サンプルデータを使って、デシル分析とRFM分析をしてみました。
目次
1. 私の環境について
2. サンプルデータのダウンロード
3. データタイプを指定しデータの状態を確認
4. 統計量の確認
5. 集計期間を指定
6. デシル分析
7. RFM分析
8. 振り返り
1. 私の環境について
・python3
・windows10
・Chrome
・Jupiter anaconda
2. サンプルデータのダウンロード
下記から架空のECのデータをダウンロードします。(Kaggle)
https://www.kaggle.com/vijayuv/onlineretail
3. データタイプを指定しデータの状態を確認
データ型を指定します。
また、df.info()を使ってデータの状態を確認します。
import pandas as pd
dtypes = {'InvoiceNo':'str', 'StockCode': 'str', 'Description': 'str', 'Quantity': 'int', 'InvoiceDate': 'datetime64', 'UnitPrice': 'float', 'CustomerID': 'str', 'Country': 'str'}
retail_data = pd.read_csv('./OnlineRetail.csv', dtype=dtypes, engine='python')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 541909 entries, 0 to 541908
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 InvoiceNo 541909 non-null object
1 StockCode 541909 non-null object
2 Description 540455 non-null object
3 Quantity 541909 non-null int64
4 InvoiceDate 541909 non-null datetime64[ns]
5 UnitPrice 541909 non-null float64
6 CustomerID 406829 non-null object
7 Country 541909 non-null object
dtypes: datetime64[ns](1), float64(1), int64(1), object(5)
memory usage: 33.1+ MB
全部で541909レコードあります。カラムは8。
列はそれぞれ
・InvoiceNo:レシート番号
・StockCode:商品コード
