概要
スマートフォンアプリでFirebase+GoogleAnalyticsを活用しているユーザーが対象です。
BigQueryからS3にデータを移行し、Athenaで検索します。
BigQueryではなくAWSで分析をおこないたいユーザーに向けたETL基盤の設計例の紹介です。
当記事ではTerraformを用いた例を紹介しています。
前提条件
すでにFirebase向けGoogleAnalyticsのデータがBigQueryで検索できる状態とします。
以下のヘルプページを参照してください。
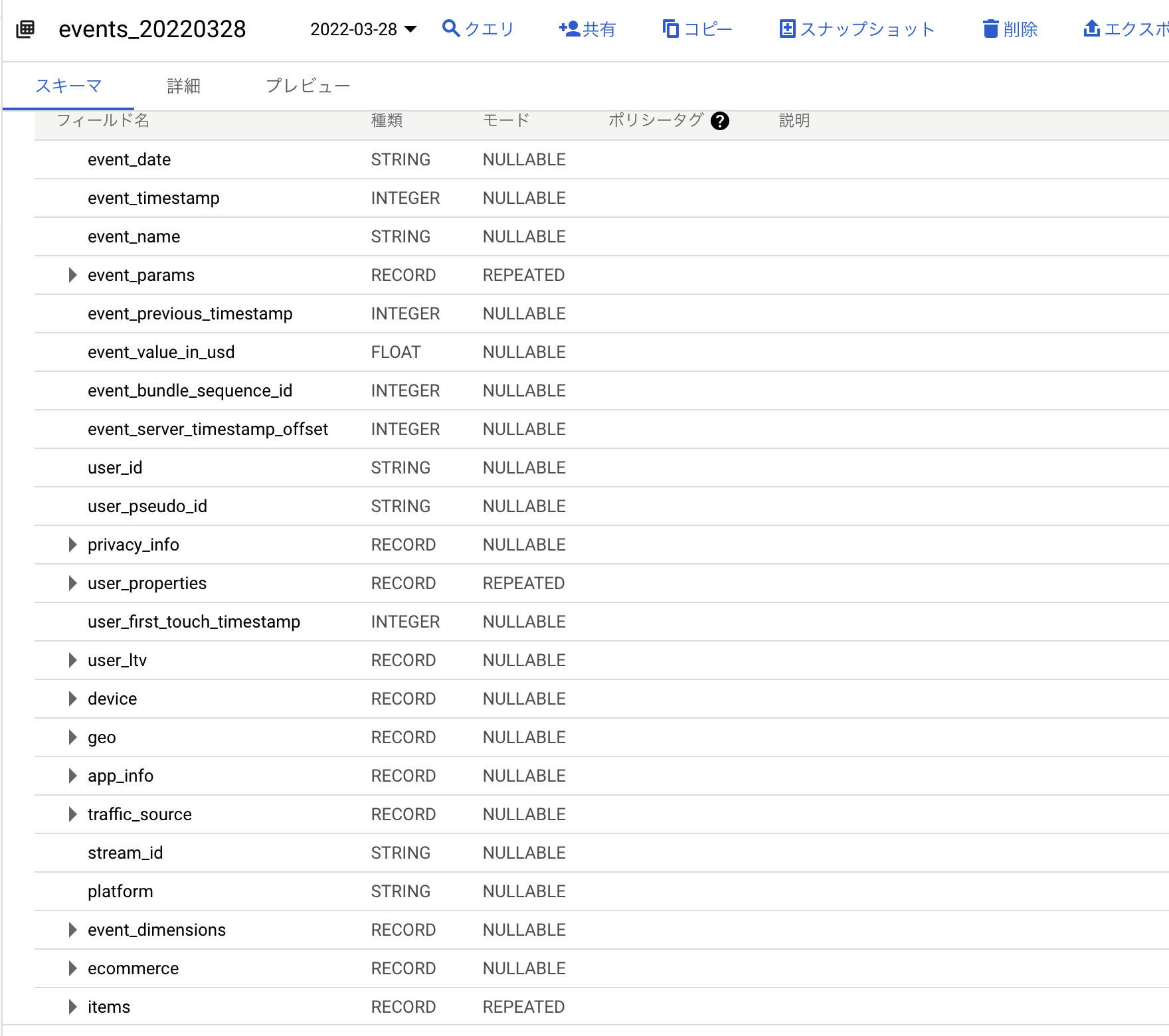
また、テーブルのスキーマは以下の通りになっているはずです。
合わせてご確認ください。
GCPサービスアカウントの作成
GCPでBigQueryの権限を付与したサービスアカウントを作成します。
(もしくは既存のサービスアカウントを選択します。)
サービスアカウントのキーを、AWSのSecretsManagerに格納します。
格納までの流れはクラスメソッド様の以下の記事を参考にさせていただきました。ありがとうございます。
Google BigQuery Connector for AWS Glue
AWS Glueを用います。
AWS Glueのマーケットプレイスより、Google BigQuery Connector for AWS Glueをサブスクライブします。
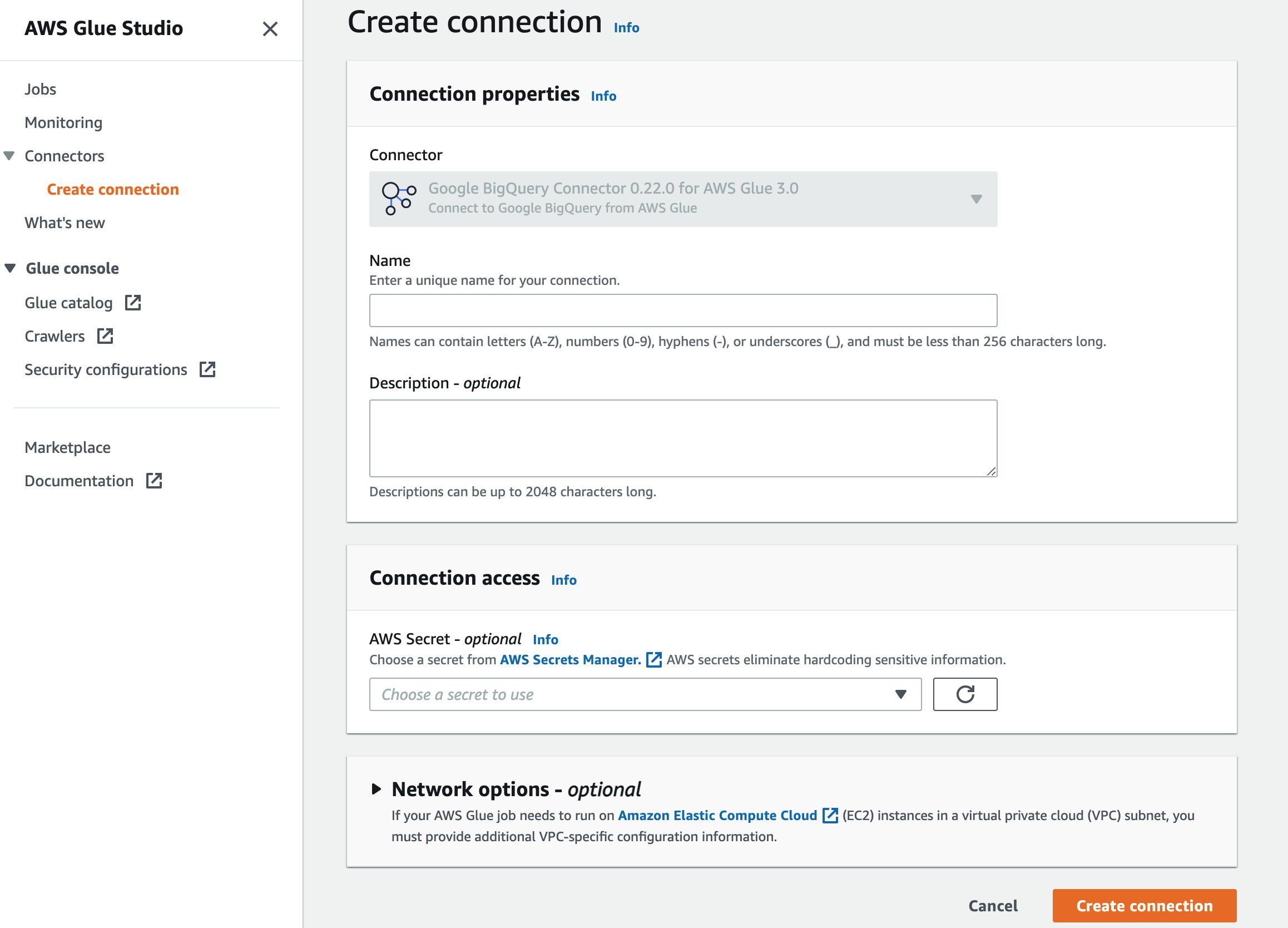
サブスクライブ完了後、Glueでコネクションを作成してください。
今回はGoogle BigQuery Connector 0.22.0 for AWS Glue 3.0を選択しています。
Connection accessの場所に、GCPのキーを格納したSecretsManagerを選択します。
(前述のクラスメソッド様の記事を参考にします。)
ジョブの作成
続いてGlueのジョブを作成します。
以下のスクリプトを配置します。
import sys
import boto3
from datetime import datetime, timedelta
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
argKeys = ['JOB_NAME']
args = getResolvedOptions(sys.argv, argKeys)
(jobName) = [args[k] for k in argKeys]
s3 = boto3.client("s3", region_name="ap-northeast-1")
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(jobName, args)
target = datetime.now() + timedelta(days=-2)
date = [target.year, target.month, target.day]
projectId = "{GCPのプロジェクトID}"
tableName = "{BigQuery側のデータセット名}.events_{0[0]:0>4}{0[1]:0>2}{0[2]:0>2}".format(date)
bucket_root = "{移行先のS3バケット名}"
prefix = "bigquery/firebase_analytics/year={0[0]:0>4}/month={0[1]:0>2}/day={0[2]:0>2}".format(date)
s3Path = "s3://" + bucket_root + "/" + prefix
bigQueryDynamicFrame = (
glueContext.create_dynamic_frame.from_options(
connection_type="marketplace.spark",
connection_options={
"parentProject": projectId,
"table": tableName,
"connectionName": "BigQueryConnector",
},
)
)
