はじめに
過去に以下のような記事を書きました。
AWS Lambda で MeCab を動かす (2018年9月時点)
この記事で最後に
「Neologdも入れたかったけれども、Lambdaのtemp領域の制限でアウト。
(中略)
そうこう言っている間にLambdaのtemp領域の制限が一気に3GBくらいになってくれないかな。
と書いて終わりました。それから約2年。Lambda の temp 領域制限は変わりませんが、代わりに(?)Lambda から EFS にアクセスできるようになりました。これでようやく念願の NEologd を手軽に Lambda 上で動かせるようになりましたので、その方法をまとめます。
まぁ、ホントに EFS に MeCab と NEologd を突っ込むだけなので特別なことはしていません。
NEologdとは
正式にはmecab-ipadic-NEologdという名称で、多数のWeb上の言語資源から得た新語を追加することでカスタマイズした MeCab 用のシステム辞書です。
(詳しい説明は GitHub の README を参照ください。)
Lambda で外部のライブラリを利用する場合、そのライブラリを Lambda 関数と一緒に Zip で固めてアップロードするか、もしくは Lambda Layer を利用する必要があります。そして、Lambda 関数、Lambda Layer ともに容量に制限があり、基本的にはサイズの大きいライブラリを使うことは難しい状況でした。特に NEologd は新語辞書なので 1GB 以上の容量があり、到底 Lambda で取り回せるサイズではありませんでした。
このサイズ制限の問題を EFS を利用することによって回避することがこの記事の目的です。
なお、EFS を Lambda から利用する場合、Lambda は VPC 内に置く必要があります。なんとなく VPC が絡む時点で、以前ほど気軽ではなくなってしまう気がしますが、EFS を使う以上避けられないのです。
MeCab&NEologd を動かす
EFS を作成する
パフォーマンスモードやネットワークアクセス、ファイルシステムポリシーなど真面目にやると設定する項目はたくさんありますが、とりあえず MeCab と NEologd を動かすことが目的なので全てデフォルト設定で作成します。VPC もデフォルトのものをそのまま使います。
EFS のアクセスポイントを作成する
Lambda からアクセスするためのアクセスポイントを作ります。
所有者ユーザーID:1001、所有者グループID:1001、アクセス許可:7777、パス:/lambdaで作成します。ここもとりあえず最低限動かすことだけを考えた設定です。
ビルド用の EC2 を作成する
MeCab、NEologd をビルドするための EC2 を作成します。
基本的にここも特に特別な設定は不要でデフォルトのままで良いのですが、NEologd のビルドが結構メモリを食うのでインスタンスタイプはやや大きめを指定します。(私は t2.large を使いました。)先ほど作成した EFS をマウントするので VPC はやはりデフォルトのものを利用します。OS は Amazon Linux 2 を使います。
Python3.8 のインストール
Amazon Linux 2 に最初から入っているのは、Python2.7 なので、まず Python3.8 をインストールします。インストール方法は以下の記事を参考にしてください。ここで Amazon Linux 2 のアップデートも行います。
EC2(Amazon Linux 2)にPython 3.8, Pip 3.8をインストールする
EFS のマウント
先ほど作成した EFS をビルド用の EC2 にマウントします。EFS の IP はコンソールから確認できます。権限は一旦777で。
sudo mount -t nfs \
-o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 \
<EFSのIP アドレス>:/ /mnt
sudo chmod 777 /mnt
MeCab & IPA辞書 インストール
まず、MeCab, IPA辞書 のインストールに必要なプログラムをインストールしておきます。
sudo yum -y install gcc-c++ git patch
