前提条件
筆者はWindows内にWSLを利用しています。Linux系統を仮定して書いてます。
前条件は以下になります:
- mecab
- mecab-ipadic-neologd(以下、NEologd)
問題について
NEologdを使っていると、多くの単語を認識してくれて便利なのだが、たまに「余計なお世話」な単語の解析も出てくる。
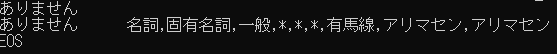
あり[動詞/連用形]+ませ[助動詞/未然形]+ん[助動詞]
と普通に解析されて欲しい時に、固有名詞が出現してしまう。
その他、単体では普通に解析されるが、前後の文章の影響で解析結果が変わってしまうこともある。
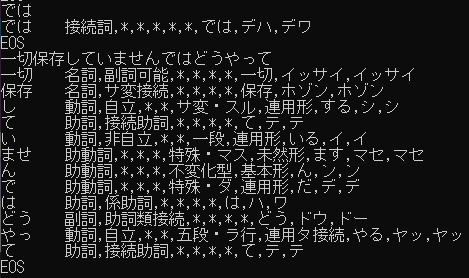
接続詞の「では」が文章だと分割されているのがお分かりいただけるだろうか。
この記事ではこの二つの問題に対処していく。
固有名詞
まず、固有名詞がNEologdで追加されたものなのかどうかを確認する。
通常のIPAdicの場合、

「有馬線」とは解析されないため、NEologdで追加されたと特定できる。
NEologdの固有名詞は、レポジトリの seed/neologd-proper-noun-ortho...csv.xz に記入されている。
ファイル内で「ありません」と検索すると…あった。
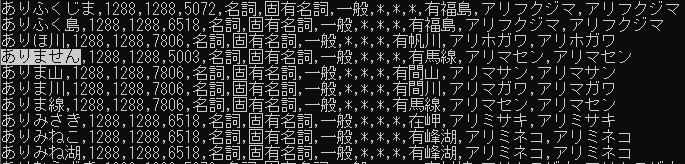
このCSVファイルの四番目の列にある数字がコストで、この値が低いほど出現頻度が高くなる。
すなわち、この単語を出現させたくなければ、
- 出現コストを上げる
- 登録を削除する
この二つの方法がある。
僕は「ありません」を使う機会はないと思うし、あったとしても漢字で記入すると思うので、削除することにした。
さて、このファイルを編集し終えたら、NEologdを再度インストールして作業は終了である。
レポジトリのルートディレクトリから ./bin/install-mecab-ipadic-neologd -n で作業終了。
確認してみると、

デフォルトと同じ結果になりました。
接続詞
先ほどと同様に、デフォルトの辞書でも同じ問題が発生するか確認する。
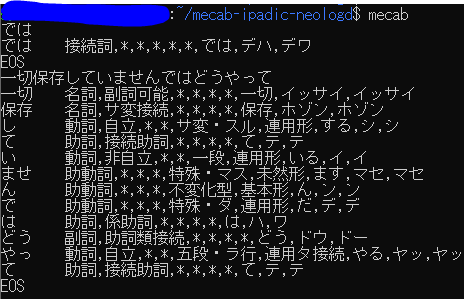
おっと、どうやらNEologdではなくデフォルト(IPAdic)辞書のほうの問題らしい。
IPAdicの辞書は、レポジトリの build/mecab-ipadic-2.7.0...tar.gz 内で圧縮されている。
接続詞はその中の Conjunction.csv というファイルになる。
早速開いてみる。(vimの場合、tar.gzフォルダをそのまま指定するとその中のファイルを選んで編集できます)

今回は「では」の出現頻度を上げたいので、出現コストを下げる。
試しに-4000で1262まで下げました。
注意: IPAdicの辞書に書き込む際、ファイルエンコーディングがeuc-jpに設定されているか確認してください
インストールの際、euc-jpをutf-8に一括変換する作業があって、その時にeuc-jpでない辞書は省かれます。
vimの場合、編集画面で:set fenc=euc-jpと入力してEnterでOK。
また、NEologdをインストール。
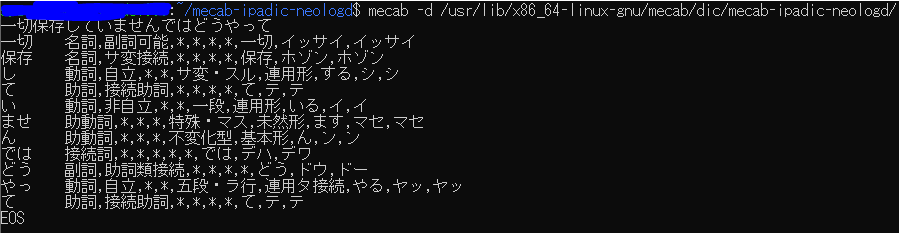
希望する解析結果が帰ってきました!
終わりに
この記事ではNEologdのシステム辞書の弄り方をメモしました。
エラーなどが発生した場合はコメントで報告ください。