s3DynamicFrame = glueContext.write_dynamic_frame.from_options(
frame=bigQueryDynamicFrame,
connection_type="s3",
format="glueparquet",
connection_options={
"path": s3Path,
},
)
job.commit()
以下の記述に注目してください。
target = datetime.now() + timedelta(days=-2)
Firebase向けGoogleAnalyticsのテーブルは、events_{YYYYMMDD}のテーブルを日次で作成します。
そのため、Glueのジョブも日次で実行し、events_20220328, events_20220329, events_20220330...のように毎日順番にインポートしていきます。
BigQuery側は、日によってテーブルが作成される時間帯がバラバラになっていますので、対象とする日付には注意が必要です。
BigQueryでまだ前日分のテーブルが作成されないままGlueを実行しないように注意してください。
なるべく早くS3に移行したい場合は、BigQuery側でテーブルが作成されたかどうかを確認し、確認をトリガーにジョブを実行する設計が考えられます。
ユースケースに沿った設計を検討ください。
当記事では、余裕を持って2日前の日付に対するテーブル(本日が2022/03/30であれば、events_20220328を対象とするといった具合。)とします。
Terraformの実装
それでは、配置するS3やGlueの構成をTerraformで構築しましょう。
S3
resource "aws_s3_bucket" "bucket" {
bucket = "{移行先のS3バケット名}"
}
resource "aws_s3_bucket_acl" "bucket" {
bucket = aws_s3_bucket.bucket.bucket
acl = "private"
}
Glue用IAMロール
AmazonEC2ContainerRegistryReadOnlyは、Glue3.0においてジョブをコンテナ活用しているために必要です。
resource "aws_iam_role" "glue_role" {
name = "AWSGlueServiceRole-bigquery"
assume_role_policy = data.aws_iam_policy_document.glue_assume_role.json
}
data "aws_iam_policy_document" "glue_assume_role" {
statement {
actions = ["sts:AssumeRole"]
principals {
identifiers = ["glue.amazonaws.com"]
type = "Service"
}
}
}
resource "aws_iam_role_policy_attachment" "glue_policy_1" {
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole"
role = aws_iam_role.glue_role.name
}
resource "aws_iam_role_policy_attachment" "glue_policy_2" {
policy_arn = "arn:aws:iam::aws:policy/AmazonS3FullAccess"
role = aws_iam_role.glue_role.name
}
resource "aws_iam_role_policy_attachment" "glue_policy_3" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly"
role = aws_iam_role.glue_role.name
}
resource "aws_iam_role_policy_attachment" "glue_policy_4" {
policy_arn = "arn:aws:iam::aws:policy/SecretsManagerReadWrite"