次に MeCab 本体を Google ドライブからダウンロードしてインストールします。--prefix=/mnt/lambda でインストール先に先ほどマウントした EFS を指定します。
なお、URL は古くなる可能性があるので、最新のダウンロード先は作者のサイトを確認してください。
cd ~
curl -L "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE" -o mecab-0.996.tar.gz
tar -zxvf mecab-0.996.tar.gz
cd mecab-0.996
sudo ./configure --prefix=/mnt/lambda --with-charset=utf8
sudo make
sudo make install
そして MeCab 標準で推奨されている IPA 辞書をダウンロードしてインストールします。先ほどと同様に==prefix=/mnt/lambdaで EFS をインストール先に指定します。NEologd だけ使う場合でも、NEologd のインストール後のテストに利用されるのでインストール必須のようです。
なお、こちらの URL も古くなる可能性があるので、MeCab 本体と同様に確認してください。
cd ~
curl -L "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM" -o mecab-ipadic-2.7.0-20070801.tar.gz
tar -zxvf mecab-ipadic-2.7.0-20070801.tar.gz
cd mecab-ipadic-2.7.0-20070801
sudo ./configure --prefix=/mnt/lambda --with-charset=utf8 --with-mecab-config=/mnt/lambda/bin/mecab-config
sudo make
sudo make install
後続の NEologd インストール時に MeCab の実行が必要なのであらかじめパスを通しておきます。
export PATH=$PATH:/mnt/lambda/bin
NEologd インストール
ここで本題の NEologd をインストールします。詳細なインストール方法については前述の GitHub を参照して頂きたいですが、ただ単にインストールするだけなら、下記の通りやることはいたって簡単です。
なお、インストール先は、オプション未指定の場合、先にインストールした MeCab のコンフィグファイルmecab-configに従って決まります。今回は未指定でも勝手に MeCab と同じパスにインストールされます。また、インストールオプションがあり、オプションによっては一部の辞書ファイルのインストールをスキップしてサイズを小さくできるようです。が、今回は細かいことは気にせず全部入りでインストールします。なにせインストール先は Elastic File System なので。
cd ~
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
cd mecab-ipadic-neologd
./bin/install-mecab-ipadic-neologd -n -a
mecab-python3 インストール
最後に Python から MeCab を呼び出すためのライブラリを同じく/mnt/lambda配下にインストールします。
(直接/mnt/lambdaにインストールしようとすると、Permission error になってしまうので、一旦ホームディレクトリにインストールしてから/mnt/lambdaにコピーしています。なんかもっとスマートな方法がある気がするのですが…。)
pip3 install mecab-python3 -t ~/temp
sudo cp -r ~/temp/* /mnt/lambda
これで MeCab と NEologd の準備は完了です。
Lambda の作成
MeCab と NEologd がインストールされた EFS を利用する Lambda 関数を作成します。
Lambda の設定
- 環境変数
-
PYTHONPATHに/mnt/lambdaを指定
-
- ランタイム
- Python3.8
- VPC
- EFS, EC2で利用したデフォルトのVPC