・Description:商品説明
・Quantity:購入量
・InvoiceDate:購入日時
・UnitPrice:単価
・CustomerID:顧客 ID
・Country:国
4. 統計量の確認
df.describe()を使って統計量を確認します。
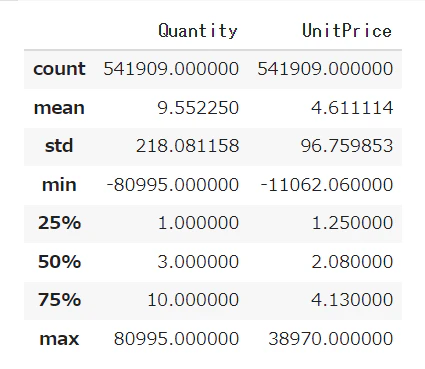
※マイナスがありますが、おそらく返金手続き等であるかと思われます。
5. 集計期間を指定
2011年10月末までを来店の集計期間にします。
※2011-12-09まで、データがあるようだったので
このとき、集計対象を0以上の値にしました。また、CustomerIDが入っているものを対象としています。
data = retail_data.query('Quantity >= 0 & UnitPrice >= 0').dropna(axis=0, subset=['CustomerID'])
6. デシル分析
デシル分析とは
顧客分類の1つで、顧客の購入金額などを元に上位から10等分して各グループの購入比率や売上構成比などを分析するものです。
その比率によって売上げに貢献している顧客を見つけ、販促活動の費用対効果を改善したり、また売上構造分析として活用することで、自社課題の発見に繋げることができる、とのこと。
(「デシル」の語源はラテン語で、「10等分」という意味。)
総額(数量×単価)カラムを作成しておきます。
data['TotalPrice'] = data['Quantity'] * data['UnitPrice']
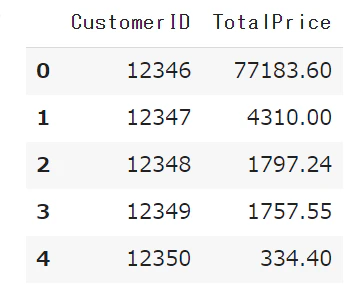
できたデータの確認
decil_data = data[['CustomerID', 'TotalPrice']].groupby('CustomerID').sum().reset_index()
decil_data.head()
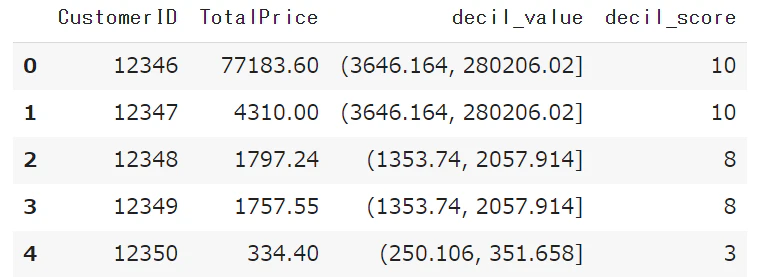
データを10等分します。データをn等分するときは
qcutが便利です。
decil_scoreとして10等分のデータへラベルをつけました。
decil_data['decil_value'] = pd.qcut(decil_data['TotalPrice'], 10)
decil_data['decil_score'] = pd.qcut(decil_data['TotalPrice'], 10, labels=['1','2','3','4','5','6','7','8','9','10'])
decil_data.head()
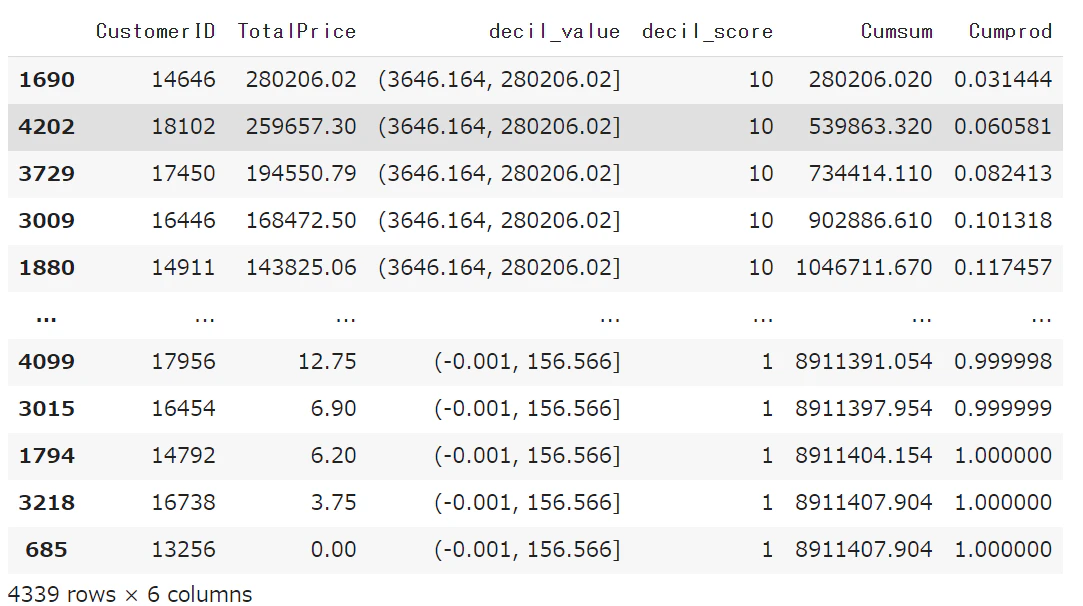
