呼び出されます。
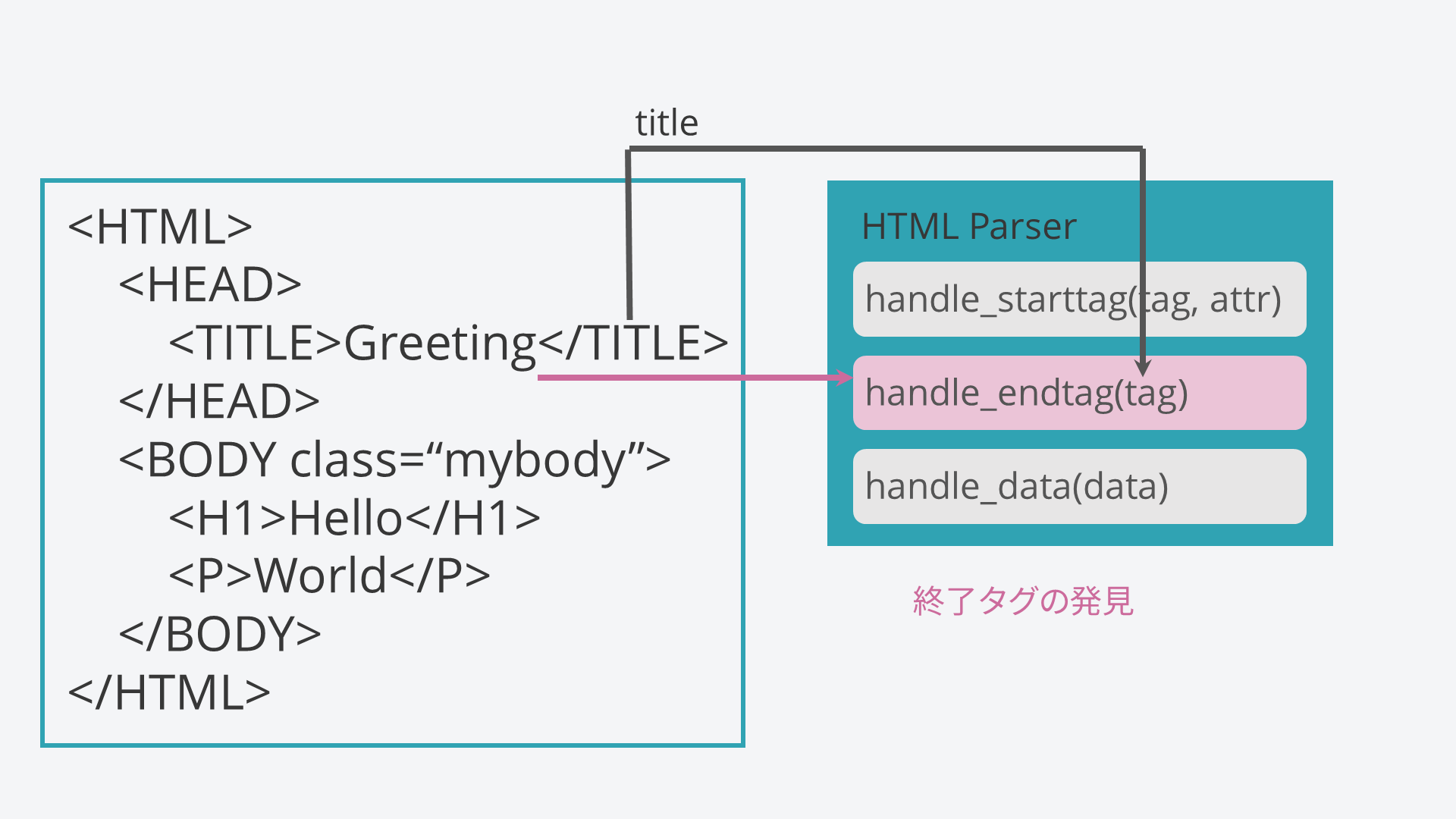
handle_endtagメソッドは終了タグに出会ったときに呼び出されます。このときはattr引数は必要ない(なぜなら開始タグにそれが書かれているから)ので用意されていないことに注意してください。
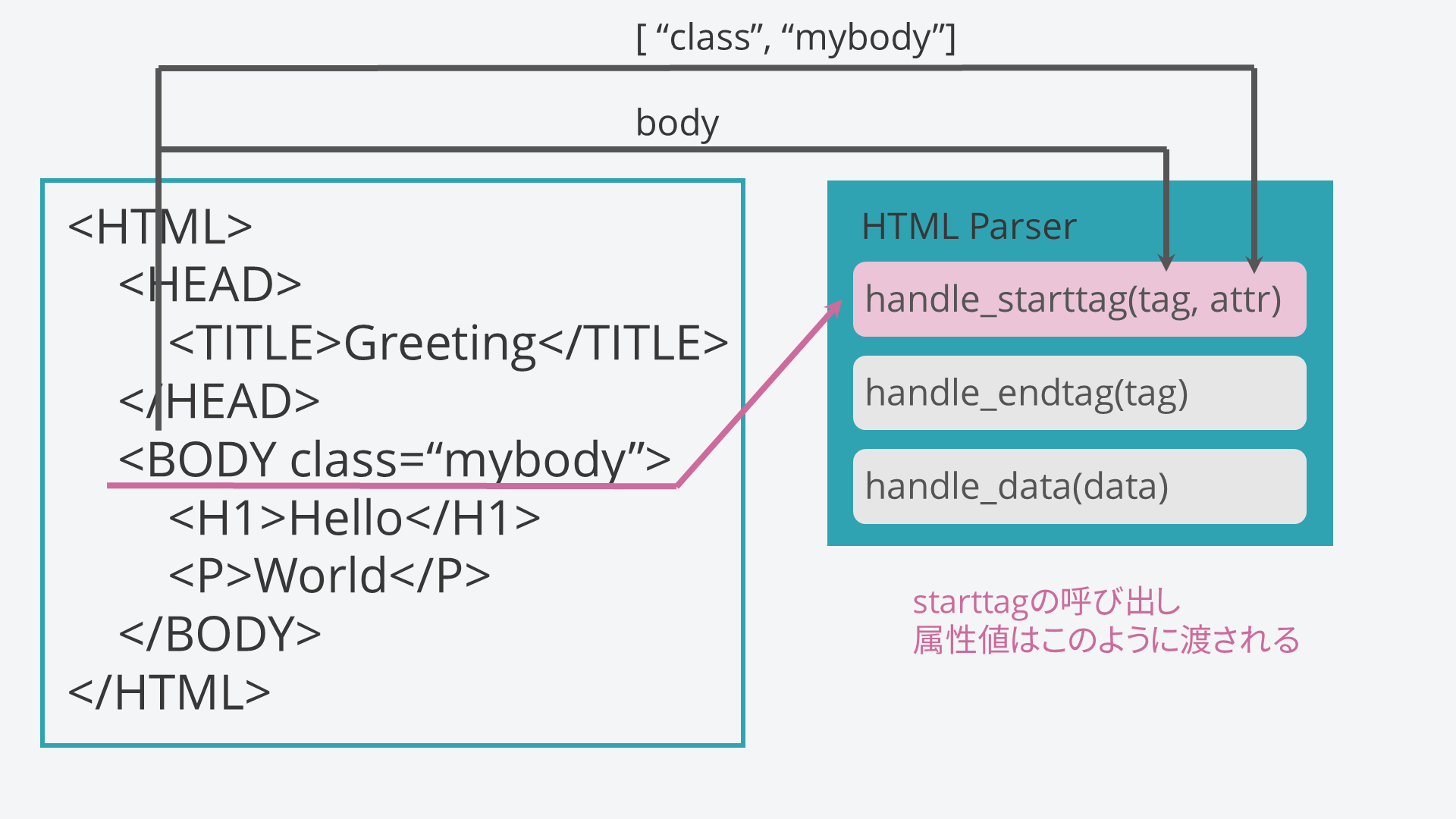
属性があるときは空リストではなく、このように属性名,属性値,属性名,属性値,...となるようなリストとして渡されます。
我々は何をすればいいのか
HTMLParserの挙動がわかったところで、早速このパーサーを使ってスクレイピングをしてみましょう。(継承、オーバーライドが分かっている前提で説明します。)
handle_starttagメソッドは開始タグがあったときに呼ばれますから、そのタグの中にこれから入っていくことを覚えておくための処理を書くことができます。例えば、
<p>
<b>hutomoji</b>
</p>
このように太文字になっている部分だけを取り出したいときに、handle_starttagメソッド中に
def handle_starttag(self, tag, attr):
if tag == "p":
self.p = True
と書いてやることで、今<p>の後にいますよということを覚えておくことができます。
def handle_starttag(self, tag, attr):
if tag == "p":
self.p = True
if self.p and tag == "b":
self.pb = True
さらに、こう加えると、pタグの中のbを発見したときにself.pbがTrueになります。このような状態で要素を読み込みましょう。
