概要
商品の説明文とタイトルをBertを使ってベクトル化して、商品間の類似性を表現できるかテストする。
準備
以下colab環境で実装します。
アカウント認証
from google.colab import auth
auth.authenticate_user()
tensorflowのバージョンの変更
今回使用するソースコードに合わせてcolabにインストールされているtensorflowのバージョンを変更します。
# tensorflowを1x系に戻します
!pip uninstall -y tensorflow
!pip install tensorflow==1.15.0
入力データとBertのソースコードを用意
# 必要なファイルを用意する
# こちらの記事を元にjumanppを使用できるようにコードを修正 https://dev.classmethod.jp/articles/bert-text-embedding/
!gsutil cp -r gs://${your_gcs_path}/bert ./
# 日本語wikiで学習したモデルを取得 http://nlp.ist.i.kyoto-u.ac.jp/index.php?BERT%E6%97%A5%E6%9C%AC%E8%AA%9EPretrained%E3%83%A2%E3%83%87%E3%83%AB#k1aa6ee3
!gsutil cp -r gs://${your_gcs_path}/Japanese_L-12_H-768_A-12_E-30_BPE ./
# 入力データを用意 (今回はamazonの電子書籍のタイトル+商品説明文)
!gsutil cp -r gs://${your_gcs_path}/inputdata ./
JUMAN++をインストール
# 以下を参照してjumanppをインストールする
# https://github.com/ku-nlp/jumanpp
!wget https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc3/jumanpp-2.0.0-rc3.tar.xz
!sudo apt install cmake
!tar xJvf jumanpp-2.0.0-rc3.tar.xz
%cd jumanpp-2.0.0-rc3/
!mkdir bld
%cd bld
!cmake ..
!sudo make install
環境変数を設定
%env MODEL=Japanese_L-12_H-768_A-12_E-30_BPE
%env OUTPUT=output
%env INPUT=inputdata
出力ディレクトリを作成
%cd ../
!mkdir output
Bertで商品をベクトル化
# item.txt : 商品タイトル + 商品説明
!python ./bert/extract_features.py --input_file=${INPUT}/item.txt --output_file=${OUTPUT}/output.jsonl --vocab_file=${MODEL}/vocab.txt --bert_config_file=${MODEL}/bert_config.json --init_checkpoint=${MODEL}/bert_model.ckpt --do_lower_case False --layers -2
商品間の距離行列を作成
Bertの出力結果からベクトル情報を取得
import json
import numpy as np
import pandas as pd
# 参照するレイヤーを指定する
TARGET_LAYER = -2
# 参照するトークンを指定する
SENTENCE_EMBEDDING_TOKEN = '[CLS]'
file ="./output/output.jsonl"
with open(file, 'r') as f:
output_jsons = f.readlines()
embedding_list = []
for output_json in output_jsons:
output = json.loads(output_json)
for feature in output['features']:
if feature['token'] != SENTENCE_EMBEDDING_TOKEN: continue
for layer in feature['layers']:
if layer['index'] != TARGET_LAYER: continue
embedding_list.append(layer['values'])
np.savetxt('output.tsv', embedding_list, delimiter='\t')
商品タイトル + 商品ベクトルの行列を作成
# 商品のベクトル
output = pd.read_csv("output.tsv", sep='\t',header=None)
# 商品のタイトル
title = pd.read_csv("inputdata/title.txt", sep='\t',header=None, names=["title"])
# 商品タイトルとベクトルを結合
res = pd.concat([title, output], axis=1)
# データを確認
res.head(3)
商品間の距離を計算
from scipy.spatial import distance
# ベクトルの作成
M = [a for a in res.iloc[:,2:769].values]
# 総当たりに類似度を計算(こちらを参照https://docs.scipy.org/doc/scipy/reference/generated/scipy.spatial.distance.cdist.html#scipy.spatial.distance.cdist)
dist_M = distance.cdist(M, M, metric='cosine')
商品間の距離行列を作成
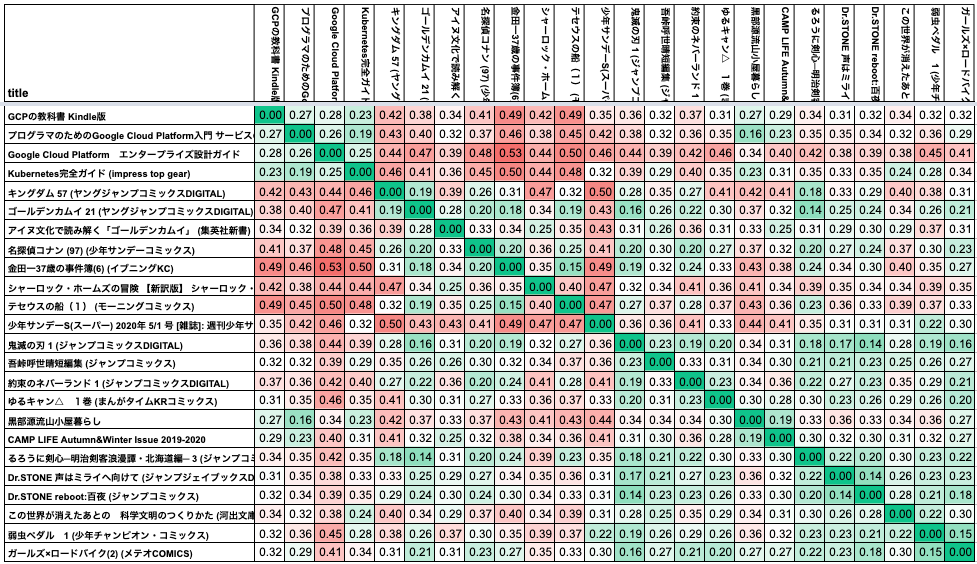
dist_matrix = pd.DataFrame(dist_M,columns=res['title'],index=res['title'])
ヒートマップで可視化
pythonで日本語の描画が難しそうだったのでスプレッドシートで作成しました。
専門書か漫画かなど大まかなジャンルには別れているようです。
日本語wikiで学習されたモデルを使っていて、商品データでモデルの学習をしていないため、十分にデータを集めて学習を行うことでより精度は上がりそうです。