# 降順に並び替えて累積和・累積比率を求める
decil_data = decil_data.sort_values('TotalPrice', ascending=False)
decil_data['Cumsum'] = decil_data['TotalPrice'].cumsum()
decil_data['Cumprod'] = decil_data['Cumsum'] / decil_data['Cumsum'].max()
decil_data
各階層の売り上げが占める割合を確認
decil_data[['decil_score', 'Cumprod']].groupby('decil_score').max().reset_index().sort_values('decil_score', ascending=False)

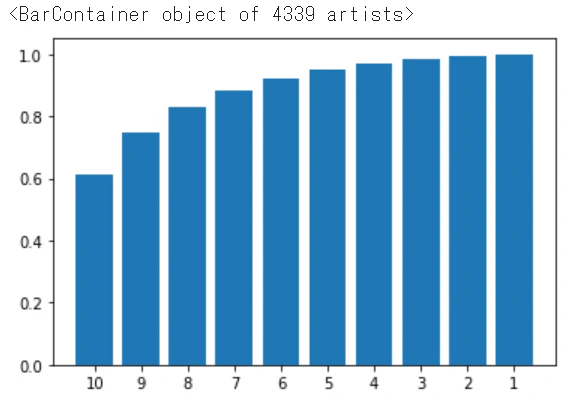
decil_score「10」で全体の61%を占めている。→ 購入総額の上位10%の顧客で全体売上の61%
decil_score「9」で全体の75%を占めている。→ 購入総額の上位20%の顧客で全体売上の75%
decil_score「8」で全体の83%を占めている。→ 購入総額の上位30%の顧客で全体売上の83%
グラフにして状態を確認
7. RFM分析
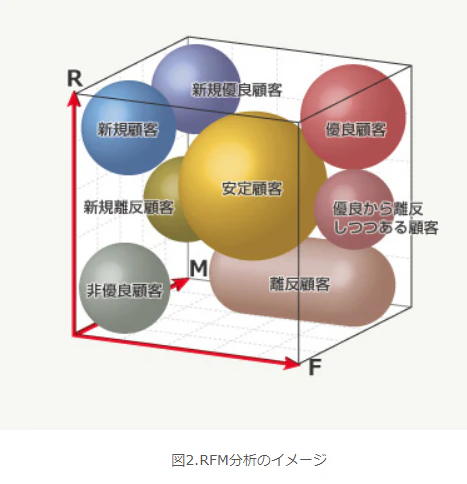
RFM分析とは
RFM分析は
・Recency(最近の購入日)
最終購入日が近い顧客のほうが、何年も前に購入した顧客より良い顧客だと考えます。
・Frequency(来店頻度)
購入頻度が高い顧客ほど良い顧客だと考えます。
商材にもよりますが、この値が高い顧客が多いなら常連が多く、低い顧客が多いなら商品やサービスに満足していない可能性があります。
・Monetary(購入額)
金額が大きいほど良い顧客だと考えます。
Recencyや Frequencyもそうなのですが、どれぐらいの期間内の購買行動を対象とするかは、商品の特性などによって調整します。
RFMは上記の頭文字をとったものであり、この 3 つの指標で顧客をランク付けする手法です。
顧客の属性を分析し、マーケティング施策等を行う際に用いられる分類の一つです。
使用するデータについて
RecencyにはInvoicedate、
FrequencyにはInvoiceNo、
MonetaryにはTotalpriceを使います。
今回はテストデータのため使用データの最新時刻を確認し、現在時刻をその付近に設定しておきます。
data['InvoiceDate'].max()
結果
Timestamp('2011-12-09 12:50:00')