def handle_data(self, data):
if self.pb:
self.pb_data = data
こうすることで、目標のデータを取得することができました。
めでたしめでたし、ではなくて、
def handle_end(self, tag):
if self.pb and tag == "b":
self.pb = False
if self.p and tag == "p":
self.p = False
としてあげることで、タグから抜けたときにちゃんと抜けているよということを覚えさせてあげることが必要です。そうでないと、self.pbフラグがこの後ずっとTrueになり、HTMLファイルの終端までずっとself.dataを書き換えられてしまいます。
実際に作るときのコツとしては、まずスクレイピングしたいページのHTMLコードを眺めながらどうやって目標のデータのところまで侵入していけばいいのかを考えます。
注意として、例のように同じような構造がページにいくつかあることがあります。
<h1 class="a1">Article1</h1>
<p>It's a fine day</p>
<h1 class="a2">Article2</h1>
<p>People open the window</p>
このときは、属性名などを使ってうまく判別するかカウンタを使って同じ構造が何回出現したときに必要なデータが出てくるかを判別すればよいです。
他にもいろいろと工夫できるところがあると思うので、いろいろ試して面白いやり方があったら教えてください。
少しばかりですが機能がまだまだありますので公式docを参照してみください。
https://docs.python.jp/3.6/library/html.parser.html