role = aws_iam_role.glue_role.name
}
ジョブ
connectionsは、前工程で自身で作成したコネクションの名称を記述します。
resource "aws_glue_job" "job" {
name = "{任意のジョブ名}"
role_arn = aws_iam_role.glue_role.arn
connections = ["BigQueryConnector"] // 自身で作成したコネクションの名称
command {
script_location = "s3://{ジョブスクリプトを配置しているバケット}/{任意のスクリプト名}.py"
python_version = 3
}
glue_version = "3.0"
default_arguments = {
"--class" = "GlueApp"
"--continuous-log-logGroup" = "/aws-glue/jobs/output"
"--enable-continuous-cloudwatch-log" = "true"
"--enable-continuous-log-filter" = "true"
"--enable-metrics" = "true"
"--job-language" = "python"
"--job-bookmark-option" = "job-bookmark-disable"
"--TempDir" = "s3://{任意のバケット}/"
}
number_of_workers = 10
worker_type = "G.1X"
}
resource "aws_glue_workflow" "workflow" {
name = "{任意のワークフロー名}"
}
resource "aws_glue_trigger" "trigger" {
name = "workflow_start"
schedule = "cron(0 17 * * ? *)" // 任意の時間
type = "SCHEDULED"
workflow_name = aws_glue_workflow.workflow.name
actions {
job_name = aws_glue_job.job.name
}
}
Glueカタログ
ジョブの中で、以下によりS3のパスを指定しています。
bucket_root = "{移行先のS3バケット名}"
prefix = "bigquery/firebase_analytics/year={0[0]:0>4}/month={0[1]:0>2}/day={0[2]:0>2}".format(date)
s3Path = "s3://" + bucket_root + "/" + prefix
year, month, dayがそのままパーティションになるように射影を定義します。
resource "aws_glue_catalog_database" "database" {
name = "bigquery"
}
resource "aws_glue_catalog_table" "catalog" {
database_name = aws_glue_catalog_database.database.name
name = "firebase_analytics"
parameters = {
classification = "parquet"
"projection.enabled" = true
"projection.year.type" = "integer"
"projection.year.digits" = "4"
"projection.year.interval" = "1"
"projection.year.range" = "2022,2099"
"projection.month.type" = "enum"
"projection.month.values" = "01,02,03,04,05,06,07,08,09,10,11,12"
"projection.day.type" = "enum"
"projection.day.values" = "01,02,03,04,05,06,07,08,09,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31"