- デフォルトVPCに紐つく各AZのサブネット
- EC2作成時にウィザードから作られたセキュリティグループを指定
- ファイルシステム
- 上記で作成したファイルシステムとアクセスポイントを指定
- ローカルマウントパスには
/mnt/lambdaを指定
- ロール
- ポリシー
AmazonElasticFileSystemClientReadWriteAccesを追加
- ポリシー
なお、MeCab の処理はそこそこ時間とメモリを食うのでデフォルトの値だと足りません。必要量は対象とするテキストの長さによるので動かして調整してみてください。
ソースコード
本当に必要最低限の処理だけ書いて、とりあえず NEologd を参照して分かち書きが出来ていることを確認します。トリガは API Gateway の想定です。
import json
import MeCab
# IPA辞書を利用
ipadic_tagger = MeCab.Tagger('-O wakati -r /dev/null -d /mnt/lambda/lib/mecab/dic/ipadic')
# NEologdを利用
neologd_tagger = MeCab.Tagger('-O wakati -r /dev/null -d /mnt/lambda/lib/mecab/dic/mecab-ipadic-neologd')
def lambda_handler(event, context):
print(event['body'])
text = json.loads(event['body'])['text']
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*"
},
"body": json.dumps({
"ipadic": ipadic_tagger.parse(text),
"neologd": neologd_tagger.parse(text)
})
}
結果確認
Lambda 関数に API Gateway (HTTP API) のトリガを設定し、Postman からテスト実行します。
分かち書きの対象としたテキストは MeCab 実行結果の例で使われている以下の一文です。
8月3日に放送された「中居正広の金曜日のスマイルたちへ」(TBS系)で、1日たった5分でぽっこりおなかを解消するというダイエット方法を紹介。キンタロー。のダイエットにも密着。
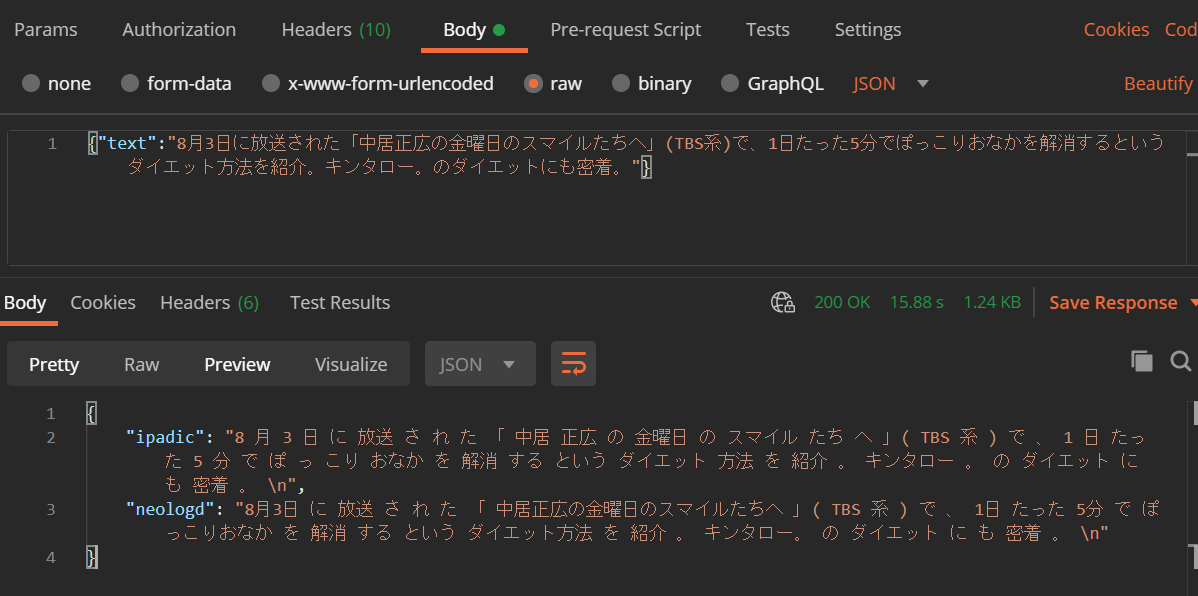
文章がスペースで区切られ、分かち書きがされていることがわかります。
IPA 辞書を使った場合と NEologd を使った場合とを比較すると、後者ではきちんと中居正広の金曜日のスマイルたちへが一語と認識されていることがわかります。そのほかにも「ぽっこりおなか」「ダイエット方法」なども NEologd の方では一語になっています。
ちなみに MeCab の出力形式は上記だけでなく、例えば品詞、活用形、読みなどをあわせて出力することもできます。詳細は公式サイトを参照してください。
ということで、無事に MeCab と NEologd を Lambda 上で動かすことができました。
CaboCha も動かす
さて、無事に MeCab と NEologd を使って分かち書きができるようになったのはイイのですが、問題はここから先これを使って何をするかです。
私の場合は、とあるアンケートの解答テキストが手元にたくさんあって、これをちょろっと分析してみようと思って、とりあえず分かち書きしてみたのですが、これだけだと結局何にもわかんないんですよね。せいぜいワードクラウドが作れるとかその程度で。
なかでも困るのは「XXXは適切だと思うか?」という問いに対して、「YYYYなので適切だと思う」「ZZZのため適切ではない」という2つの解答があった場合、これを単純に分かち書きするとどちらも「適切」という言葉が抽出されてしまうということです。「適切でないとは言い切れない」「適切ではないかと考える」みたいなさらに複雑なパターンもあり、これらを単純な分かち書きで処理するのは難しそうです。
こうした問題に対処できるかも、と考えて今回一緒に導入しようとしたのが日本語係り受け解析器の CaboCha です。
CaboCha/南瓜: Yet Another Japanese Dependency Structure Analyzer
