本記事ではDataDirectドライバーを使用してGoogle BigQueryからODBC接続でデータを取得します。
JupyterNotebook上でデータを取得し、Google BigQueryのチュートリアル同様にデータ処理を行いました。
※以下のチュートリアルではODBC接続ではなく、直接BigQueryからデータを取得する方法が書かれています。
https://cloud.google.com/bigquery/docs/visualize-jupyter?hl=ja
環境
OS:Windows10
ODBCドライバー:DataDirect 8.0 Google BigQuery
Pythonバージョン:3.8
DataDirect 8.0 Google BigQueryのインストール
以下URLより評価版をダウンロードできます。
https://www.progress.com/connectors/google-bigquery
ダウンロード出来たらインストールを行っていきます。
基本的に「Next」で次に進めましょう。
以下の画面のチェックボックスはWindows ODBC AdministratorにユーザーDSNを追加するかを聞かれています。
後から設定するのでチェックを入れておくといいかもしれません。
あとは「Done」でインストールが完了するのを待ちましょう。
Windows ODBC Administratorの設定
設定をする前Google Cloud Platfoamのサービスアカウントの作成とアカウントキーのJSONファイルが必要になります。
分からない場合は以下を参考にしてみてください。
https://www.magellanic-clouds.com/blocks/guide/create-gcp-service-account-key/
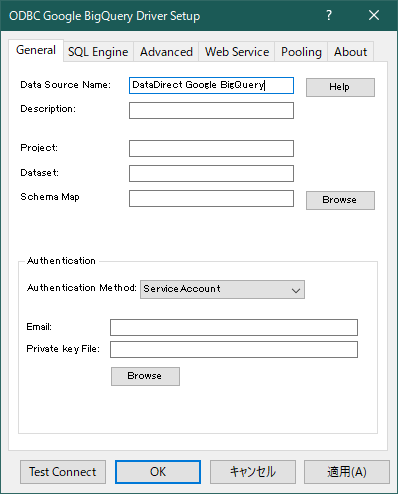
| 設定項目 | 入力する内容 |
|---|---|
| Data Source Name | 任意の名前 |
| Project | プロジェクトID |
| Authentication Method | Service Account |
| サービスアカウントのアドレス | |
| Private key File | JSONファイルのパス |
以上を設定し終わったら、「Test Connect」で接続を確認します。
JupyterNotebookでデータを可視化
本記事では前章で設定したプロジェクトのリソースにsamplesデータセットのnatalityテーブルをコピーして使用しています。
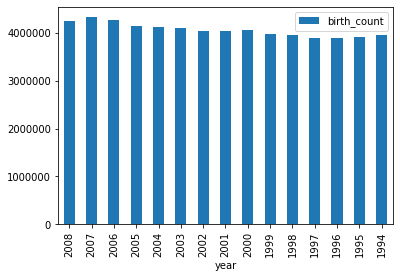
Google BigQueryのチュートリアルにある年別の出生数の合計を可視化してみます。
pyodbcのインストール
pip install pyodbc
import pyodbc
import pandas as pd
cnxn = pyodbc.connect('DSN=Google BigQuery',autocommit=True) #DSN=設定したDSN名
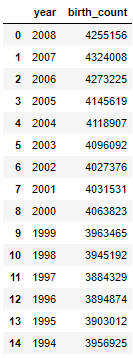
tableResult = pd.read_sql('SELECT source_year AS year,COUNT(is_male) AS birth_count \
FROM samples.natality GROUP BY year ORDER BY year DESC LIMIT 15', cnxn)
df = pd.DataFrame(tableResult)
df
%matplotlib inline
df1.plot(kind='bar', x='year', y='birth_count') #年別の出生数の合計の棒グラフ
まとめ
チュートリアルを実行したコードは以下で共有していますので参考にしてください。
Colaboratoryでは実行できないのでローカルにダウンロードしてJupyterNotebookで実行してみてください!
チュートリアル実行例
公式ではSimba社のODBCドライバーを提供していますが、Progress社の提供するDataDirectでも同じことが可能です。
DataDirectを使用するメリットは、国内企業であるアシスト社がDataDirectを扱っておりサポートを受けられることです。Simba社は日本に展開していないこともあり不安がある人、評価版を使用して気に入ったという人はDataDirectを検討してみてもいいかもしれませんね!
アシスト社のホームページ