"storage.location.template" = "s3://${aws_s3_bucket.bucket.bucket}/bigquery/firebase_analytics/year=${"$"}{year}/month=${"$"}{month}/day=${"$"}{day}"
}
partition_keys {
name = "year"
type = "string"
}
partition_keys {
name = "month"
type = "string"
}
partition_keys {
name = "day"
type = "string"
}
storage_descriptor {
location = "s3://${aws_s3_bucket.bucket.bucket}/bigquery/firebase_analytics/"
input_format = "org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat"
output_format = "org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat"
ser_de_info {
name = "analytics_events"
serialization_library = "org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe"
parameters = {
"serialization.format" = 1
}
}
columns {
name = "event_date"
type = "string"
}
columns {
name = "event_timestamp"
type = "bigint"
}
columns {
name = "event_name"
type = "string"
}
columns {
name = "event_params"
type = "array<struct<key:string,value:struct<string_value:string,int_value:bigint,float_value:float,double_value:double>>>"
}
columns {
name = "event_previous_timestamp"
type = "bigint"
}
columns {
name = "event_value_in_usd"
type = "float"
}
columns {
name = "event_bundle_sequence_id"
type = "bigint"
}
columns {
name = "event_server_timestamp_offset"
type = "bigint"
}
columns {
name = "user_id"
type = "string"
}
columns {
name = "user_pseudo_id"
type = "string"
}
columns {
name = "privacy_info"
type = "struct<analytics_storage:string,ads_storage:string,uses_transient_token:string>"
}
columns {
name = "user_properties"
type = "array<struct<key:string,value:struct<string_value:string,int_value:bigint,float_value:float,double_value:double,set_timestamp_micros:bigint>>>"
}
columns {
name = "user_first_touch_timestamp"
type = "bigint"
}
columns {
name = "user_ltv"
type = "struct<revenue:float,currency:string>"
}
columns {
name = "device"