最新の時刻は2011-12-09 12:50:00だったので、現在時刻NOWは2011-12-10に設定
import datetime as dt
NOW = dt.datetime(2011,12,10)
RFMを計算する
# RFMの計算
rfm = data.groupby("CustomerID").agg({"InvoiceDate": lambda date: (NOW - date.max()).days, #一番最近訪れた日時 R
"InvoiceNo": lambda num: num.nunique(), #何回order番号が出現したか F
"TotalPrice": lambda price: price.sum()}).reset_index() #購入の合計金額 M
rfm.tail()
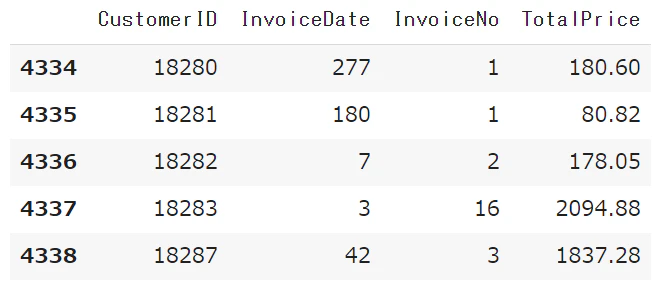
RFMスコアをデータに追加
今回は四等分に分割(本当のデータでは単純に4分割するべきではなく、実際の商材に応じて該当するスコアに当たる数値を微調整する必要がある)
# 扱いにくかったので数値型に
rfm['InvoiceDate'] = rfm['InvoiceDate'].astype(int)
rfm['InvoiceNo'] = rfm['InvoiceNo'].astype(int)
rfm['TotalPrice'] = rfm['TotalPrice'].astype(int)
rfm['R_score'] = pd.qcut(rfm['InvoiceDate'], 4, labels=['4','3','2','1']).astype(int)
rfm['F_score'] = pd.qcut(rfm['InvoiceNo'].rank(method='first'), 4, labels=['1','2','3','4']).astype(int)
rfm['M_score'] = pd.qcut(rfm['TotalPrice'], 4, labels=['1','2','3','4']).astype(int)
rfm
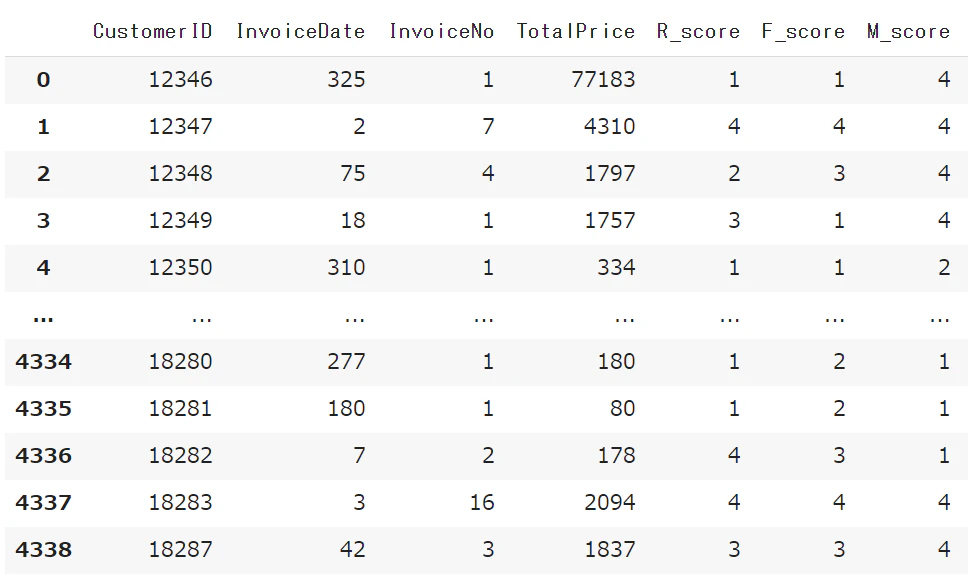
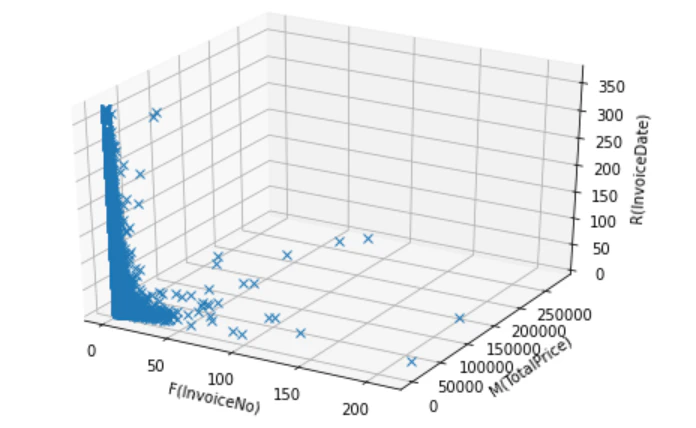
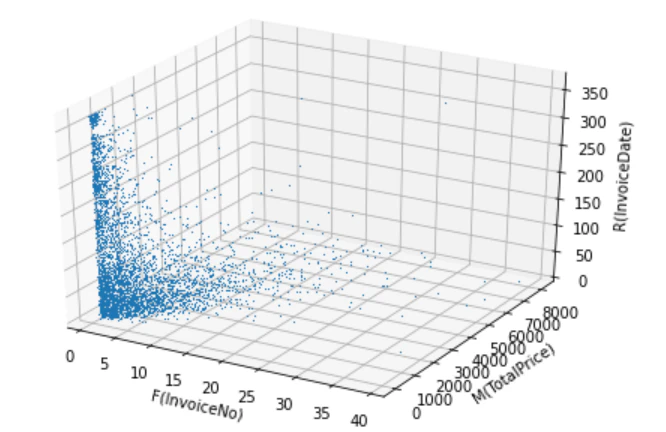
3Dのグラフで値の分布を確認
from mpl_toolkits.mplot3d import Axes3D
# グラフの枠を作成
fig = plt.figure()
ax = Axes3D(fig)
# X,Y,Z軸にラベルを設定
ax.set_xlabel("F(InvoiceNo)")