これを使うことにより、文章を形態素に分けた後に単語間の修飾関係を解析することができるそうです。単純に MeCab で分かち書きだけするより、一歩先に進んだ分析ができるような気がします。
ということで MeCab, NEologd と同様に CaboCha も EFS にインストールして Lambda から使えるようにします。
CaboCha のインストール
詳しいインストール方法は前述の公式サイトに載っていますので参照してください。ここでは簡単にインストールする方法を紹介します。
まず前提となる CRF++ のダウンロードとインストールを行います。
cd ~
wget "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7QVR6VXJ5dWExSTQ" -O CRF++-0.58.tar.gz
tar zxfv CRF++-0.58.tar.gz
cd CRF++-0.58
./configure --prefix=/mnt/lambda
sudo make
sudo make install
次に CaboCha をダウンロードします。
(CaboCha のダウンロードだけやたらゴチャゴチャしてますが、色々試した結果これが一番スマートな方法でした。もっとスマートな方法があったら教えてください。)
cd ~
FILE_ID=0B4y35FiV1wh7SDd1Q1dUQkZQaUU
FILE_NAME=cabocha-0.69.tar.bz2
curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=${FILE_ID}" > /dev/null
CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=${FILE_ID}" -o ${FILE_NAME}
CaboCha インストール時にcrfpp.hとmecab.hが/usr/include配下に必要になるので、これを/mnt/lambda/includeからコピーします。
(なお、詳細は後述しますが、この部分が Lambda 実行時に一工夫必要になってしまう要因なんじゃないかという気がします…。)
sudo cp -r /mnt/lambda/include/* /usr/include
CaboCha 本体をインストールします。
cd ~
tar jxvf cabocha-0.69.tar.bz2
cd cabocha-0.69
./configure --prefix=/mnt/lambda --with-mecab-config=`which mecab-config` --with-charset=UTF8
sudo make
sudo make install
最後に CaboCha に同梱の Python バインディングをインストールします。mecab-python3 と同様にテンポラリのディレクトリにインストールしてから/mnt/lambdaにコピーします。
pip3 install ~/cabocha-0.69/python/ -t ~/temp2
sudo cp -r ~/temp2/* /mnt/lambda
Lambda 関数のソースコード更新
EFS に CaboCha のインストールが完了したので、後は Lambda のコードでimport CaboChaしてやれば良いだけ、と思いきやそのままやると以下のエラーで動きません。
[ERROR] Runtime.ImportModuleError: Unable to import module 'lambda_function': libcabocha.so.5: cannot open shared object file: No such file or directory
libcabocha.soライブラリが無いと言われています。実際には/mnt/lambda/lib配下にあるのですが。import MeCabしたときは、/mnt/lambda/lib配下のlibmecab.soが認識できている(と思われる)のに、なぜか CaboCha の場合は認識できないようです。
そこで、import CaboChaする前にctypes.cdll.LoadLibraryを使ってlibmecab.soライブラリを直接読み込みます。