type = "struct<category:string,mobile_brand_name:string,mobile_model_name:string,mobile_marketing_name:string,mobile_os_hardware_model:string,operating_system:string,operating_system_version:string,vendor_id:string,advertising_id:string,language:string,is_limited_ad_tracking:string,time_zone_offset_seconds:bigint,browser:string,browser_version:string,web_info:struct<browser:string,browser_version:string,hostname:string>>"
}
columns {
name = "geo"
type = "struct<continent:string,country:string,region:string,city:string,sub_continent:string,metro:string>"
}
columns {
name = "app_info"
type = "struct<id:string,version:string,install_store:string,firebase_app_id:string,install_source:string>"
}
columns {
name = "traffic_source"
type = "struct<name:string,medium:string,source:string>"
}
columns {
name = "stream_id"
type = "string"
}
columns {
name = "platform"
type = "string"
}
columns {
name = "event_dimensions"
type = "struct<hostname:string>"
}
columns {
name = "ecommerce"
type = "struct<total_item_quantity:bigint,purchase_revenue_in_usd:float,purchase_revenue:float,refund_value_in_usd:float,refund_value:float,shipping_value_in_usd:float,shipping_value:float,tax_value_in_usd:float,tax_value:float,unique_items:bigint,transaction_id:string>"
}
columns {
name = "items"
type = "array<struct<item_id:string,item_name:string,item_brand:string,item_variant:string,item_category:string,item_category2:string,item_category3:string,item_category4:string,item_category5:string,price_in_usd:float,price:float,quantity:bigint,item_revenue_in_usd:float,item_revenue:float,item_refund_in_usd:float,item_refund:float,coupon:string,affiliation:string,location_id:string,item_list_id:string,item_list_name:string,item_list_index:string,promotion_id:string,promotion_name:string,creative_name:string,creative_slot:string>>"
}
}
}
スキーマは、当記事の前半でも紹介しましたが以下のページが参考になるかと思います。
以上