ax.set_ylabel("M(TotalPrice)")
ax.set_zlabel("R(InvoiceDate)")
# .plotで描画
plt.figure(figsize=(70, 70))
ax.plot(rfm['InvoiceNo'],rfm['TotalPrice'],rfm['InvoiceDate'],marker="x",ms=0.5,linestyle='None')
下記ページ掲載のグラフ
https://www.albert2005.co.jp/knowledge/marketing/customer_product_analysis/decyl_rfm
参考にすると非優良顧客と新規顧客が多いように見える。
少し外れ値を考慮してみたいと思う。
q_TotalPrice = rfm.TotalPrice.quantile(0.97)
q_TotalPrice
結果
8203.219999999976
ex_rfm = rfm.query('TotalPrice < @q_TotalPrice')
# グラフの枠を作成
fig = plt.figure()
ax = Axes3D(fig)
# X,Y,Z軸にラベルを設定
ax.set_xlabel("F(InvoiceNo)")
ax.set_ylabel("M(TotalPrice)")
ax.set_zlabel("R(InvoiceDate)")
# .plotで描画
plt.figure(figsize=(70, 70))
ax.plot(ex_rfm['InvoiceNo'],ex_rfm['TotalPrice'],ex_rfm['InvoiceDate'],marker="x", ms=0.5,linestyle='None')
多少点が見やすくなったように思う。
Rが大きいほど、過去日にサイトを訪問して購入を行ったユーザー。
→ n日以上来ていないユーザーは離反していると定義し、連絡をとってみるなどの施策を行えそう
Fが大きいほど、何回もサイトを訪問して購入をしているユーザーだが、10あたりを堺にあまりサイトに来なくなっているみたい。
→ このタイミングで対象ユーザーには感謝クーポンなどを配信するなどの施策を行えそう
Mが大きいほどサイトを訪問して購入をしてくれた金額が大きいユーザー。
→ このサイトでは~4000くらい購入してくれているユーザーが多いように見える。合わせ買いをしてもらえるような施策を行うことで、ユーザー全体の購入金額をUPしていきたい
8. 振り返り
テストデータを使ってデシル分析とRFM分析を行いました。
R,F,Mそれぞれ今回は4分割にしてスコアリングを行いましたが、実際のデータの場合は扱っている商品や規模によって最適な基準値が異なるため、微調整の方法を考える必要があります。