import json
import os
import ctypes
path, directory, files = next(os.walk('/mnt/lambda/lib'))
for file in files:
if file.startswith('libcabocha.so'):
ctypes.cdll.LoadLibrary(os.path.join(path, file))
import CaboCha
# IPA辞書を利用
ipadic_parser = CaboCha.Parser("-d /mnt/lambda/lib/mecab/dic/ipadic")
# NEologdを利用
neologd_parser = CaboCha.Parser("-d /mnt/lambda/lib/mecab/dic/mecab-ipadic-neologd")
def lambda_handler(event, context):
print(event['body'])
text = json.loads(event['body'])['text']
return {
"statusCode": 200,
"headers": {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": "*"
},
"body": json.dumps({
"ipadic": ipadic_parser.parseToString(text),
"neologd": neologd_parser.parseToString(text)
})
}
結果確認
MeCab のときと同様に Postman から実行して結果を確認します。対象となるテキストも MeCab のときと同様のものを使います。(後半の「キンタロー。のダイエットにも密着。」は省略しましたが。)
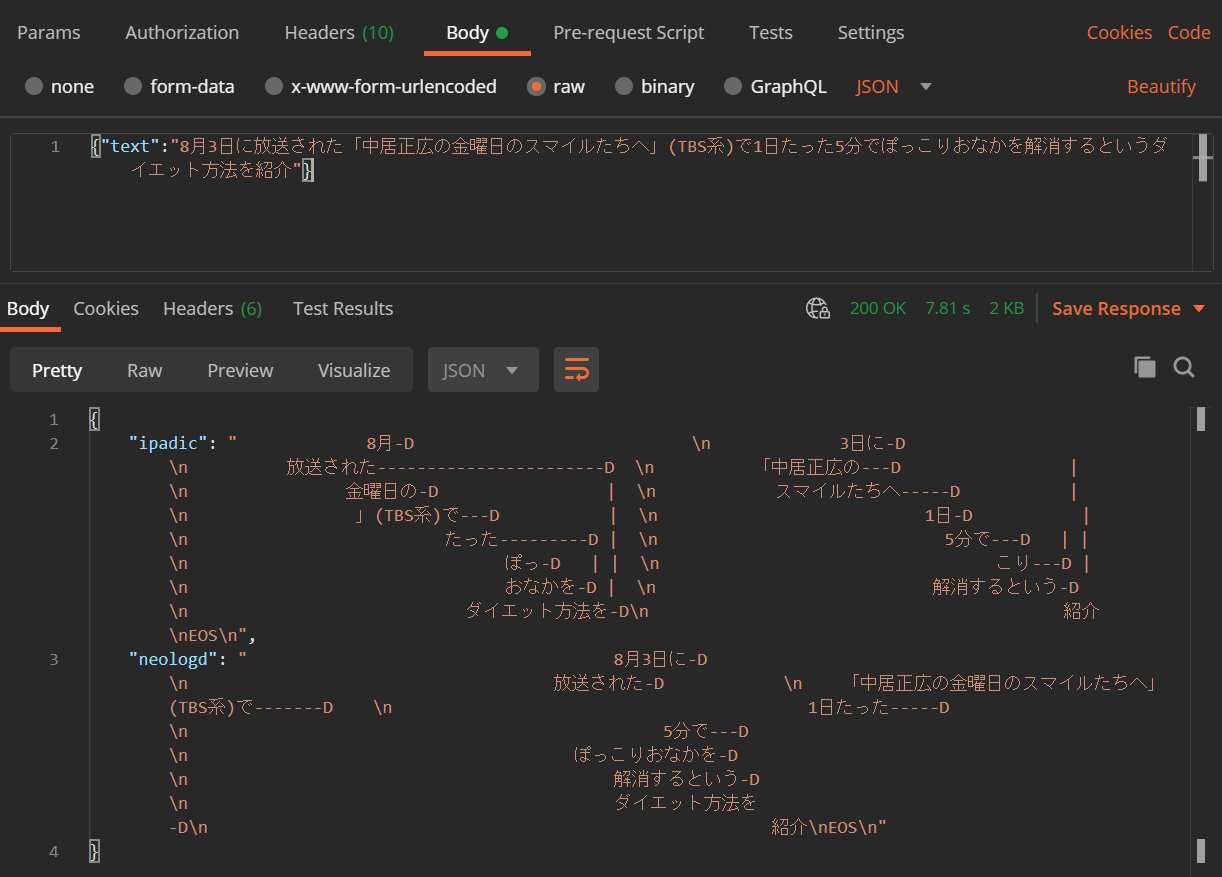
無事に実行できました。が、このままだとなんのこっちゃかわかりませんので、結果を整形します。
8月-D
3日に-D
放送された-----------------------D
「中居正広の---D |
金曜日の-D |
スマイルたちへ-----D |
」(TBS系)で---D |
1日-D |
たった---------D |
5分で---D | |
ぽっ-D | |
こり---D |
おなかを-D |
解消するという-D
ダイエット方法を-D
紹介
8月3日に-D
放送された-D
「中居正広の金曜日のスマイルたちへ」(TBS系)で-------D
1日たった-----D
5分で---D
ぽっこりおなかを-D
解消するという-D
ダイエット方法を-D
紹介
それぞれ IPA 辞書を使った場合と NEologd を使った場合というように辞書を指定して係り受け解析ができていることがわかります。前者は、形態素の段階で「ぽっこり」が一語として扱われていないので「ぽっ」が「こり」にかかっていることになっています(笑)
ちなみに CaboCha も MeCab 同様に出力モードがあり、係り受けの精度など、細かい分析をするための情報を出力することができます。こちらも詳細は公式サイトを参照してください。
ということで無事に CaboCha も Lambda 上で動かすことができました。
さいごに
Lambda with EFS で MeCab, NEologd & CaboCha を動かす一例でした。前回似たような記事を書いたからという理由だけで、特に深く考えて EFS に NEologd を入れたわけではありませんでした。が、こうした辞書データは頻繁に更新が入るため、EFS で外付けにしておくことで本体の Lambda 関数とは別に更新がかけられて便利かもしれません。Lambda with EFS の有効な使い道の一つのパターンなのかもな、と思いました。
とはいえ、Lambda の temp 領域サイズアップもいまだに期待しています。よろしくお願いします。
参考記事
https://qiita.com/hitomatagi/items/e63dd8c4b879de156628
https://qiita.com/osyou84/items/4e2f686d82bf9e1166e8
https://qiita.com/ayuchiy/items/c3f314889154c4efa71e